
I went into OpenLedger with the same hesitation I usually have around AI and blockchain projects now. After a while, they all start sounding strangely identical. Everyone talks about infrastructure, automation, decentralized intelligence, ownership, coordination. But once you look closer, most of the systems still depend on scattered tooling, centralized control somewhere in the middle, or workflows that break the second real usage begins. The language always feels bigger than the product itself.
That was honestly my expectation here too. I assumed OpenLedger would be another project trying to attach AI branding to a blockchain narrative that already exists. But the more time I spent reading through how the system is actually structured, the more I noticed the focus was less about storytelling and more about operational flow. That changed my perspective a bit.
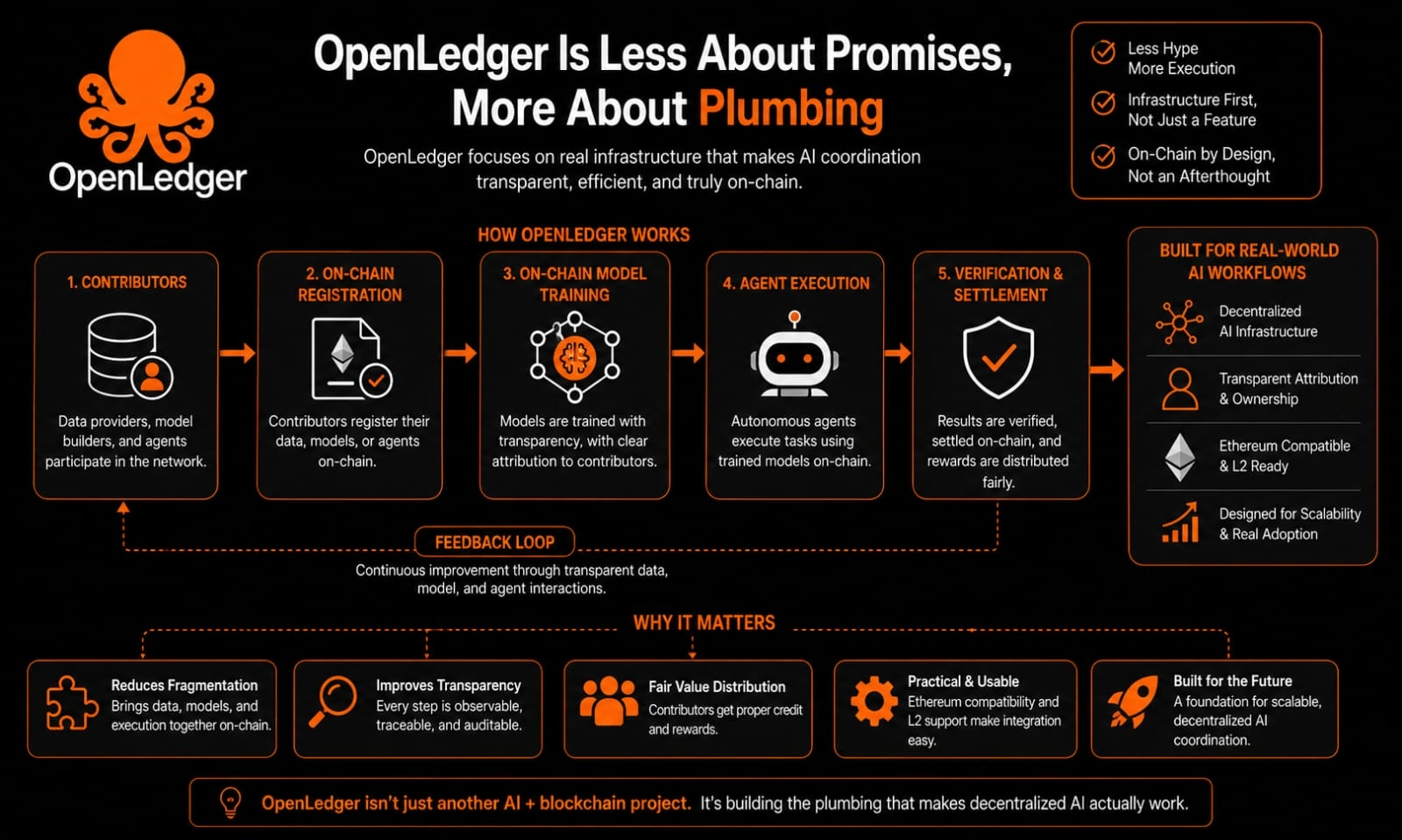
What caught my attention was how OpenLedger approaches AI participation as infrastructure instead of treating it like a feature sitting on top of a chain. Most AI systems today still feel fragmented. Data lives in one place, models somewhere else, execution somewhere else again, and verification usually depends on trusting a company behind the curtain. Even when people talk about decentralization, the actual coordination layer remains messy and difficult to audit.
OpenLedger seems to be trying to reduce that friction directly at the infrastructure level. The platform is built around allowing data contributors, AI models, and autonomous agents to operate on chain instead of relying on disconnected systems stitched together afterward. That matters more than people realize because AI workflows become difficult very quickly once multiple systems need to interact with each other across different environments.
I found the on-chain model training aspect especially interesting, not because it sounds futuristic, but because it addresses a real issue around transparency and attribution. In most AI environments today, it is difficult to know where value actually comes from. Data providers rarely benefit properly, model behavior is hard to trace, and execution visibility disappears once systems scale. OpenLedger seems designed to make those relationships more observable instead of hiding them behind centralized infrastructure.
The Ethereum compatibility also makes the whole thing feel more practical. Wallet integration, smart contract interaction, and Layer-2 connectivity reduce a lot of unnecessary friction. That may sound like a small detail, but usability is usually where ambitious infrastructure projects quietly fail. Systems only matter if people can actually integrate them into existing workflows without rebuilding everything from scratch.
I still think there are real limitations here. Infrastructure alone does not guarantee adoption, and coordinating decentralized AI activity at scale is probably far harder than most teams admit publicly. Regulation will shift, implementation quality will vary, and scalability pressure will test every system eventually.
Still, OpenLedger feels more grounded to me than many projects in this space because the focus seems centered on execution itself. Not narratives. Not abstract promises. Just trying to make AI coordination function more cleanly on chain. And honestly, that is probably where real adoption starts anyway.