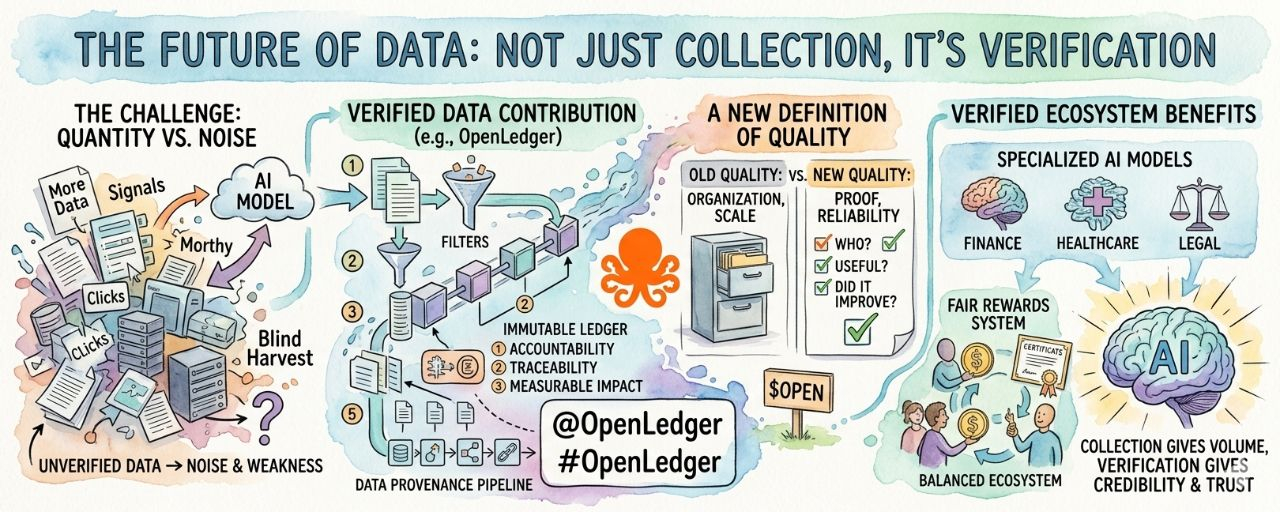
Долгое время я верил, что главное преимущество в технологиях заключается в наличии большего объема данных. Больше пользователей, больше кликов, больше записей, больше разговоров, больше сигналов. Куда ни глянь, компании соревновались в сборе информации в огромных масштабах, как будто количество само по себе может создать интеллект. Но чем больше я изучал, как современные AI-системы на самом деле развиваются, тем больше я осознавал, что данные сами по себе уже недостаточны. Огромное количество информации может казаться ценным снаружи, но если никто не знает, откуда она пришла, насколько она надежна или действительно ли она улучшила модель AI, то эти данные медленно становятся шумом вместо ценности.
Именно поэтому такие проекты как @OpenLedger становятся все более важными в будущем инфраструктуры ИИ. Что делает #OpenLedger интересным для меня, так это то, что он фокусируется на том, что индустрия отчаянно нуждается, но часто игнорирует: проверенный вклад данных. Вместо того чтобы рассматривать данные как бесконечный ресурс для слепой добычи, OpenLedger вводит идею о том, что каждый вклад должен иметь ответственность, прослеживаемость и измеримый эффект. На мой взгляд, это меняет весь разговор вокруг искусственного интеллекта.
Сегодня интернет уже производит больше информации, чем любая система может полностью обработать. Проблема не в нехватке. Проблема в доверии. Можем ли мы проверить, откуда поступил набор данных? Можем ли мы доказать, улучшила ли определенная информация модель или ввела ли предвзятость? Могут ли участники получать справедливую награду за предоставление полезного знания? Эти вопросы становятся критически важными, потому что ИИ углубляется в финансы, здравоохранение, автоматизацию, образование, исследования и принятие решений. Если данные, питающие эти системы, не могут быть проверены, то доверие к результатам всегда останется ограниченным.
Вот где, я думаю, направление OpenLedger становится мощным. Проект не просто говорит о росте ИИ. Он решает проблему отсутствующего слоя прозрачности за развитием ИИ. Идея о том, что участники, строящие модели и экосистему, могут работать в рамках проверки, создает гораздо более прочную основу, чем текущая система, где массивные платформы собирают информацию с очень небольшой ответственностью.
Одно, что меня лично интересует, это то, как проверка полностью меняет значение «высококачественных данных». В старых системах качество в основном означало организацию, форматирование, масштаб или актуальность. Но в дальнейшем качество также будет означать доказательство. Кто внес информацию? Было ли это полезно? Улучшило ли это результаты? Было ли это надежно со временем? Эти вопросы становятся жизненно важными для систем ИИ, которым люди действительно доверяют.
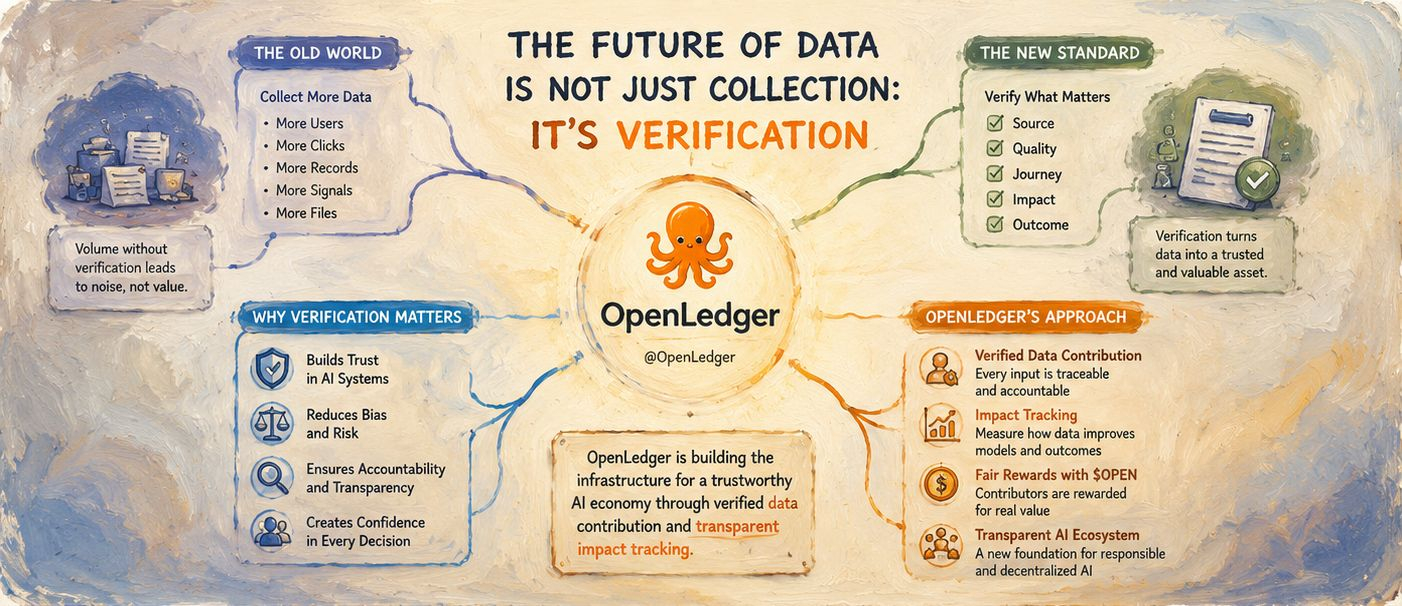
Для меня OpenLedger представляет собой этот переход от простой сборки данных к ответственности за данные. Это похоже на сдвиг от старой модели интернета, где платформы бесконечно поглощают информацию, не измеряя должным образом вклад или надежность. Вместо этого проверенные экосистемы ИИ создают структуру, где данные имеют контекст, историю, собственность и измеримую ценность.
Я также думаю, что это имеет значение, потому что будущая экономика ИИ, скорее всего, станет чрезвычайно специализированной. Разные отрасли потребуют различных моделей, обученных на высоконадежной информации. Финансовый ИИ не может позволить себе слабые наборы данных. Здравоохранение ИИ не может полагаться на неопределенные источники. Юридическая автоматизация не может функционировать на непроверяемой информации. Во всех этих областях способность отслеживать и проверять каналы данных становится более важной, чем просто увеличение масштаба.
Вот почему я верю, что такие проекты как @OpenLedger могут стать все более актуальными по мере развития инфраструктуры ИИ. Следующее поколение платформ ИИ может не быть теми, у кого самые большие сырые наборы данных. Это могут быть системы, которые действительно могут доказать достоверность и полезность знаний, которые они используют. Проверка может стать более ценной, чем сбор данных.
Еще одна причина, по которой эта идея выделяется для меня, заключается в том, что OpenLedger связывает стимулы с качеством вклада. Во многих традиционных системах участники предоставляют ценность, в то время как централизованные платформы захватывают большую часть наград. Но модели проверенного вклада создают возможность для более сбалансированной экосистемы, где полезное участие действительно может быть признано и вознаграждено. Это кажется гораздо более устойчивым для долгосрочной экономики ИИ.
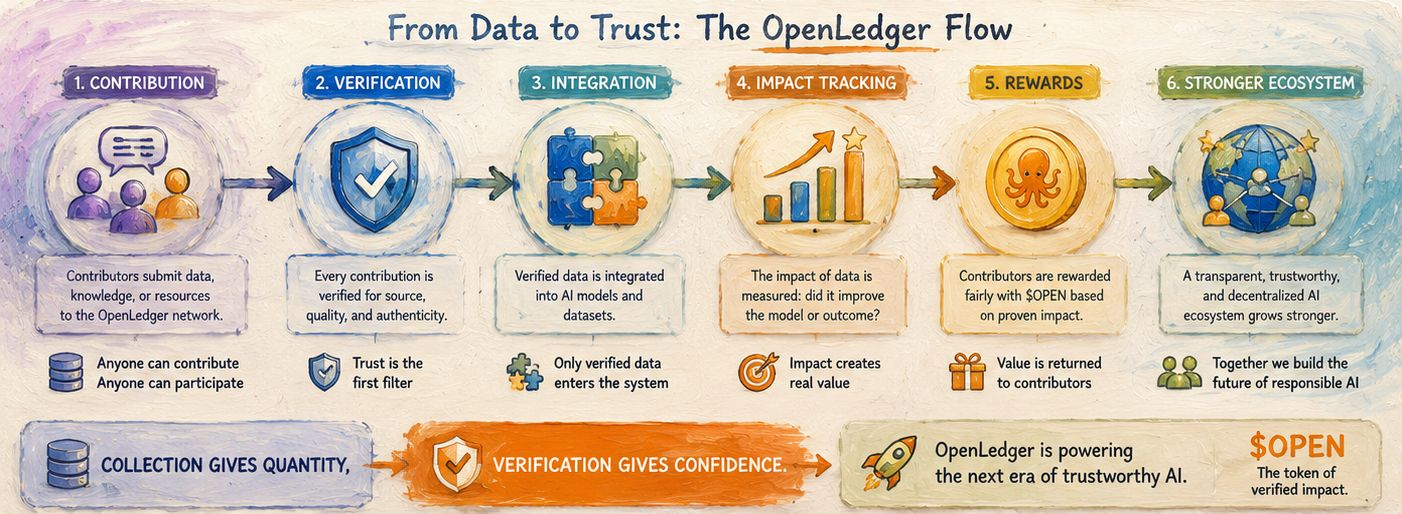
С моей точки зрения, будущее данных больше не связано с бесконечным накоплением. Интернет уже решил проблему количества. Следующий вызов — это доверие. Доверие к тому, откуда поступает информация, доверие к тому, как она используется, и доверие к тому, что системы, построенные на ее основе, можно доверять.
Вот почему концепция, стоящая за #OpenLedger кажется важной для меня. Сбор данных дает системам ИИ объем, но проверка дает им достоверность. Сбор заполняет базы данных, но проверка создает доверие. И по мере того как ИИ становится все более интегрированным в повседневную жизнь, доверие в конечном итоге станет более ценным, чем масштаб.
В конце концов, я верю, что будущее принадлежит системам, которые не просто собирают знания, но могут доказать, почему эти знания важны. Это настоящий сдвиг, происходящий в ИИ прямо сейчас, и такие проекты как #OpenLedger вместе с $OPEN занимают позицию прямо вокруг этого перехода.
#OpenLedger
$OPEN
