

Я потратил почти три месяца на аудит того, как работает атрибуция данных в проектах, которые утверждают, что решают эту проблему. И чем больше я копал, тем больше сталкивался с одним и тем же неудобным вопросом: если оптимизировать под точность, ты замедляешь цепочку. Если оптимизировать под скорость, открываются окна для эксплуатации. Если закрываешь уязвимости, твой механизм оценки начинает эксплуатироваться на границах. Выбирай два. Это трилемма, о которой никто в этом пространстве не говорит честно.
Так что позволь мне сказать это прямо и объяснить, почему подход OpenLedger - это самая серьезная структурная попытка, которую я видел, чтобы натянуть эту нить.
Во-первых, контекст. Конкурентная среда здесь на самом деле состоит из четырех различных ставок на четыре разные проблемы, а рынок продолжает относиться к ним как к синонимам. Vana строит дата-DAO, коллективы людей, объединяющих данные и извлекающих ценность через структуры совместной собственности. Ocean Protocol управляет уровнем рынка, оценивая и торгуя наборами данных как финансовыми инструментами. SingularityNET работает как рынок услуг, соединяющий AI-агентов и API через экономику координации. Это реальные проекты с реальными механиками. Но ни один из них не решает проблему атрибуции в первую очередь. Они решают доступ, ликвидность и координацию. Атрибуция либо находится ниже по течению, либо предполагается.
Вот и разрыв. И он огромен.
OpenLedger строит нечто структурно иное: рельсы атрибуции. Не DAO, не рынок, не сервисная экономика. Уровень оценки и верификации, который отвечает на вопрос, который каждая AI-экономика в конечном итоге должна задать: кто что внес, на каком уровне качества и когда?
Вот почему этот вопрос сложен. Представьте, что вы оцениваете релевантность вклада данных в реальном времени. Точность требует глубокей валидации, перекрестной проверки входных данных с дельтами производительности модели, с учетом полезности ниже по течению. Эти вычисления дорогие и медленные. Скорость требует приближения, использования легковесных эвристик, принятия некоторого шума в оценках. Но легковесные эвристики - это именно то, что сложные вкладчики будут исследовать и эксплуатировать. Пропустите достаточное количество заявок через быструю систему, и вы найдете сигнал, который вознаграждает оценщик, затем оптимизируйте этот сигнал вместо того, чтобы по-настоящему оценивать качество. Это проблема устойчивости к мошенничеству. И закрытие ее добавлением сложности возвращает вас к медленной, дорогой верификации, которую вы пытались избежать.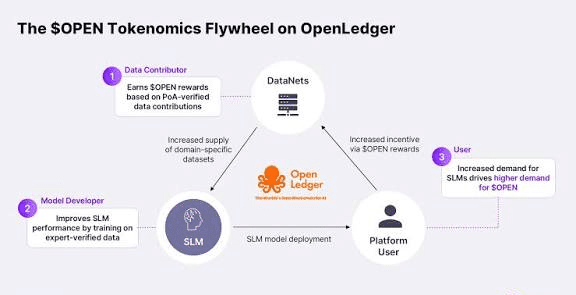
Что делает архитектура OpenLedger, так это модульность. Она отделяет время атрибуции от окончательной атрибуции. Вклады получают временную оценку быстро, достаточно, чтобы обеспечить немедленный доступ и предотвратить очевидные наводнения низкокачественных данных. Окончательная атрибуция, экономически значимая запись, устанавливается после окна верификации, которое может выполнять более тяжелые вычисления, не блокируя цепочку на скорости загрузки. Это не идеальное решение. Ни одно решение трилеммы не является таковым. Но это первая архитектура, которую я видел, которая делает компромисс явным, а не скрывает его.
Дифференциация имеет значение в конкурентной среде. Сила Vana заключается в общественной собственности, но она не может проверить, что внутри данных DAO без доверительных предположений. Сила Ocean заключается в открытии цен, но у него нет родного механизма для вознаграждения качества вклада, только поставка. Сила SingularityNET заключается в координации агентов, но атрибуция производительности модели к конкретным обучающим входам не является его основной концепцией. OpenLedger строит там, где все трое останавливаются. В тот момент, когда вопрос перестает быть "могу ли я получить доступ к данным" и начинает быть "могу ли я доказать, что эти данные сделали что-то полезное."
Честный скептицизм, который я испытываю: временные системы оценки создают свои собственные векторы игры. Если вкладчики знают быструю эвристику и медленное окончательное разрешение, гонка становится стремлением пройти временные ворота с минимальными затратами. Долгосрочная защищенность OpenLedger зависит от того, насколько адаптивен уровень эвристики и будет ли модель оценки переобучена достаточно быстро, чтобы опережать противодействующую оптимизацию.
Но это проблема второго порядка. Проблема первого порядка в атрибуции данных для AI-экономик заключается в том, что никто не построил рельсы специально для этого. OpenLedger это сделал. Это само по себе делает его стоящим того, чтобы внимательно следить за ним.
Трилемма не исчезает. Но, по крайней мере, кто-то наконец честно проектирует вокруг нее.
