There is a simple habit people have with technology.
At first, they ask whether it works.
Later, they ask what it is doing behind the scenes.
AI is moving through that same pattern. In the beginning, people were impressed that a model could write, summarize, code, draw, or reason through a problem. The output was enough to hold attention. It felt new. Sometimes strange. Sometimes useful in a way that was hard to explain.
But after using AI for a while, the questions become quieter.
Where did this answer come from?
What information shaped it?
Which model handled the task?
Did an agent take action somewhere?
Was private data involved?
Who should be paid if this output creates value?
These are not flashy questions. They feel almost administrative. Like asking for a receipt after a purchase.
But that may be exactly what AI starts to need.
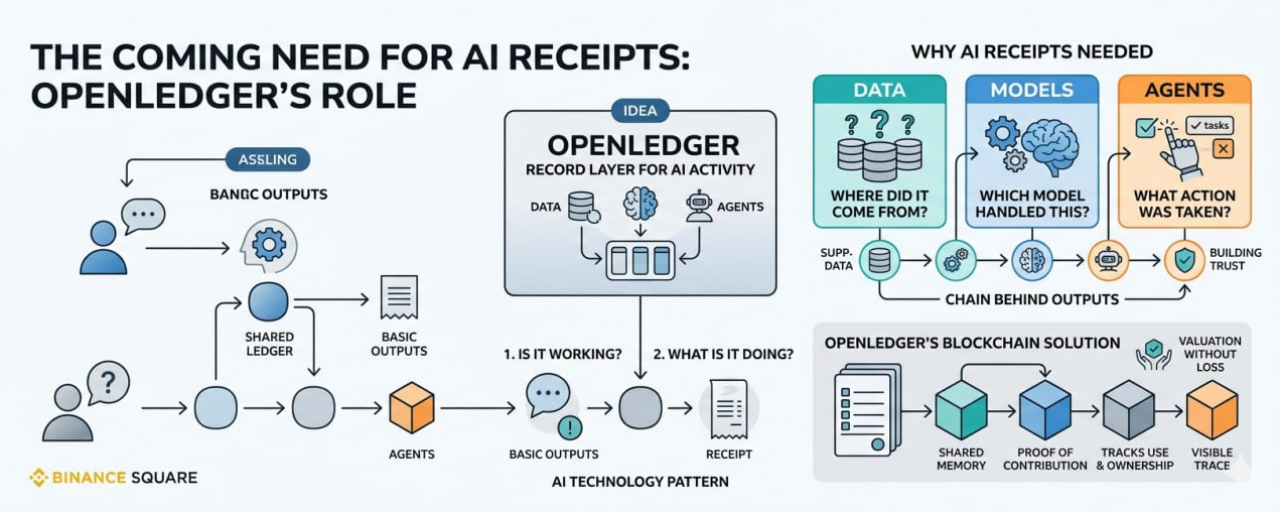
OpenLedger can be understood through this idea of receipts. Not paper receipts, of course. More like records that follow AI activity and make it easier to see what was used, what contributed, and what value moved through the system.
That is a different way to think about it.
OpenLedger is described as an AI blockchain focused on data, models, and agents. Those three words can sound technical, but they are also the basic ingredients of modern AI work. Data gives the system material. Models turn patterns into outputs. Agents act on tasks, tools, and instructions.
Together, they create something that looks smooth from the outside.
The problem is that smooth systems can hide a lot.
A company may use several datasets to improve a model. That model may call another model. An agent may use a tool, check a database, make a decision, and pass the result somewhere else. By the time the final output appears, the chain behind it may be difficult to follow.
At small scale, maybe that is fine.
At larger scale, it becomes messy.
Imagine AI being used in finance, healthcare, education, supply chains, research, media, or government workflows. In those places, people cannot only say, “the AI gave an answer.” They need to know more. They need records. They need proof of what happened, or at least a reliable trail.
That is where OpenLedger’s role starts to feel more practical.
It is not only about creating a market for AI assets. It is also about creating a record layer for AI activity. A way for data, models, and agents to leave behind some kind of trace when they are used. Not every detail has to be public. Not every action needs to be exposed. But the system needs enough memory to make trust possible.
You can usually tell when a technology becomes serious because documentation becomes part of the product.
Food has labels.
Finance has ledgers.
Software has logs.
Supply chains have tracking numbers.
Even simple online orders come with status updates.
AI may need its own version of that.
Not because users want more complexity. Most people do not. They want less confusion. They want to know whether something is safe to use, whether the source is legitimate, whether the model is reliable, and whether the people behind the inputs are being treated fairly.
OpenLedger seems to sit in that space between usefulness and accountability.
Take data, for example. Data is often talked about like raw material, but it is rarely neutral. Someone gathered it. Someone cleaned it. Someone owned it. Someone may have been represented inside it. If that data improves an AI system, it should not simply vanish into the background without any record.
The same goes for models.
A model can be reused in many places. It might help classify documents, detect patterns, answer questions, or guide an agent. If it performs well, that use should be visible in some way. If it fails, that history matters too. A model without a track record is harder to trust.
Agents make the question even more interesting.
An agent is not just something that answers. It does things. It can search, decide, send, update, compare, and trigger actions. As agents become more common, people will want to know what they did and why. Not in a dramatic way. Just in the normal way people want a record when something acts on their behalf.
This is where blockchain can be useful without needing to be loud about it.
A shared ledger can create a common place for records. It can help different parties agree on ownership, access, usage, and payment. It can reduce the need for one central platform to be the only source of truth. In an AI economy made of many contributors, that shared memory could matter.
Still, it is worth being careful.
A receipt does not prove that something is good. It only shows that something happened. OpenLedger would still need strong ways to judge quality, protect privacy, handle disputes, and prevent low-value assets from filling the system. A record layer is helpful, but it is not the whole answer.
That is probably the honest way to look at it.
OpenLedger is not solving all of AI’s problems at once. It is pointing at one part of the problem that may become harder to ignore: AI needs better records.
Records of contribution.
Records of use.
Records of ownership.
Records of agents acting across systems.
Records that help value move without completely losing its trail.
And maybe this is where the idea becomes less abstract.
As AI becomes more normal, people may stop being amazed by the output itself. They may start asking for the story behind the output. Not a long story. Just enough to know what they are dealing with.
OpenLedger is building around that quiet need.
A world full of AI systems will not only need intelligence. It will need receipts for intelligence. Small traces that show where value came from, where it went, and who remained visible along the way.