Искусственный интеллект сейчас ощущается как будто он бегает по кругу.
Каждую неделю появляется новый момент «большей модели». Новые бенчмарки. Новые графики. Новые объявления о финансировании, которые выглядят взрывными на X примерно на 48 часов, а затем тихо растворяются в том же фоновом шуме.
И если честно… если уставиться на это достаточно долго, что-то начинает казаться не так.
Не неправильно. Просто неполно.
Потому что всё это сосредоточено на интеллекте на поверхностном уровне. Выход. Производительность. Скорость. Какой бы ни был метрика, которая в тренде на этой неделе.
Но никто действительно не останавливается на беспорядочной части под этим.
Откуда на самом деле берется интеллект?
Не философски. Практически.
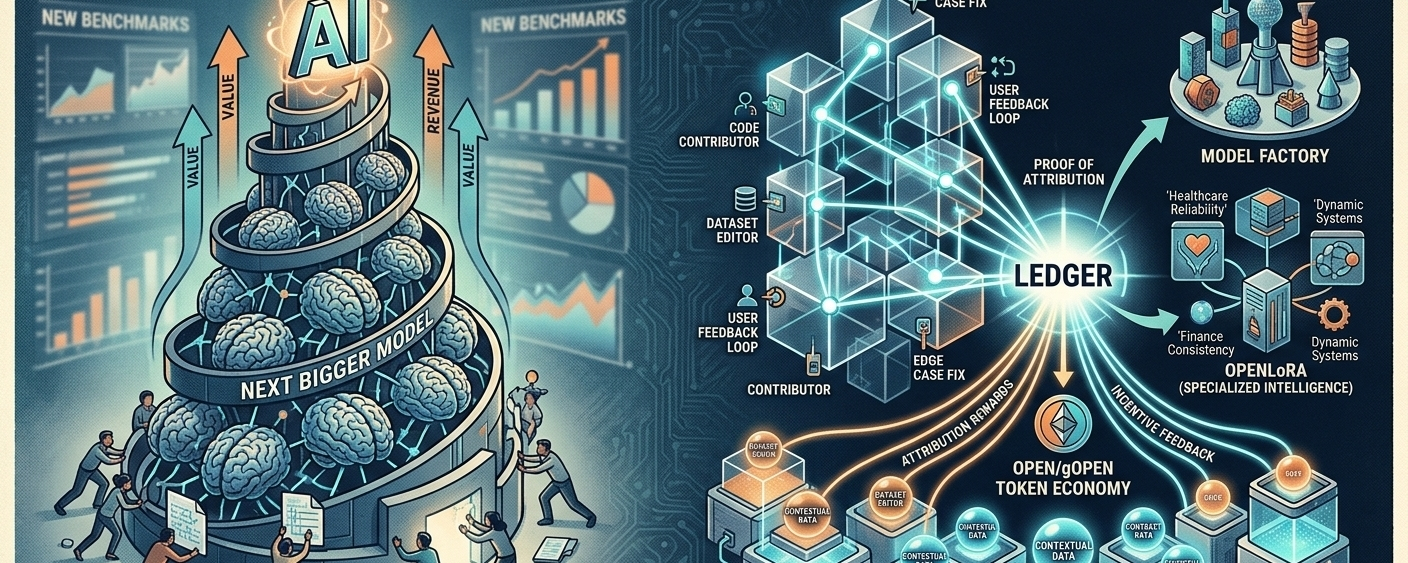
Потому что это не просто появляется. Это строится из фрагментов. Миллионов из них. Маленькие поправки, редактирование датасетов, петли обратной связи от пользователей, люди, исправляющие крайние случаи в странные часы, будучи наполовину сонными. Вклад кода, который никогда не приписывается чему-либо видимому. Целые сообщества тихо формируют системы, за которые они никогда официально не будут отмечены.
А затем ценность просто... движется вверх.
Эта часть всегда немного беспокоит меня.
Может и не должно. Но оно так и есть.
Именно здесь OpenLedger начинает ощущаться меньше как "крипто-ИИ гибрид" и больше как структурный вопрос о том, как на самом деле функционируют экономики ИИ.
Не броско. Даже не комфортно.
Просто необходимо, возможно.
Современные ИИ-системы экономически странные.
Они невероятно хороши в поглощении вклада, но почти аллергичны к тому, чтобы показать, откуда он пришел.
Данные поступают. Модели улучшаются. Продукты поставляются. Доход появляется где-то на вершине стека.
А происхождение этого улучшения? Оно размывается. Быстро.
Как будто пытаетесь вспомнить, какой конкретный ингредиент изменил вкус супа после того, как все смешано до неузнаваемости. Вы можете угадать. Вы можете воссоздать. Но вы на самом деле не знаете.
И странная часть в том, что мы это нормализовали.
Мы просто приняли, что вклад исчезнет в масштабе.
Идея "Доказательства атрибуции" OpenLedger находится прямо внутри этого слепого пятна. Она в основном задает немного неудобный вопрос:
Что если мы не позволим вкладу исчезнуть только потому, что система стала сложной?
Не как теория. Как инфраструктура.
Кто на самом деле повлиял на улучшение модели?
Какие входные данные имели значение в измеримом смысле?
И как вы направляете ценность обратно, не угадывая или слишком свободно приближая?
Эта последняя часть — это то, где все становится сложным. И интересным.
Существует тихое предположение, витая вокруг разработки ИИ:
Если модели станут достаточно хороши, все остальное будет естественно улажено.
Я не убежден.
Потому что интеллект уже не единственное ограничение.
Координация — это.
Сейчас структура выглядит примерно так:
Вычисления сосредоточены.
Данные фрагментированы.
Тренировочные цепочки централизованы.
Вклад едва отслеживается.
Ценность по умолчанию движется вверх.
И это можно масштабировать. Конечно.
Но масштабирование не исправляет дисбаланс. Оно просто делает его труднее увидеть.
Более эффективно. Более невидимо. Немного холоднее, если на то пошло.
OpenLedger кажется указывает именно на этот уровень. Не на модель. Не на выход. На систему координации под ней.
Датасети — это не просто системы хранения. По крайней мере, не так, как люди обычно думают о инфраструктуре данных.
Они ближе к структурированным средам, где данные имеют контекст, происхождение и вклад, прикрепленный к ним.
Что звучит мелко. Это не так.
Потому что большинство современных ИИ-систем обрабатывают данные как что-то, что сразу же упрощается. Как только оно попадает в цепочку, оно теряет свою идентичность. Оно просто становится топливом.
Датасети противостоят этому.
Они пытаются сохранить вклад разборчивым. Не навсегда, возможно. Но достаточно долго, чтобы это имело значение экономически.
Участники перестают быть невидимыми входами.
Они становятся частью продолжающегося поведения системы.
Я не думаю, что люди полностью понимают, насколько это отличается пока.
OpenLoRA предназначен для облегчения адаптации модели, более модульной, менее болезненной для развертывания в различных средах.
Но настоящий сдвиг в том, что это подразумевает.
ИИ не движется к одному универсальному слою интеллекта, который решает все чисто.
Он движется к специализации.
Разные области. Разные ограничения. Разные модели поведения.
Здравоохранение не хочет "общего интеллекта." Ему нужна надежность в условиях ограничений. Финансы хотят стабильности в условиях волатильности. Игры хотят динамических систем, которые не нарушают баланс.
Такая вариация плохо масштабируется с монолитными моделями.
Так что OpenLoRA продвигается к чему-то более фрагментированному, более адаптируемому.
Меньше одного мозга.
Больше распределенных слоев интеллекта, которые можно формировать.
ModelFactory находится где-то между инфраструктурой и доступностью.
Не в смысле "каждый строит фронтирный ИИ за пять минут." Это фантазия.
Больше похоже на… сокращение расстояния между идеей и используемой моделью, не разрушая сложность, необходимую для правильного выполнения.
И этот баланс сложен.
Слишком открыто, и все становится шумом.
Слишком закрыто, и инновации застревают на верхушке.
Большинство систем выбирают один экстремум. ModelFactory пытается этого не делать.
Посмотрим, как это развернется. Я немного скептически настроен, но также любопытен.
Оба могут быть правдой.
Токены обычно обсуждаются слишком много, так что я буду держать это приземленным.
OPEN и gOPEN функционируют как экономический слой внутри OpenLedger.
Управление. Награды за атрибуцию. Использование инфраструктуры. Хостинг моделей. Платежи за вывод.
В основном: как ценность движется, когда вклад измеряется.
И это «однажды» здесь очень много работает.
Потому что без реальной атрибуции системы токенов просто становятся финансовыми оболочками вокруг существующей централизации.
С атрибуцией они становятся механизмами расчета для распределенного вклада.
Это та самая ось.
Все зависит от этого.
Давайте будем честными. Большинство этого может провалиться. Некоторые части, вероятно, так и будет.
Но если даже сама основная идея атрибуции становится реальной внутри ИИ-систем, структура меняется заметным образом.
Без этого ИИ стремится к:
централизованная ценность
невидимый труд
слабая обратная связь стимулов
избыточная зависимость от нескольких инфраструктурных игроков
С этим что-то другое становится возможным:
вклад становится измеримым
узкая экспертиза получает экономическую видимость
системы становятся более модульными
участие на самом деле имеет значение в ощутимом смысле
Не идеально. Не утопично.
Просто… больше согласуется с тем, как реальные системы обычно ведут себя, когда они честны по поводу входов.
Я продолжаю думать о том, как странно, что мы построили системы, способные учиться у миллионов людей… не признавая при этом большинство из них никаким значимым образом.
Это эффективно. Конечно.
Но это также кажется немного незавершенным таким образом, что его трудно игнорировать, как только вы это замечаете.
OpenLedger находится в этом неудобном промежутке.
Не решая вопрос интеллекта. Не конкурируя за превосходство модели.
Просто задаю более тихий вопрос, который не совсем вписывается в обычный цикл хайпа:
Кто на самом деле создал этот интеллект, на который мы продолжаем полагаться… и почему этот ответ по-прежнему в основном невидим?
И да, я не думаю, что этот вопрос легко уйдет.
