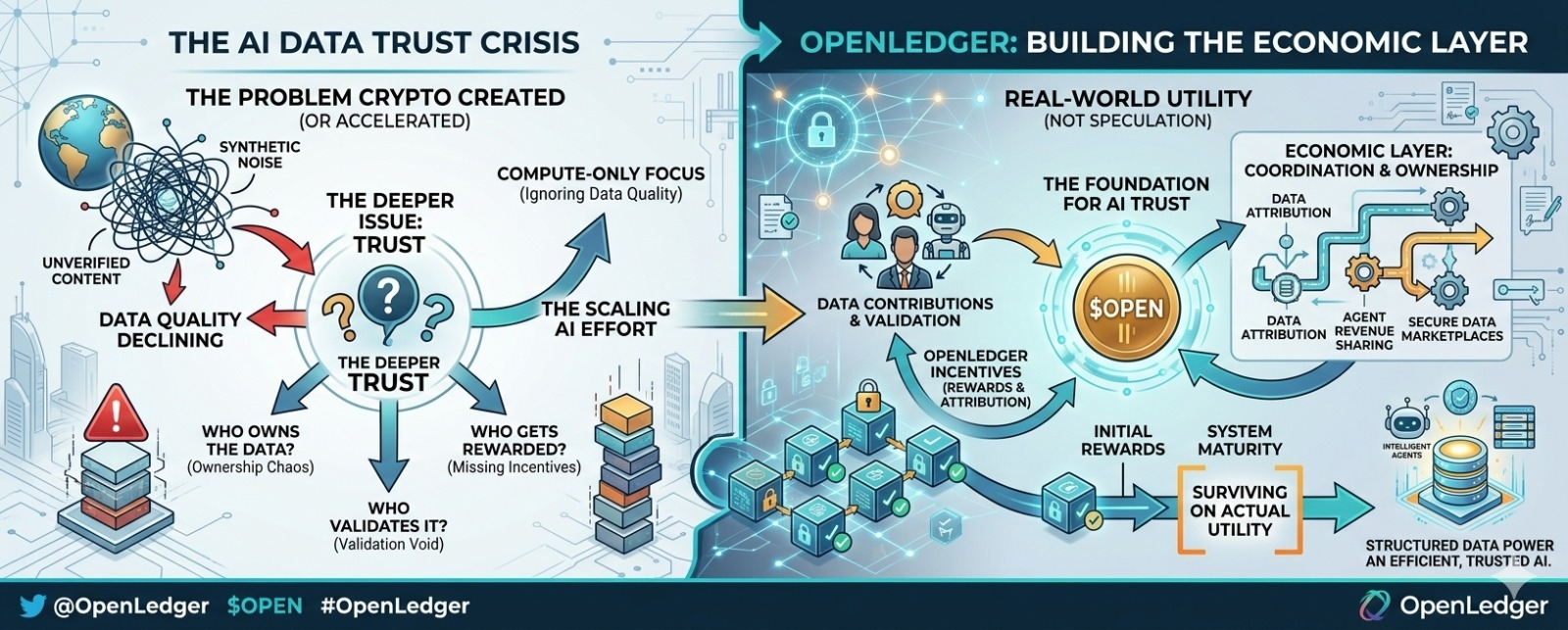
Я много думал о том, как быстро AI-системы становятся зависимыми от данных, которые они уже не могут должным образом проверять. Интернет уже переполнен синтетическим контентом, переработанной информацией и автоматизированным взаимодействием, притворяющимся реальной активностью. И, тем не менее, рынок все еще считает, что масштабирование AI — это только проблема вычислений.
Это не так.
Глубинная проблема — это доверие. Кто владеет данными? Кто их проверяет? Кто получает вознаграждение, когда AI-агенты создают ценность, используя информацию, собранную у тысяч незаметных участников? Большинство систем все еще не отвечают на эти вопросы ясно. Они просто работают быстрее и надеются, что никто не станет задавать вопросы о структуре, стоящей за этим.
Вот почему @OpenLedger постоянно привлекает моё внимание. Не потому что обещает очередной рассказ про ИИ, а потому что пытается построить экономический слой вокруг собственности и координации, прежде чем вся экосистема будет заполнена неиспользуемым шумом.
Тем не менее, я осторожен с такими проектами. Крипта имеет привычку превращать важные идеи в временные спекулятивные машины. Как только ликвидность приходит, поведение меняется. Сети перестают оптимизироваться для полезности и начинают оптимизироваться для извлечения. Реальное участие становится сложнее отделить от фарминга.
Так что настоящий тест для OpenLedger, вероятно, не произойдёт во время роста. Он произойдет позже, когда вознаграждения нормализуются, и система должна будет существовать на основе реальной полезности, а не на импульсе. Обычно это тот момент, когда инфраструктура либо становится необходимой, либо тихо исчезает.
Пока что я просто наблюдаю, как фундамент держится под вниманием.