OpenLedger — это один из тех проектов, которые заставляют тебя задуматься на секунду, не потому что презентация совершенно новая, а потому что проблема под ней достаточно реальна, чтобы ты не мог сразу ее отвергнуть.
Честно говоря, это сейчас редкость в крипте.
После нескольких циклов у тебя начинает развиваться своего рода аллергия на большие нарративы. DeFi собирался перестроить финансы. GameFi собирался привлечь следующие миллиард пользователей. Земля Метавселенной каким-то образом должна была заменить недвижимость. Модульные цепочки должны были решить проблемы масштабируемости. AI крипта сейчас на последней стадии, где каждый проект вдруг обнаруживает, что всегда было о искусственном интеллекте.
Так что, когда что-то называет себя "ИИ блокчейном", первое желание - это не восторг. Это подозрение.
Вы читаете фразу один раз, и ваш мозг сразу готовится к привычному набору модных слов: децентрализованный интеллект, открытые агенты, суверенитет данных, масштабируемая инфраструктура, общественное владение, согласование стимулов. Все знакомые ингредиенты. Все слова, которые звучат важно, пока вы не спросите, что на самом деле происходит под поверхностью.
Но OpenLedger, по крайней мере, указывает на проблему, которая имеет значение.
У ИИ есть проблема с вкладами.
Не проблема брендинга. Не проблема токена. Проблема вкладу.
Каждая полезная ИИ-система построена на данных, знаниях, примерах, обратной связи, документах, рабочих процессах, метках, исправлениях и опыте в определенной области. Это та часть, которую люди любят пропускать. Модель представляется как продукт, но на самом деле модель - это конечный результат длинной цепочки невидимых входов.
Кто-то создал данные. Кто-то очистил их. Кто-то организовал их. Кто-то знал достаточно о предмете, чтобы сделать информацию полезной. Затем все это поглощается моделью, и как только оно внутри, исходный вклад становится почти невозможным увидеть.
Это странная сделка современного ИИ. Каждый вносит вклад в уровень интеллекта, но только несколько платформ захватывают большую часть ценности.
OpenLedger пытается строить вокруг этого разрыва.
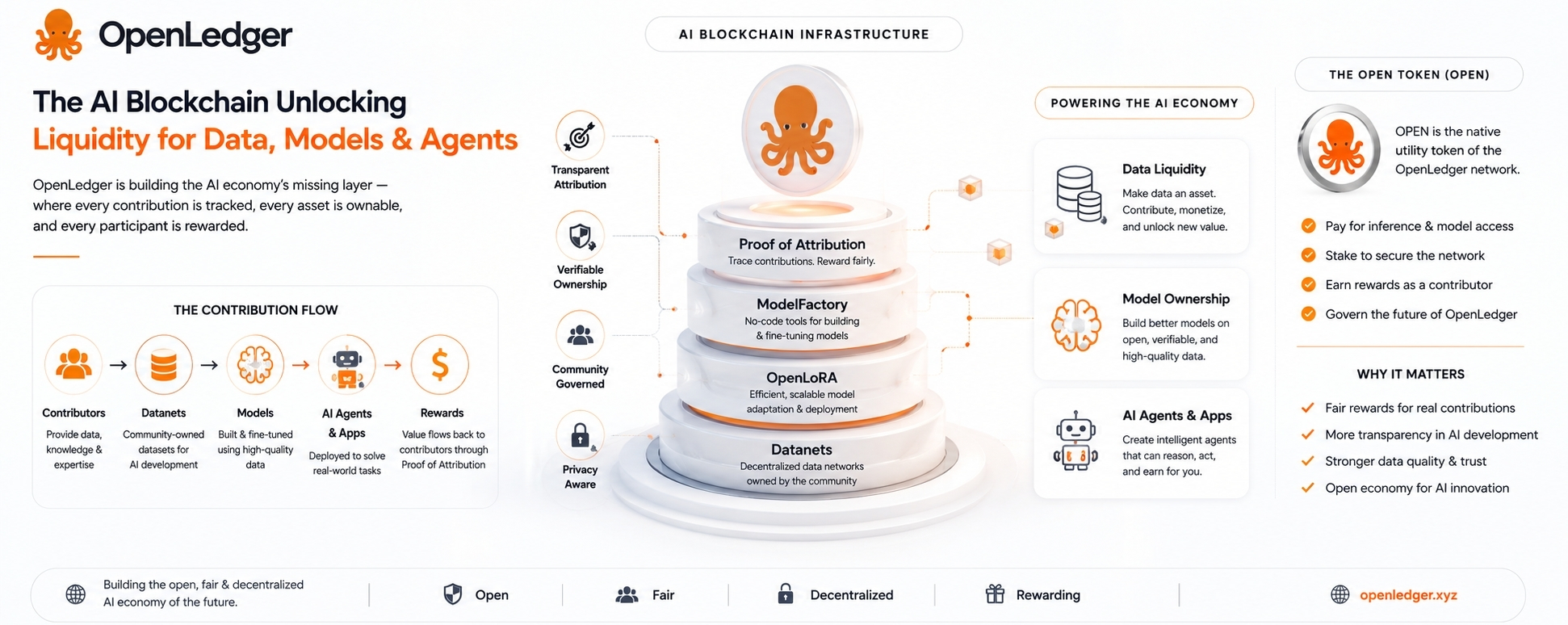
Основная идея заключается в том, что данные, модели и ИИ-агенты не должны просто плавать вокруг как расплывчатые цифровые объекты. Их следует отслеживать. Они должны иметь происхождение. Они должны быть связаны с людьми или сообществами, которые их создали. И если они создают ценность позже, должна быть какая-то механика для вознаграждения участников за их вклад.
Это звучит очевидно, когда вы говорите это медленно. Это также звучит крайне сложно, когда вы думаете о том, как на самом деле работает ИИ.
Потому что атрибуция ИИ запутанная.
Модель не отвечает на вопрос, просто вытаскивая один файл с полки. Она не говорит: "Этот ответ пришел на 12% из набора данных Али, на 8% из этого аудиторского отчета и на 3% из того поста на форуме." По крайней мере, не естественным образом. Выходы формируются обучающими данными, настройкой, весами, подсказками, встраиваниями, системами извлечения, адаптерами и всем остальным, что было прикреплено к стеку.
Таким образом, когда OpenLedger говорит о Доказательстве атрибуции, это та часть, на которую стоит обратить внимание, но также и та часть, которая заслуживает наибольшего скептицизма.
Идея заключается в том, чтобы определить, какие данные повлияли на вывод ИИ, и вознаградить участников на основе этого влияния. Если это сработает, это имеет значение. Если это станет расплывчатым, это просто еще одна система токенизированных очков с лучшим языком.
Это та линия, по которой OpenLedger должен двигаться.
Тем не менее, рамка не пустая. ИИ действительно нуждается в лучшем слое учета. В настоящее время интернет полон ценности, которую ИИ-системы потребляют, сжимают и монетизируют. Выход кажется чистым, но история входа размыта. И по мере того, как ИИ-агенты становятся более распространенными, это размытие становится более серьезной проблемой.
Если ИИ-агент помогает аудировать смарт-контракт, откуда пришло его знание о безопасности?
Если ИИ-трейдер распознает паттерн, чьи данные помогли ему научиться?
Если юридический ИИ-инструмент рассматривает контракт, какие документы повлияли на его рассуждения?
Если медицинский ассистент дает совет, какие знания стояли за этим ответом?
Эти вопросы больше не являются философскими. Они становятся экономическими в тот момент, когда люди начинают платить за результат.
Вот почему Датасеты OpenLedger интересны.
Датасет - это по сути сеть данных, принадлежащая сообществу, построенная вокруг определенной темы или случая использования. Вместо того, чтобы данные тихо собирались одной централизованной компанией, участники могут добавлять полезную информацию в общий слой данных. Эти данные затем могут быть использованы для обучения или настройки моделей.
В теории вы могли бы иметь Датасет для взломов смарт-контрактов, другой - для юридических документов, другой - для рабочих процессов в здравоохранении, другой - для картирования данных, другой - для анализа рисков DeFi и так далее.
Идея не просто собирать данные. Все собирают данные. Идея заключается в том, чтобы вести запись о том, кто что внес, а затем связать этот вклад с будущим использованием модели.
Это та часть, которая кажется более серьезной, чем обычная реклама "ИИ плюс токен".
Потому что если специализированный ИИ действительно то, в каком направлении движется рынок, то специализированные данные становятся чрезвычайно ценными. Общие модели уже достаточно хороши для широких задач. Следующая борьба не о том, кто сможет заставить чат-бота говорить приятные вещи. Это о том, кто сможет построить модели, которые глубоко понимают конкретные области.
Общий ИИ может объяснить риск смарт-контрактов. Специализированная модель, обученная на реальных данных о взломах, может действительно помочь обнаружить это.
Общий ИИ может говорить о финансах. Специализированная модель, обученная на структурированном поведении рынка и данных о рисках, может стать более полезной.
Общий ИИ может подводить итоги содержания в здравоохранении. Специализированная клиническая модель, при условии, что конфиденциальность и соблюдение норм обрабатываются должным образом, может сделать что-то гораздо более ценное.
Итак, OpenLedger нацеливается на реальную тенденцию: переход от общего ИИ к специализированному интеллекту.
Но снова, исполнение имеет значение.
Крипта имеет привычку превращать каждую действительную проблему в избыточно спроектированную токенизированную экономику. Иногда токен необходим. Иногда это просто временная мера для рынка, который мог бы работать и без него.
OPEN, нативный токен, должен находиться внутри экономики OpenLedger. Он может использоваться для сетевых сборов, доступа к моделям, платежей за вывод, стекинга, управления и вознаграждений участников. Это имеет смысл структурно. Если сеть действительно используется, токен имеет свою роль.
Но фраза "если сеть действительно используется" здесь делает много работы.
Токен не создает спрос, просто существуя. Рынок не становится ценным, потому что панель управления говорит, что участники могут зарабатывать. Трудная часть заключается в том, чтобы заставить людей вносить качественные данные, заставить разработчиков строить модели на основе этих данных, заставить пользователей платить за эти модели и убедиться, что вознаграждения распределяются так, чтобы это казалось справедливым, а не произвольным.
Вот где многие криптопроекты ломаются.
Они могут разработать стимулы для первой волны. Они могут привлечь ранних участников. Они могут сделать графики живыми. Но долгосрочная ценность приходит только тогда, когда система производит что-то, что действительно нужно людям вне стимула.
Будущее OpenLedger зависит от того, сможет ли он производить полезные ИИ-системы, а не просто хорошо обозначенные наборы данных.
ModelFactory - это часть этой попытки. Она предназначена для упрощения настройки, особенно для людей, которые не хотят иметь дело с тяжелой инфраструктурой машинного обучения. Это хорошее направление, потому что большинство экспертов в области не являются инженерами МЛ.
Человек, который понимает юридические контракты, может не знать, как настроить модель.
Трейдер, который понимает рыночную структуру, может не знать, как развернуть инфраструктуру вывода.
Исследователь безопасности, который понимает уязвимости, может не хотеть управлять адаптерами и графическими процессорами.
Если OpenLedger может упростить этим людям превращение знаний в полезные ИИ-активы, это важно.
OpenLoRA - это еще один практический элемент. Специализированные модели полезны, но их использование может стать дорогим. Настройка на основе LoRA уже является одним из более реалистичных путей создания множества легковесных вариаций моделей. Если OpenLedger сможет поддерживать эффективное развертывание многих настроенных моделей, это даст экосистеме более практическую основу.
Вот где проект начинает выглядеть менее как чисто нарративная игра и больше как попытка построить полный стек ИИ-продукции.
Данные поступают через Датасеты.
Модели создаются или настраиваются с помощью инструментов, таких как ModelFactory.
OpenLoRA помогает с развертыванием.
ИИ-агенты и приложения находятся на верхнем уровне.
Цепочка записывает вклад, использование и вознаграждения.
Это, по крайней мере, карта.
Вопрос, выглядит ли территория именно так, остается открытым.
Самая сложная часть остается атрибуцией. Легко написать "Доказательство атрибуции" в белой книге. Гораздо сложнее заставить участников доверять тому, что система точно измеряет влияние. Если вознаграждения слишком расплывчаты, люди потеряют интерес. Если систему можно обмануть, в ней появится много низкокачественных данных. Если только крупные участники получают выгоду, угол сообщества ослабевает. Если атрибуция слишком дорога или слишком медлительна, разработчики могут избегать этого.
Существует также проблема конфиденциальности. Некоторые из самых ценных данных ИИ являются конфиденциальными. Данные здравоохранения, финансовые записи, юридические материалы, корпоративные рабочие процессы — это не те вещи, которые люди просто так кидают в открытую сеть. OpenLedger потребует сильных разрешений, конфиденциальности и путей соблюдения норм, если он хочет серьезного принятия за пределами крипто-нативных наборов данных.
А потом есть проблема рынка. ИИ-крипта переполнена. Каждую неделю появляется новая платформа агентов, рынок данных, сеть вывода, децентрализованный вычислительный слой или протокол владения моделью. Некоторые из них продуманные. Многие - просто нарративные обертки. Инвесторы и пользователи устали, даже если все еще гонятся за следующим вращением.
Итак, OpenLedger нужно доказать, что его ключевой механизм действительно имеет значение.
Не в теории.
В использовании.
Может ли кто-то построить лучшую модель благодаря OpenLedger?
Может ли участник заработать, потому что их данные действительно улучшили результат?
Может ли разработчик запустить ИИ-агента быстрее или дешевле?
Может ли пользователь доверять происхождению того, с чем он взаимодействует?
Может ли система привлечь данные, которые ни в каком другом месте не появились бы?
Вот вопросы, которые имеют значение.
И, возможно, поэтому за OpenLedger стоит следить, не увлекаясь.
Это не автоматически революционно. Это не гарантировано, что станет базовым слоем владения ИИ. Это не защищено от обычных криптопроблем спекуляции, чрезмерных стимулов и инфляции нарратива.
Но это касается реальной проблемы.
ИИ создает огромную ценность из невидимых входов. Текущая система не имеет справедливого или прозрачного способа отслеживания этих входов. OpenLedger пытается построить этот недостающий слой, используя блокчейн, логику атрибуции и токенизированные стимулы.
Это может сработать. А может и нет.
Но проблема достаточно реальна, чтобы попытка заслуживала большего, чем быстрое отклонение.
Самый чистый способ думать о OpenLedger таков: он хочет дать ИИ экономическую память.
Не просто память в смысле модели, но память о вкладе. Кто добавил данные? Кто сформировал модель? Кто построил агента? Кто заслуживает доли, когда система становится полезной?
Это убедительная идея, особенно в мире, где ИИ становится более мощным и более централизованным одновременно.
Скептик во мне все еще хочет доказательства. Реальное использование. Реальные участники. Реальные модели. Реальный спрос. Не просто кампании, очки, эмиссии токенов и скриншоты партнеров экосистемы.
Но исследователь во мне понимает, почему эта категория важна.
Если следующая фаза ИИ строится на специализированных данных и автономных агентах, то владение и атрибуция не являются побочными функциями. Они становятся инфраструктурой.
OpenLedger ставит на это.
И после того, как прочитаете достаточно белых книг, чтобы понять, как часто эти вещи сваливаются в шум, эта, по крайней мере, оставляет вопрос, который застревает:
\u003ct-87/\u003e\u003cm-88/\u003e\u003cc-89/\u003e