
Большинство AI проектов в Web3 все еще застряли в одном и том же цикле.
Появляется новый нарратив, все ринутся в бой, награды взлетают на несколько недель, а затем волнение постепенно уходит, потому что сам продукт никогда не становится сильнее хайпа вокруг него.
Я видел это слишком много раз, особенно в AI. Каждый проект заявляет, что строит «будущее», но на самом деле большинство все еще полагается на одни и те же переработанные системы и инфраструктуру.
Вот почему я изначально смотрел на OpenLedger с большим скептицизмом.
Я предполагал, что «Специализированные модели» - это просто еще одно отполированное модное слово Web3, созданное для того, чтобы прокатиться на волне нарратива. Но после того, как я потратил время на изучение архитектуры наборов данных и Датасетов OpenLedger, я понял, что проект пытается решить нечто гораздо более глубокое, чем видимость или спекуляция.
Оно пытается решить вопрос собственности.
И это полностью меняет разговор вокруг децентрализованного ИИ.
Одно, что всегда беспокоило меня в сегодняшней экономике ИИ, это то, как невидимыми становятся участники. Огромные модели ИИ обучаются с использованием больших объемов данных, созданных людьми, но люди, предоставляющие эти данные, редко знают, имели ли их вклады вообще значение. Большую часть времени они также никогда не участвуют в созданной ценности.
OpenLedger подходит к этому иначе.
Вместо того, чтобы строить еще одну обобщенную модель, обученную на бесконечном интернет-шуме, сеть сосредотачивается на Специализированных моделях, основанных на кураторских наборах данных от децентрализованных участников. Но настоящая разница не только в «данных сообщества» — мы слышали эту фразу много раз раньше.
Важная часть - это атрибуция.
Я помню, как сидел поздно ночью с чаем, читая их заметки по инфраструктуре, и на секунду остановился, потому что идея звучит просто на поверхности, но экономически меняет все.
Финансовая модель ИИ может обучаться специально на финансовых наборах данных.
Медицинский помощник может улучшаться, используя информацию, ориентированную на медицину.
Модель разработчика может обучаться на репозиториях кода и технических обсуждениях, а не на неуместном интернет-мусоре.
Этот уровень специализации важнее, чем многие люди осознают.
Гонка ИИ больше не только о том, кто владеет самой большой моделью. Все больше она становится о том, кто владеет данными самого высокого качества.
И вот здесь OpenLedger начинает выглядеть стратегически интересно.
Их система Proof of Attribution пытается отслеживать, как наборы данных влияют на результаты модели, чтобы ценность могла возвращаться к участникам, а не исчезать в черном ящике. Эта часть выделяется для меня, потому что большинство систем ИИ сегодня не могут четко объяснить, откуда на самом деле берется их интеллект, как только начинается обучение.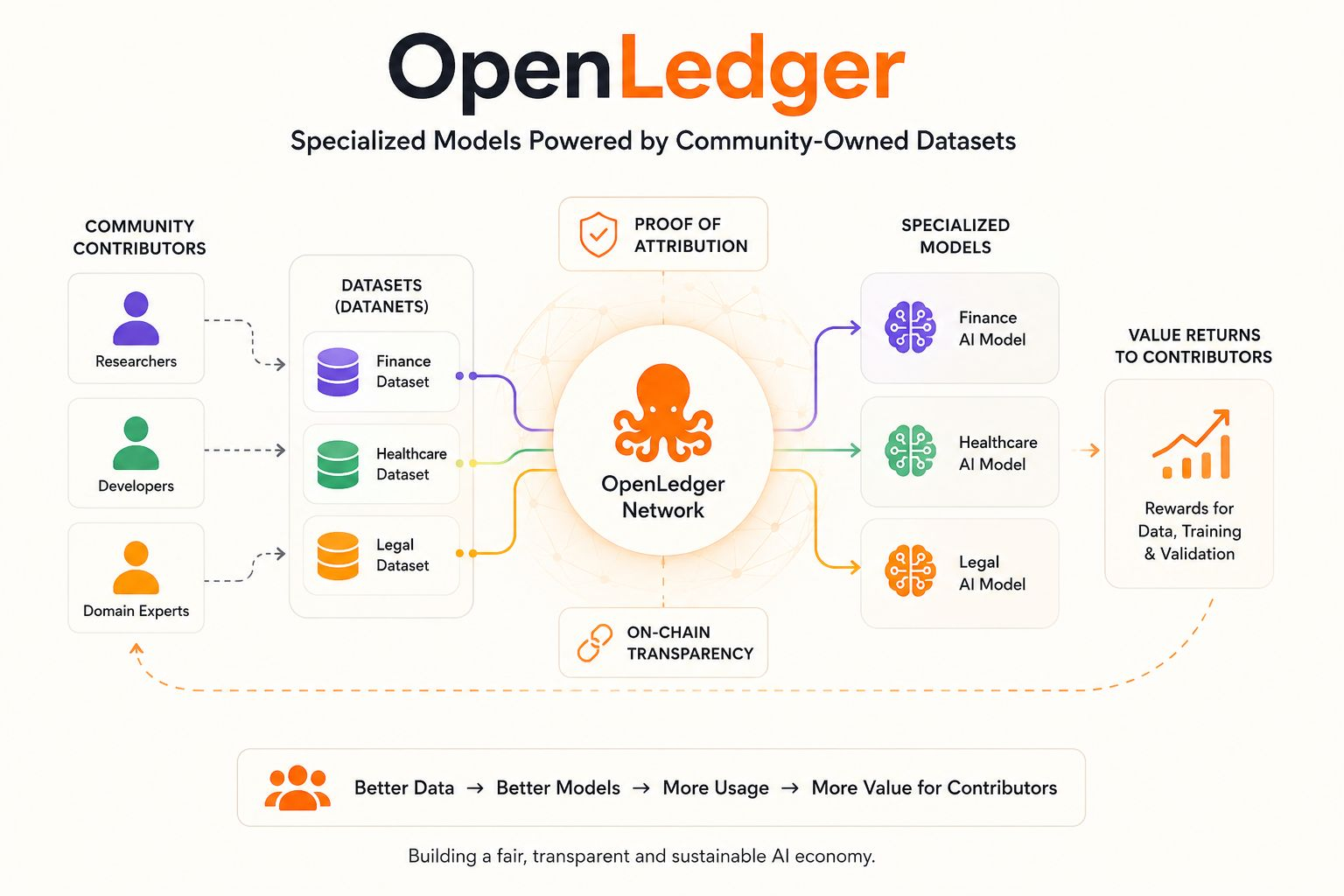
OpenLedger пытается встроить экономическую отслеживаемость прямо в инфраструктуру.
Это создает гораздо более здоровую структуру стимулов.
Потому что как только участники понимают, что их наборы данных могут постоянно генерировать ценность через использование модели, мышление переключается с краткосрочного фарминга на долгосрочное участие. И честно говоря, Web3 отчаянно нуждается в большем количестве систем, ориентированных на удержание, а не на извлечение.
Еще одна вещь, которая меня удивила, это то, насколько практичным выглядит их мышление по инфраструктуре по сравнению со многими нарративами ИИ, которые витают сегодня.
OpenLedger говорит не только о интеллекте или моделях. Они также думают о эффективности развертывания, масштабируемом выводе и повторно используемых экономиях данных.
Это звучит технически, но это имеет большое значение.
Многие проекты ИИ полностью сосредоточены на идее интеллекта, игнорируя экономическую реальность за вычислительными затратами. В конечном итоге каждая сеть сталкивается с одной и той же проблемой: если операционные расходы становятся слишком высокими, устойчивость исчезает, независимо от того, насколько сильно нарратив выглядит в социальных сетях.
OpenLedger, похоже, осознает эту проблему заранее.
Теперь, гарантирует ли это успех?
Совсем нет.
Риски исполнения все еще огромны. Строить децентрализованную инфраструктуру ИИ уже сложно. Создать такую, где атрибуция, стимулы, масштабируемость и реальное принятие разработчиками работают вместе, — это еще большая проблема.
И есть еще одна реальность, которую люди не могут игнорировать.
Большинство пользователей все еще выбирают удобство вместо прозрачности. Централизованные компании ИИ уже доминируют в инфраструктуре, ликвидности и внимании. OpenLedger входит на рынок, где одной технической силы недостаточно. Большая проблема заключается в изменении поведения пользователей.
Но даже с учетом всех этих рисков, я продолжаю приходить к одному и тому же выводу.
Это не похоже на еще одну краткосрочную нарратив о токенах ИИ.
Это больше похоже на попытку переработать то, как интеллект структурируется экономически внутри Web3.
И, возможно, поэтому я продолжаю обращать на это внимание.
Не из-за хайпа.
Потому что под всей этой шумихой вокруг ИИ сейчас, собственность может тихо стать самым важным слоем из всех.