Было поздно, мой экран светил слишком ярко, и у меня было слишком много вкладок OpenLedger открыто. Datanets здесь. ModelFactory там. OpenLoRA, AI Studio, Proof of Attribution, агенты, монетизация данных, монетизация моделей. Все нужные элементы были передо мной, и на несколько минут мне действительно понравилась их форма.
Тогда меня осенила раздражающая мысль.
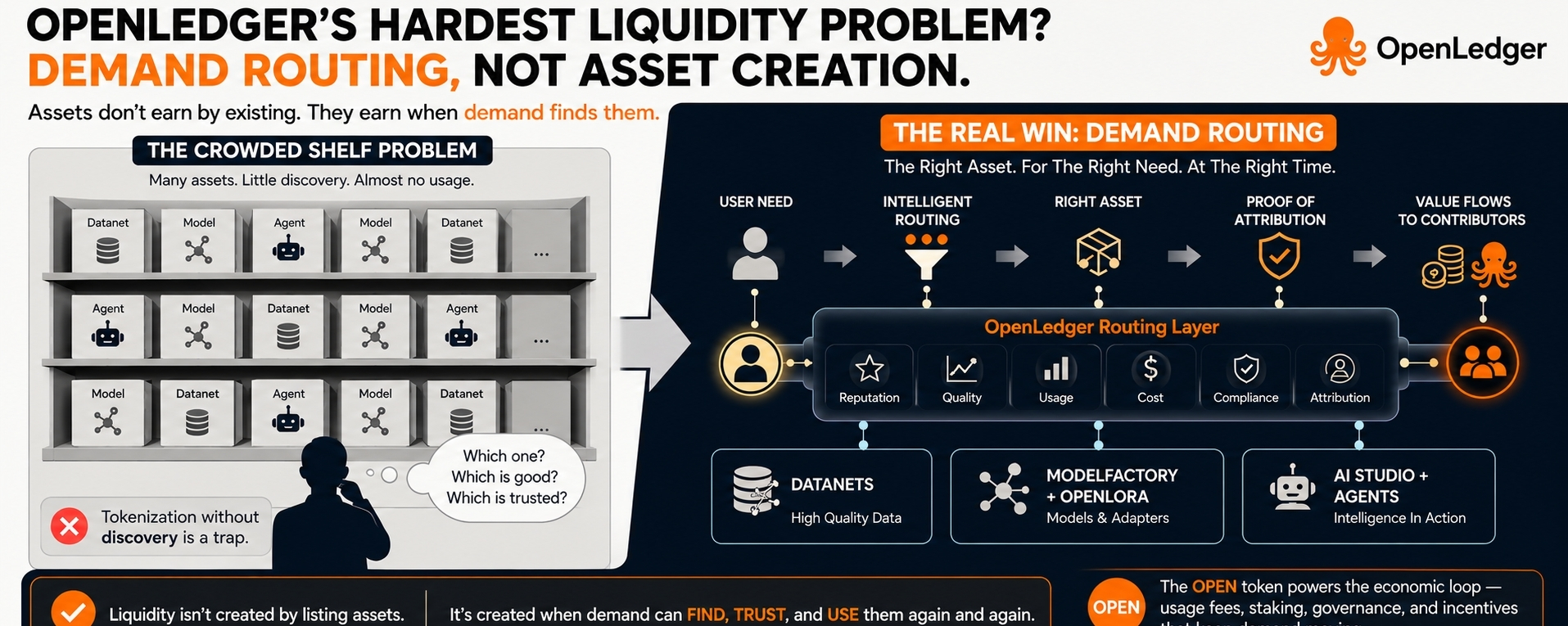
Что произойдет, когда будет сотни или тысячи этих AI активов, и большинство из них просто будут лежать без дела?
Потому что, будем честны, крипто-AI любит считать неправильные вещи. Общее количество зарегистрированных моделей. Данные в цепочке. Количество запущенных агентов. Количество участников. Количество созданных активов. Это выглядит здорово на панели управления. Это выглядит здорово в посте кампании. Это заставляет экосистему казаться живой.
Но вот неприятная правда. Модель, которую никто не находит, не ликвидна. Датанет, который никто не использует, не зарабатывает. Агент ИИ, через которого никто не маршрутизирует спрос, просто еще один объект на переполненной полке.
Это вопрос OpenLedger, который я не могу игнорировать.
OpenLedger не слаб, потому что пытается монетизировать данные, модели и агентов. Это на самом деле интересная часть. Датанеты придают данным структуру. ModelFactory дает создателям способ создавать специализированные модели. OpenLoRA делает адаптацию и развертывание легче. AI Studio дает пользователям место для создания и взаимодействия. Proof of Attribution отслеживает, кто вносил ценность, когда происходит вывод ИИ. Токен OPEN затем находится внутри этого экономического цикла.
Хорошо. Но все это в основном объясняет, как предложение попадает в систему.
Самая сложная часть — это спрос.
Меня сводит с ума, когда люди говорят, что размещение активов ИИ в цепочке автоматически делает их ликвидными. Нет. Это не работает так на рынках. Токенизация не создает покупателей волшебным образом. Атрибуция не создает использование волшебным образом. Реестр не создает актуальность волшебным образом. У вас может быть идеальная собственность и все равно мертвый инвентарь.
Это то, что я называю синдромом переполненной полки.
Полка выглядит впечатляюще. Она имеет модели, наборы данных, адаптеры, агентов, возможно, даже сигналы репутации и следы атрибуции. Но когда приходит реальный пользователь, вопрос предельно прост. Какой из них мне использовать? Какой из них достаточно хорош? Какой из них надежный? Какой из них подходит для моей задачи? Какой из них имеет реальный спрос за собой, а какой просто технически доступен?
Этот уровень принятия решений — это то, где живет настоящая проблема ликвидности OpenLedger.
Если OpenLedger станет хорош только в создании активов ИИ, он рискует построить красивый склад. Огромный. Полный технически зарегистрированных активов, которые едва зарабатывают, потому что спрос продолжает течь к той же небольшой группе видимых победителей. Это не широкая ликвидность ИИ. Это концентрация, одетая в костюм децентрализации.
Слушай, Proof of Attribution имеет значение. Я не отвергаю это. Если модель использует чьи-то данные, вкладчик не должен исчезать в черном ящике. Это реальная проблема в ИИ. OpenLedger прав, что атакует ее. Но атрибуция отвечает на вопрос, что происходит после использования. Она не отвечает на вопрос, как выбрать правильный актив до использования.
И эта часть «до» — это всё.
Создатель приложений не хочет просматривать музей моделей. Им нужна правильная модель для работы. Агенту не нужна идеология. Ему нужно надежное маршрутизирование. Корпоративному пользователю не важно, что существует тысяча Датанетов, если он не может определить, какой из них точный, соответствующий, доступный и активный. Даже розничные пользователи не потерпят путаницы долго. Они следуют за тем, что кажется самым простым, быстрым и надежным.
Так что задача для OpenLedger не просто сказать: «Мы можем монетизировать активы ИИ».
Задача состоит в том, чтобы доказать, что спрос может проходить через эти активы разумно.
Это означает, что открытие должно стать экономической инфраструктурой, а не побочной функцией. Рейтинг, репутация, история использования, качество атрибуции, стоимость, производительность модели и надежность агента все начинают иметь значение. Если эти сигналы слабы, сеть становится шумной. Если они сильны, OpenLedger может начать превращать пассивный ИИ-инвентарь в активный экономический поток.
Вот где я хочу, чтобы сообщество OpenLedger было более честным с самим собой. Перестаньте только праздновать количество созданных активов. Спросите, сколько из них используется повторно. Спросите, получают ли Датанеты реальный спрос вниз по течению. Спросите, становятся ли результаты ModelFactory полезными продуктами или просто еще одним предложением. Спросите, связан ли утилита OPEN с живым движением по сети или в основном с обещанием, что движение придет позже.
Потому что токенизация без открытия — это ловушка.
Это придаёт людям ощущение, что ценность была разблокирована, когда ценность лишь была обозначена. Это делает собственность видимой до того, как спрос будет доказан. Это может заставить вкладчиков чувствовать себя включенными, в то время как фактические доходы остаются низкими. Это разрыв, который OpenLedger должен закрыть.
Бычья версия OpenLedger — это не "много ИИ активов в цепочке."
Бычья версия гораздо сложнее. Это сеть, где потребность пользователя может найти правильный Датанет, где модель создателя может найти реальное применение, где агенты направляют работу через надежный интеллект, где Proof of Attribution оплачивает вкладчиков, потому что фактический спрос на выводы продолжает существовать.
Вот это настоящая ликвидность.
Не такого рода скриншоты. Не такого рода метрики кампании. Того рода, где активы зарабатывают, потому что рынок продолжает их выбирать.
Так что да, я наблюдаю за OpenLedger. Но я не слежу только за количеством активов. Я слежу за полкой. Я слежу за тем, становится ли она рынком или кладбищем.
Потому что в ИИ актив, который имеет значение, — это не тот, который существует.
Это тот актив, который спрос может найти.
