
в последнее время изучаю архитектуру openledger, в основном пытаясь понять, действительно ли сеть решает долгосрочную координационную проблему вокруг данных ИИ — или она все еще находится на той ранней стадии крипты, где стимулы приходят раньше реального спроса.
многие думают, что openledger — это просто еще один токен на основе ИИ + блокчейна. Честно говоря, это выглядит как наименее интересный способ взглянуть на это.
что привлекло мое внимание, так это попытка построить систему, где вклады в данные ИИ могут быть атрибутированы, проверены и экономически связаны с использованием моделей downstream. Не просто хранение наборов данных где-то в децентрализованной сети, а попытка создать реальный учетный слой вокруг того, кто внес ценность в систему ИИ.
это гораздо более сложная задача, чем кажется на первый взгляд.

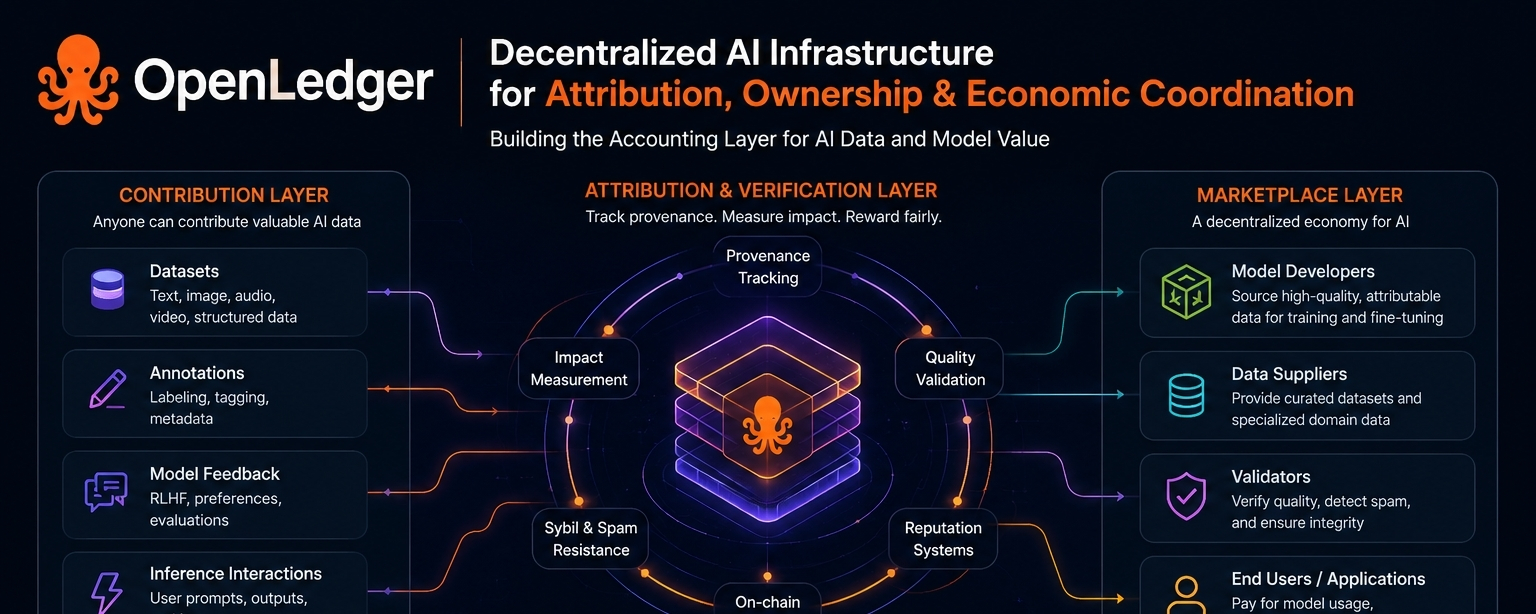
архитектура, похоже, вращается вокруг нескольких ключевых элементов. первым является децентрализованный слой внесения данных. участники предоставляют наборы данных, аннотации, обратную связь по моделям или взаимодействия, связанные с выводами, в сеть. теоретически это создает более широкий запас обучающих входов, чем одна централизованная труба могла бы собрать эффективно.
а затем есть механизм атрибуции, который, вероятно, является самой важной частью. openledger, похоже, строит инфраструктуру для отслеживания происхождения и измерения того, как взносы влияют на модели с течением времени. участники вознаграждаются на основе этого слоя атрибуции, который и является местом, где стимулы токенов входят в систему.
третий уровень — это динамика рынка сама по себе. разработчики моделей, поставщики данных, валидаторы и конечные пользователи должны взаимодействовать через общую экономическую координацию. теоретически разработчик, создающий специализированную медицинскую модель, мог бы получать проверенные данные изображений через сеть, в то время как участники получают компенсацию, связанную с фактическим использованием или влиянием модели.
и это та часть, о которой я все время думаю: атрибуция в AI системах по своей природе размыт.

модели не поглощают ценность в чистом линейном виде. если десять тысяч участников предоставляют языковые примеры, а одна подгруппа немного улучшает производительность, как это точно измерить? частота использования не обязательно равна важности. уникальность имеет значение, но также важны контекст, время и поведение модели внизу.
честно говоря, протокол, похоже, предполагает, что атрибуция может стать достаточно детализированной, чтобы поддерживать доверие между участниками. может быть, это и так, но это кажется открытой исследовательской задачей, так же как и инфраструктурной.
также есть вопрос о долговечности стимулов.
на ранних стадиях вознаграждения токенами могут запустить участие. участники загружают данные, потому что сеть платит им за это. но в долгосрочной перспективе вознаграждения должны поступать из реального экономического спроса — сборы за использование модели, рынки вывода, интеграции с предприятиями, что-то реальное. в противном случае система рискует стать замкнутой, где эмиссия создает активность, которая выглядит как движение, но не связана с устойчивой полезностью.
риск спама также кажется неизбежным.

всякий раз, когда вы финансово вознаграждаете взносы, люди начинают оптимизировать количество вместо сигнала. низкокачественные синтетические данные, дублированные наборы данных, автоматизированные взаимодействия — все это в конечном итоге попадает в систему, если уровень верификации не является необычно сильным. openledger, похоже, осознает это по тому, как он подчеркивает происхождение и валидацию, но масштабируемость — это сложная часть. модерация и контроль качества становятся трудными без отката к централизованному контролю.
большое предположение, лежащее в основе сети, заключается в том, что экосистемы AI будущего станут более модульными и распределенными. openledger в основном ставит на то, что разработчики захотят открытую, атрибутируемую инфраструктуру данных, вместо того чтобы полагаться исключительно на закрытые внутренние системы.
я пока не полностью уверен ни в одном, ни в другом.
если крупные поставщики AI продолжат вертикально интегрировать свои собственные потоки данных, циклы обучения и каналы распределения, децентрализованные координационные слои могут оставаться нишевыми. но если спрос фрагментируется на более мелкие специализированные модели, которые требуют внешних источников данных и прозрачного происхождения, тогда такие сети, как openledger, начинают выглядеть более логично структурно.
наблюдаю:
* улучшится ли точность атрибуции при масштабировании
* соотношение реального спроса на модель к стимуляции фермерства
* деградация качества или сопротивление спаму в наборах данных участников
* изменятся ли вознаграждения в конечном итоге от эмиссии токенов к доходам, основанным на использовании
здесь нет чистого вывода. openledger может строить полезную инфраструктуру для координации AI до того, как рынок полностью сформируется. или он может обнаружить, что дизайн стимулов сам по себе не может создать устойчивый спрос.

