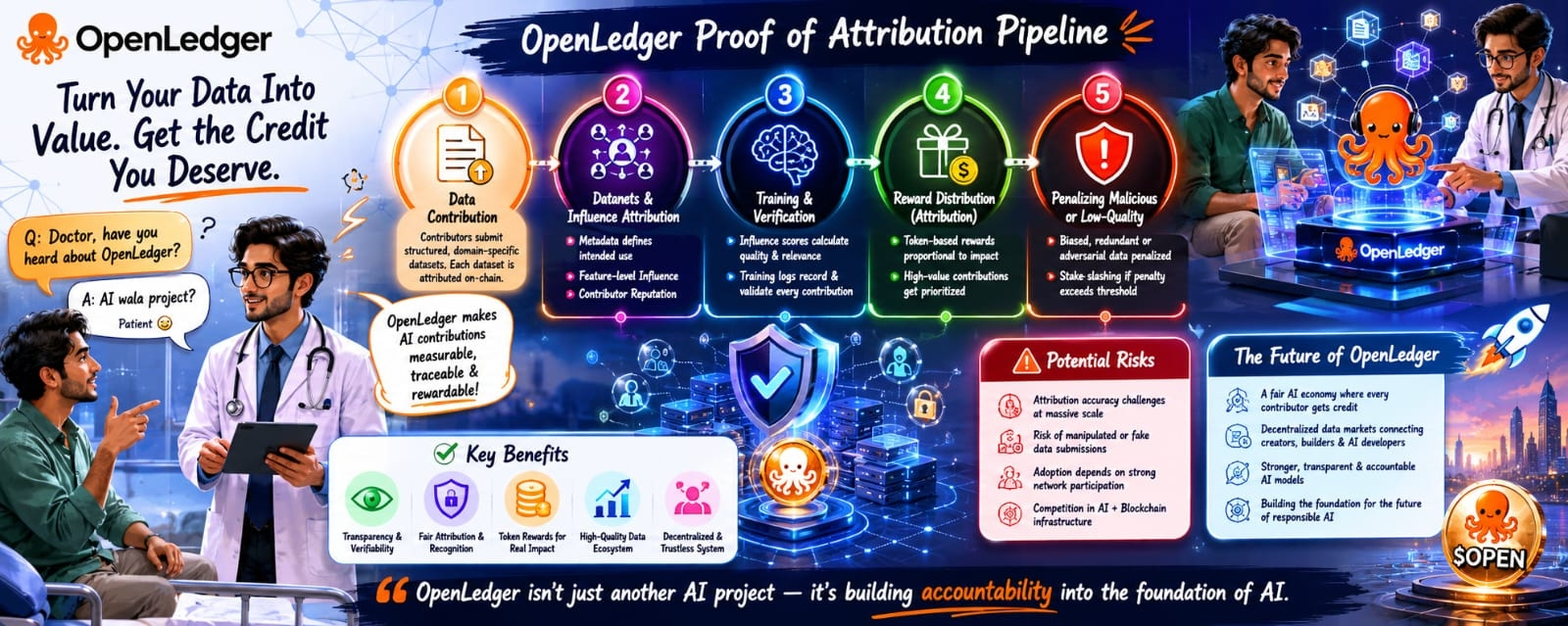

Некоторые разговоры остаются в памяти дольше, чем ожидаешь.
Несколько дней назад я рано уехал в больницу в загруженный утренний сменный день. Дороги были необычно тихими, и, честно говоря, я уже думал о отчетах по пациентам, назначениях и длинном графике впереди. Как и в любой обычный день, я думал, что самые главные обсуждения будут происходить в операционных или консультационных кабинетах.
Но, к удивлению, один из самых интересных разговоров о ИИ и блокчейне произошел в палате пациента.
Во время обычного осмотра один из моих постоянных пациентов заметил, как я пролистываю статьи о крипте на своем телефоне, ожидая отчеты.
Он улыбнулся и спросил меня:
«Доктор, вы слышали о OpenLedger?»
Я посмотрел на него и небрежно ответил: «Проект по ИИ?»
Он сразу кивнул.
Этот один маленький вопрос медленно превратился в глубокое обсуждение о том, как строятся системы ИИ, кто на самом деле вносит в них вклад и почему большинство участников никогда не получают признания.
Пациент объяснил что-то, что действительно привлекло моё внимание.
«Сегодня модели ИИ обучаются с использованием огромных объемов данных от людей повсюду. Но может ли кто-то действительно доказать, чьи данные помогли модели стать умнее?»
Честно говоря, этот вопрос остался у меня в голове.
Потому что чем больше я об этом думал, тем логичнее это звучало.
Большинство ИИ-систем сегодня работают как невидимые черные ящики. Данные поступают, модели обучаются, выходят результаты, но участники полностью исчезают из процесса. Никто не знает, какие наборы данных создали наибольшую ценность или повлияли на конечный интеллект.
Вот здесь разговор переключился на OpenLedger и его систему Протокола Атрибуции.
Я спросил его напрямую: «Так что делает OpenLedger отличным от других ИИ проектов?»
Он ответил очень простым ответом:
«OpenLedger пытается сделать вклад в ИИ измеримым, прослеживаемым и вознаграждаемым.»
И честно говоря, это объяснение упростило всё.
Идея OpenLedger кажется удивительно практичной, как только ты её правильно поймешь.
Когда участники предоставляют структурированные наборы данных для обучения ИИ, эти вклады связываются в блокчейне. Вместо того чтобы становиться невидимыми после отправки, данные остаются проверяемыми и навсегда записанными.
Проще говоря, OpenLedger пытается ответить на важный вопрос:
Кто на самом деле помог обучить интеллект?
Эта концепция сама по себе кажется мощной.
По мере того как мы продолжали обсуждение, возникла еще одна интересная тема: атрибуция влияния.
Я спросил его: «Но как система знает, действительно ли данные были полезными?»
Он объяснил, что OpenLedger измеряет влияние на уровне характеристик. По сути, сеть оценивает, насколько конкретный набор данных способствует улучшению выходных данных модели.
Это меняет всю структуру стимулов.
Обычно системы ИИ вознаграждают масштаб. Чем больше данных, тем больше важности.
Но OpenLedger, похоже, сосредоточен на вознаграждении качества и актуальности.
Участники с надежными историческими подачами и более сильными репутациями со временем получают более высокий авторитет. Ценные наборы данных получают лучшие вознаграждения, в то время как низкокачественные вклады становятся менее важными.
На этом этапе даже я начал видеть, почему эта архитектура важна для будущего децентрализованного ИИ.
Но у каждой системы есть риски.
Поэтому, естественно, я задал следующий вопрос:
«Что мешает людям загружать спам, манипулированные или предвзятые наборы данных только для того, чтобы фармить вознаграждения?»
Это, вероятно, была самая важная часть нашего разговора.
OpenLedger включает в себя штрафные системы для злонамеренных вкладов. Если наборы данных помечаются как враждебные, избыточные или вредные, участники могут столкнуться с уменьшением доли и снижением будущих вознаграждений.
Честно говоря, я думаю, что этот механизм необходим.
Потому что децентрализованный ИИ без ответственности может быстро стать опасным.
Как врачи, мы уже понимаем, насколько чувствительна целостность данных. Даже небольшие неточности в системах здравоохранения могут создать серьезные последствия. Та же логика применима к инфраструктуре обучения ИИ.
Хороший интеллект не может быть построен на ненадежной информации.
Пациент затем сказал что-то, что действительно заставило меня на мгновение задуматься.
«Доктор, в будущем данные могут стать более ценными, чем труд сам по себе.»
Эта фраза казалась глубже, чем просто обсуждение крипты.
Поскольку ИИ быстро развивается, и в конечном итоге атрибуция станет серьезной проблемой в глобальном масштабе. Компании, создатели, исследователи и участники все захотят доказательства того, как был построен интеллект и кто заслуживает экономической ценности от этого.
OpenLedger, похоже, позиционирует себя на это будущее.
Конечно, проект все еще несет неопределенность.
Оценка атрибуции в масштабах трудно осуществима. Измерять влияние внутри крупных ИИ-систем нелегко даже для централизованных компаний с огромными ресурсами. Адаптация — это еще одна проблема, потому что децентрализованные экосистемы могут преуспеть только тогда, когда достаточно разработчиков и участников активно участвуют.
Конкуренция внутри криптоинфраструктуры ИИ также быстро растет.
Но, несмотря на риски, я думаю, что основная идея OpenLedger кажется действительно важной.
Что меня больше всего впечатлило, так это не хайп, маркетинг или спекуляции по ценам.
Это была архитектура.
Проект пытается внести прозрачность в индустрию, где участники обычно невидимы. Вместо того чтобы рассматривать данные как бесплатное топливо для систем ИИ, OpenLedger рассматривает их как измеримую экономическую ценность.
И честно говоря, после того разговора в больнице, я начал по-другому смотреть на инфраструктуру ИИ.
Иногда самые значимые обсуждения не происходят на конференциях, торговых площадках или научных мероприятиях.
Иногда они происходят тихо во время обычного осмотра в больнице, когда один простой вопрос неожиданно открывает дверь в гораздо большее будущее.
