я изучал архитектурные документы openledger и разбросанные обсуждения, в основном потому, что пытаюсь отделить историю "искусственный интеллект + крипто-токен" от того, что на самом деле строится. Большинство людей, с которыми я общался, кажется, складывают это в одну папку: "децентрализованный рынок данных, участники загружают материалы, токеновые вознаграждения, готово." Но этот нарратив кажется слишком сжатым, и он скрывает сложную часть: как сделать атрибуцию данных и стимулы работающими, когда на кону реальные деньги и реальный спрос на модель.
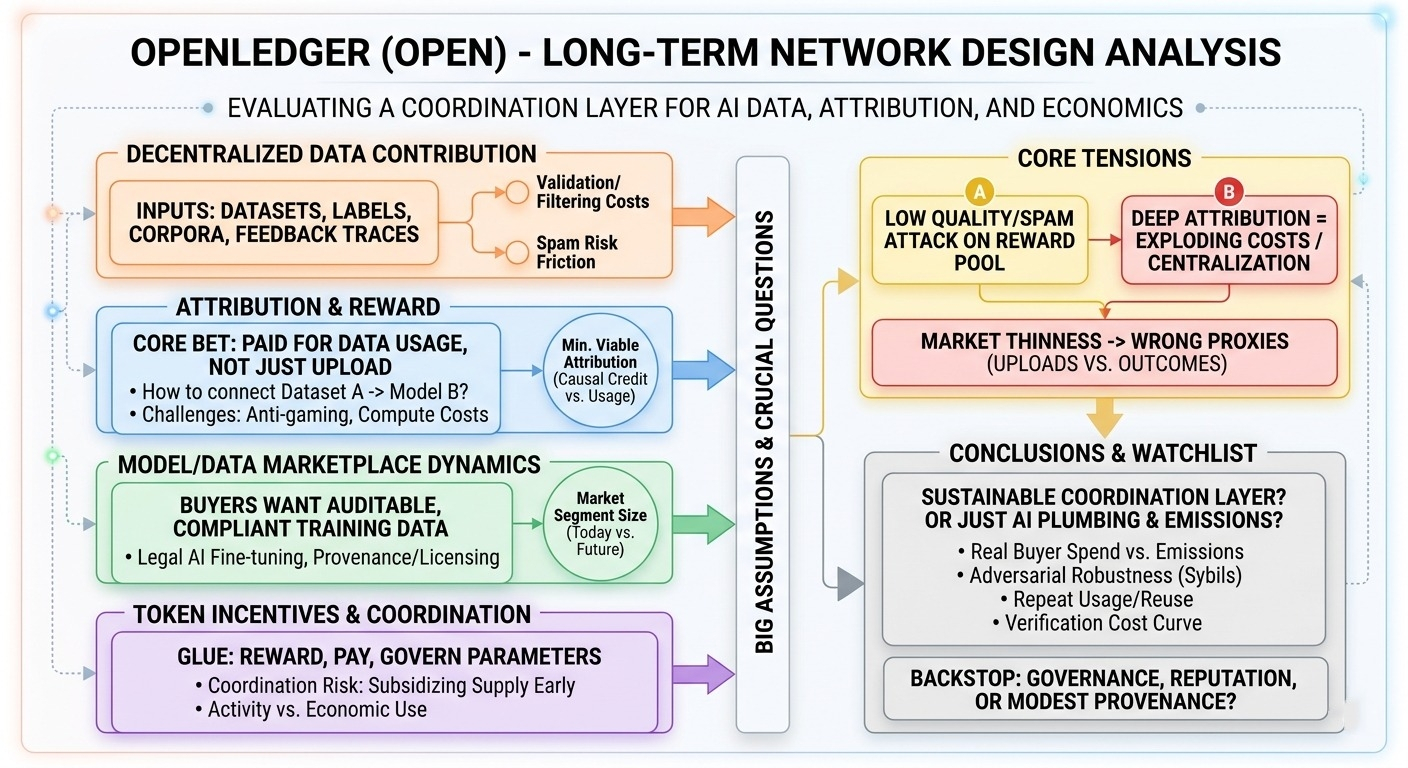
что меня поразило, так это то, что openledger не только "хранение + платежи." он пытается стать слоем координации, где (1) данные вносятся, (2) данные атрибутируются к ценности модели, и (3) использование модели становится экономическим циклом в цепочке. это амбициозно, и честно говоря, я не совсем уверен, что элементы хорошо сочетаются, но форма интересная.
первая составляющая: децентрализованный вклад данных. сторона вклада, похоже, хочет быть открытой: наборы данных, помеченные образцы, возможно, специализированные корпуса, потенциально даже следы обратной связи от использования модели. вопрос дизайна здесь менее о "могут ли люди загружать данные?", а больше о "можно ли удерживать стоимость валидации и индексирования этих данных достаточно низкой, чтобы сеть не утонула в мусоре?" любой открытый канал вклада стремится к спаму, если нет трения, репутации или какого-то вероятностного слоя верификации, который легко реализовать.
второе: атрибуция + вознаграждение. это основная ставка. предложение openledger (насколько я его понимаю) заключается в том, что вкладчики получают плату не просто за загрузку; они получают плату потому, что их данные используются, а использование можно измерить/атрибутировать. и это часть, о которой я продолжаю думать... атрибуция в ML запутанная даже вне цепочки. как только вы помещаете это в протокол, вам нужна история о "как мы знаем, что набор данных A помог модели B", которая устойчива к манипуляциям и не безумно дорогая в вычислении. функции влияния, кредитное распределение на основе градиента, шардирование наборов данных с аудиторскими тропами — все это существует в академической среде, но превращение их в что-то, устойчивое к враждебным действиям и операционное, это другое дело. мне бы хотелось увидеть, что они считают своим "минимально жизнеспособным атрибутом": это строгое причинное кредитование или больше похоже на "подтвержденное включение + измерение использования"?
третье: динамика рынка моделей/данных. openledger, похоже, предполагает, что будут покупатели, которые хотят чистые, поддающиеся аудиту обучающие данные или входы моделей с происхождением. реальный пример: небольшая юридическая AI компания по тонкой настройке хочет набор данных аннотированных пунктов контрактов, и им нужно происхождение для соблюдения норм (откуда пришел каждый пункт, какая лицензия, кто его аннотировал). в централизованной настройке вы доверяете внутренним журналам платформы. здесь цель состоит в том, чтобы сделать происхождение и лицензирование поддающимися аудиту и оплачиваемыми на цепочке. это ценно, если соблюдение норм действительно имеет значение для покупателей — но не очевидно, насколько велика эта сегментация покупателей сегодня по сравнению с "когда-нибудь".
четвертое: токеновые стимулы + координация. токен, по сути, является клеем: он вознаграждает вклад, платит за доступ и, возможно, управляет параметрами (порогами верификации, кривыми вознаграждений, правилами штрафов и т.д.). мой скептицизм здесь довольно стандартен: если эмиссии делают большую часть выплат на ранних этапах, вы субсидируете предложение до появления спроса. это может сработать как начальная поддержка, но это также может создать сеть, которая отлично производит "активность" и не очень хорошо производит экономически полезные данные.
так кто создает ценность? вкладчики создают сырьё, но реальная ценность создается, когда строители моделей многократно платят за доступ к данным/моделям, потому что это улучшает их маржу продукта. что приводит к большим предположениям: (1) команды ai захотят на цепочке координированные сделки с данными, (2) атрибуция будет достаточно надежной, чтобы установить цену, и (3) протокол сможет фильтровать по качеству, не превращаясь в разрешённый картель.
напряжение, вокруг которого я продолжаю вертеться: данные низкого качества и спам — это не просто шум; это атака на пул вознаграждений. если атрибуция поверхностная (например, оплата за загрузку), фермы сибиллов выигрывают. если атрибуция глубокая (например, вычислительно тяжелое распределение кредитов), затраты взлетают или верификация централизуется у нескольких операторов. и если "рынок" узкий, токеновые стимулы могут начать вознаграждать неправильные прокси (загрузки, метки, транзакции) вместо результатов (оплачиваемое повторное использование, измеримый рост модели).
пока нет идеального вывода. я в основном пытаюсь понять, станет ли openledger устойчивым слоем координации или он привязывает токеновые стимулы к ai инфраструктуре до появления реального спроса.
следя за:
- соотношение вознаграждений от реальных покупок против эмиссий токенов
- доказательства того, что атрибуция выживает при враждебном поведении (сибиллы, сговор, отмывание данных)
- повторное использование: покупаются/лицензируются ли одни и те же наборы данных несколько раз?
- кривая стоимости верификации: становится ли обеспечение качества дешевле за единицу с течением времени или дороже?
если протокол не может доказать "доверенную атрибуцию в масштабе" без централизации, что тогда является подстраховкой — управление, репутация или просто принятие более скромной версии происхождения?