В последние несколько дней я изучал архитектуру openledger, в основном пытаясь понять, решает ли система на самом деле проблему координации вокруг данных ИИ — или она все еще находится на стадии "токенизируй участие сначала, а спрос выясняй позже", в которую многие проекты криптоинфраструктуры скатываются.
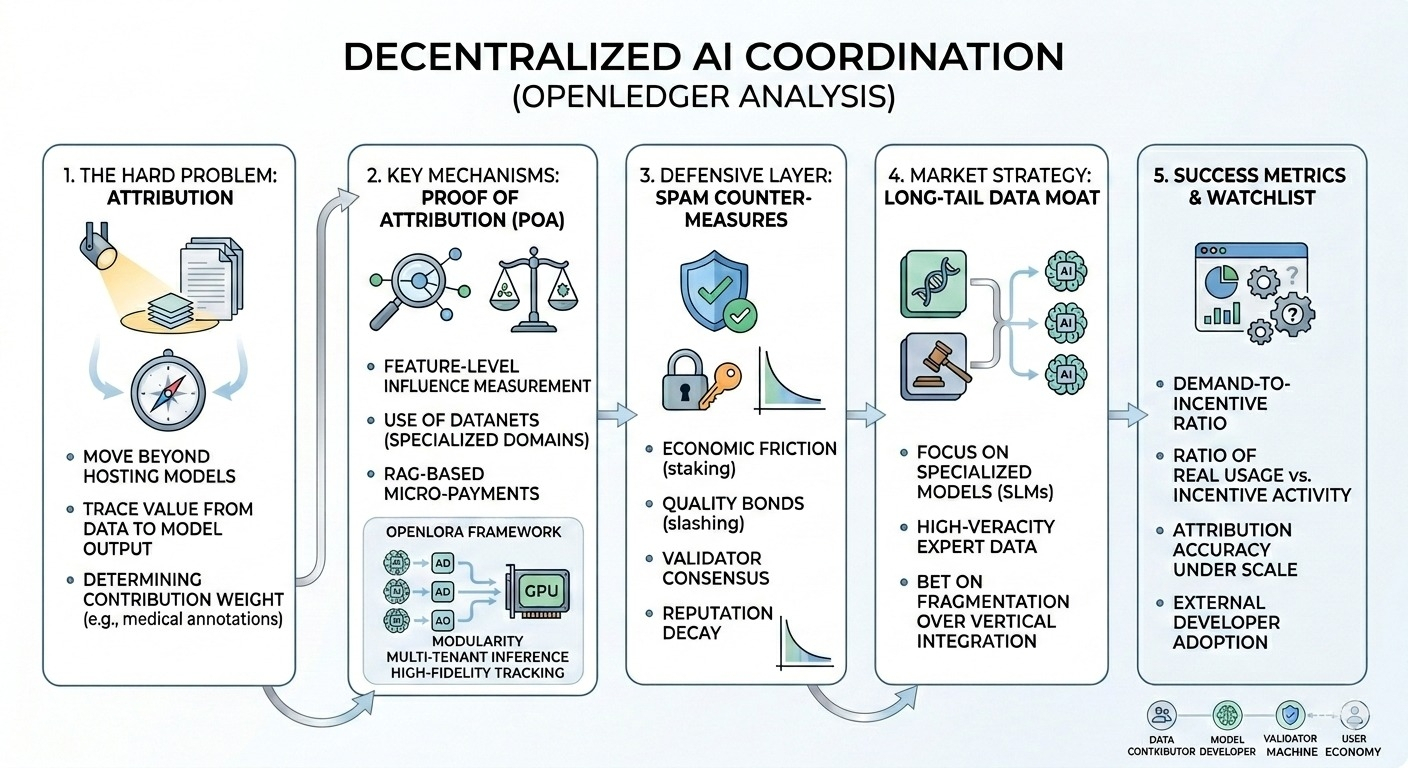
многие люди воспринимают openledger просто как очередной токен на основе ИИ и крипты, но, честно говоря, это кажется слишком поверхностным. То, что привлекло мое внимание, на самом деле, не сам токен, а попытка построить систему атрибуции вокруг децентрализованного вклада данных, а затем связать эту атрибуцию с созданием ценности модели на нижнем уровне.
это гораздо более сложная системная проблема, чем просто размещение моделей в блокчейне.
основная идея, по крайней мере, с точки зрения моего понимания, заключается в том, что участники предоставляют наборы данных, взаимодействия с моделями или входные данные, связанные с выводами, в сеть, и протокол пытается отслеживать происхождение и использование с течением времени. если модель получает выгоду от набора данных, оригинальные участники теоретически вознаграждаются через стимулы, учитывающие атрибуцию.
и это та часть, о которой я всё время думаю: вся архитектура зависит от того, чтобы атрибуция оставалась надежной в больших масштабах.
потому что как только вы выходите за пределы небольших курируемых наборов данных, граница между «ценным вкладом» и «фоновым шумом» становится очень размытым. особенно в системах ИИ, где результаты являются вероятностными, а модели усваивают информацию диффузно. Отслеживание создания ценности через тысячи или миллионы точек данных звучит чисто теоретически, но на практике это кажется неразберихой.
например, представьте, что участники вносят специализированные аннотации медицинских изображений в децентрализованный слой данных. если ИИ-модель, обученная на этих данных, позже станет коммерчески полезной, как именно протокол определяет вес вклада? частота использования? уникальность? влияние на производительность в дальнейшем? существует реальный риск, что атрибуция станет либо чрезмерно упрощенной, либо дорогостоящей для поддержания.
тем не менее, я думаю, что openledger по крайней мере нацелен на правильный уровень стека.
вместо того чтобы конкурировать напрямую по качеству моделей, они, похоже, больше сосредоточены на инфраструктуре вокруг координации ИИ — наборы данных, стимулы, происхождение, верификация и экономическая маршрутизация между участниками. в странном смысле это напоминает мне меньше традиционную блокчейн-сеть и больше попытку построить бухгалтерскую инфраструктуру для распределенных интеллектуальных систем.
динамика рынка тоже интересна. протокол подразумевает, что будет устойчивый спрос на внешние данные ИИ и модульный доступ к моделям. возможно, это произойдет. возможно, более мелкие специализированные модели в конечном итоге будут нуждаться в децентрализованных длинных наборах данных, которые централизованные платформы не могут легко получить или проверить.
но предположение, лежащее в основе всего этого, заключается в том, что будущее развитие ИИ станет более фрагментированным, а не более вертикально интегрированным.
я пока не полностью уверен.
потому что если крупные поставщики моделей продолжают поглощать большую часть экономической ценности внутри — обучение, вывод, распределение и обратные связи — тогда децентрализованные рынки взносов могут столкнуться с трудностями в привлечении значимого спроса вне нишевых случаев использования.
слой стимулов также кажется хрупким на ранних этапах. Эмиссия токенов может запустить участие на некоторое время, но в конечном итоге участники должны верить, что вознаграждения связаны с реальной утилитой сети, а не спекулятивным обращением. В противном случае система рискует оптимизироваться для объема, а не для сигнала.
и децентрализованные системы данных чрезвычайно уязвимы к спам-стимулам.
если участники получают вознаграждения за загрузки или взаимодействия, низкокачественные синтетические данные становятся неизбежными, если только уровни верификации не будут необычайно сильными. openledger, похоже, осознает эту проблему по тому, как они структурируют логику атрибуции и валидации, но я все равно задаюсь вопросом, выдержат ли эти фильтры, когда стимулы станут экономически значимыми.
ещё одна вещь, к которой я постоянно возвращаюсь: кто на самом деле создает ценность здесь?
это участник, поставляющий необработанные данные? валидатор, проверяющий происхождение? разработчик модели, интегрирующий наборы данных в удобные системы? слой вывода, генерирующий повторяющийся спрос?
протокол пытается координировать их всех одновременно, что амбициозно, но также создает перекрытие стимулов, которое может стать нестабильным со временем.
я не думаю, что ответ пока очевиден. и, возможно, это нормально.
в данный момент архитектура больше напоминает развивающийся экономический эксперимент по координации, чем окончательный уровень инфраструктуры. что, честно говоря, делает его более интересным для наблюдения.
наблюдая:
* улучшится ли точность атрибуции при масштабировании
* соотношение реального использования модели к деятельности, основанной на стимулах
* механизмы контроля качества для предоставленных наборов данных
* создают ли внешние разработчики реальный спрос на основе сети
я думаю, открытым вопросом является то, нуждается ли децентрализованная инфраструктура ИИ действительно в координации на базе блокчейна — или же токеновые стимулы просто временно заполняют пробел, пока не появится реальный рыночный спрос.