Недавно у меня был небольшой момент сомнения, когда я думала о AI-агентах.
Дело не в том, могут ли они писать, трейдить, исследовать, кодить или автоматизировать задачи. Эта часть уже видна. Мое сомнение было более базовым: если AI-система принимает решение, используя данные другого человека, модель другого человека и агента третьей стороны, кто получает деньги, кто несет ответственность и кто может доказать, что на самом деле произошло?
Этот вопрос звучит скучно по сравнению с демо. Но скучные вопросы часто являются тем местом, где начинается настоящая инфраструктура.
Проблема не в интеллекте, а в учете
Большинство обсуждений ИИ сосредоточены на качестве выходных данных. Полезен ли ответ? Быстрая ли модель? Эффективен ли агент?
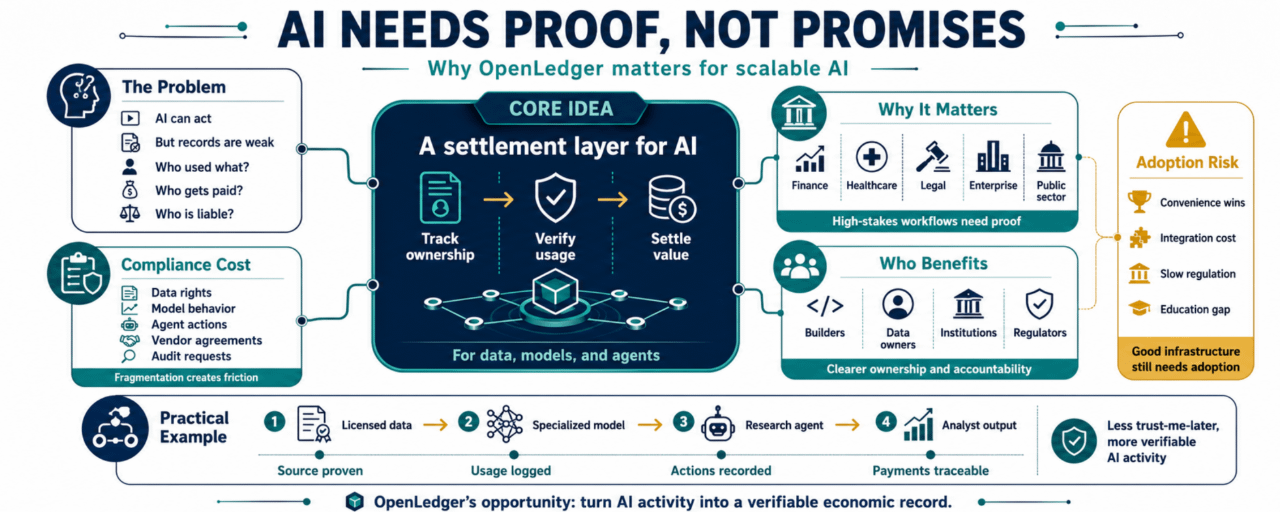
Но как только ИИ-системы попадают в серьезные рабочие процессы, качество выходных данных - это лишь одна часть проблемы. Бизнес, строители, пользователи, институты и регуляторы будут заботиться о следе за выходными данными.
Какой набор данных обучил модель? Были ли данные лицензированы? Получил ли владелец модели ценность? Выполнил ли агент задачу правильно? Был ли расчет автоматическим или ручным? Может ли компания доказать соблюдение позже?
Сегодня многие ИИ-системы все еще зависят от доверия между платформами, владельцами данных, разработчиками моделей и пользователями. Это может работать в небольших окружениях. Это становится сложнее, когда ИИ переходит в финансы, здравоохранение, юридические исследования, автоматизацию бизнеса и рабочие процессы государственного сектора.
На этом этапе "ИИ так сказал" недостаточно. Кому-то нужны записи. Кому-то нужна подотчетность. Кому-то нужен расчет.
Почему соблюдение становится проблемой стоимости
Соблюдение часто обсуждается как юридическая галочка, но на практике это также является центром затрат.
Если компания использует инструменты ИИ в больших масштабах, ей может потребоваться пересмотреть права на данные, отслеживать поведение модели, отслеживать действия агента, управлять соглашениями с поставщиками и отвечать на вопросы от аудиторов или регуляторов. Ничто из этого не бесплатно. Чем более фрагментированным становится стек ИИ, тем сложнее понять, откуда пришла ценность и где лежит ответственность. $PLAY
Здесь централизованная инфраструктура ИИ может показаться неполной. Платформа может предлагать удобство, но удобство не всегда создает переносимые доказательства. Если записи остаются внутри базы данных одной компании, другие участники должны либо доверять этой компании, либо строить собственный процесс проверки.
Это создает трение. Строители ждут одобрений. Институты замедляют принятие. Пользователи теряют видимость. Регуляторы видят черный ящик.
Где может вписаться OpenLedger
Это тот момент, когда @OpenLedger becomes становится для меня интересным.
OpenLedger не просто пытается сделать ИИ более доступным. Более важная идея заключается в том, что данные, модели и агенты могут стать экономическими активами с отслеживаемым владением и потоками ценности. Если это сработает, то инфраструктура ИИ начнет выглядеть меньше как закрытый уровень приложения и больше как уровень расчетов для интеллекта.
$OPEN , в этом контексте, не просто токен, о котором люди упоминают во время кампании. Это представляет более широкий вопрос: может ли деятельность ИИ иметь проверяемую экономическую запись?
Для строителей это может означать создание агентов или моделей, которые не застревают внутри одной платформы. Для владельцев данных это может означать монетизацию полезных наборов данных, не исчезая в чью-то учебную цепочку. Для институтов это может создать более ясные следы аудита. Для регуляторов это может предложить лучший способ инспекции того, что произошло, не требуя доверия к каждой частной базе данных.
Это не решает всего автоматически. Но это указывает на реальный пробел в инфраструктуре.
Практический пример
Представьте себе агента финансовых исследований, используемого инвестиционной компанией.
Агент получает рыночные данные, читает лицензированные исследования, использует специализированную модель и производит сводку для аналитиков. В традиционной настройке несколько вещей неясны. Использовал ли агент одобренные источники? Были ли поставщики данных компенсированы? Разрешена ли модель для этого рабочего процесса? Может ли компания показать след аудита, если позже возникнут вопросы?
С инфраструктурой, такой как OpenLedger, рабочий процесс может стать более прозрачным. Источник данных, вклад модели, действия агента и потоки платежей могут быть записаны более проверяемым способом. Строители могут получать оплату за полезные модели. Поставщики данных могут получать ценность, когда их данные используются. Институт может уменьшить некоторую неопределенность соблюдения, потому что система производит запись, вместо того чтобы полагаться только на внутренние журналы.
Это не гламурно. Но это то, что серьезным пользователям может действительно понадобиться.
Человеческая сторона доверия
Люди часто предполагают, что лучшая технология автоматически приводит к принятию. Я в этом не уверен.
Институты движутся медленно, потому что ошибки дорого стоят. Регуляторы задают вопросы, потому что возможен общественный вред. Строители хотят свободы, но также хотят получать справедливую оплату. Пользователи хотят удобства, но не хотят, чтобы их использовали. Владельцы данных хотят выгоды, но не хотят терять контроль. $ALT
Возможности OpenLedger связаны с этими человеческими поведениями. Если он сможет сделать владение, использование и расчет более понятными, это может уменьшить социальное трение вокруг принятия ИИ.
Самая сильная инфраструктура обычно исчезает в рабочих процессах. Люди не думают о платежных системах каждый раз, когда они проводят карту. Точно так же инфраструктура расчетов ИИ может быть наиболее важной, когда пользователи не должны думать об этом каждую секунду.
Риск - это трение при принятии
Основной риск заключается в том, что рынок может не заботиться достаточно быстро.
Многие пользователи все еще выбирают удобство вместо прозрачности. Многие компании предпочитают закрытые системы, потому что могут контролировать маржи и данные. Некоторые строители могут избегать дополнительных этапов интеграции. Регуляторы могут действовать медленно или непоследовательно в разных регионах. И если затраты слишком высоки, даже хорошая инфраструктура может испытывать трудности.
Существует также проблема образования. "Блокчейн ИИ для данных, моделей и агентов" не является мгновенно очевидным для всех. OpenLedger должен сделать ценность практичной, а не просто технически обоснованной.
Основной вывод
Люди, которые с наибольшей вероятностью будут серьезно использовать OpenLedger, не только трейдеры, следящие за $OPEN. Это строители, которым нужна монетизация, владельцы данных, которые хотят контроля, институты, которым нужны записи, и в конечном итоге пользователи, которым важно, чтобы ИИ-системы были справедливыми и подотчетными.
Это может сработать, если OpenLedger сделает потоки ценности ИИ легче проверяемыми, расчетными и заслуживающими доверия. Это может провалиться, если принятие останется слишком техническим, слишком дорогим или слишком медленным для реальных рабочих процессов.
Вот почему я рассматриваю #OpenLedger less как историю хайпа и больше как тест на то, сможет ли инфраструктура ИИ развиться за пределы закрытых платформ и неформального доверия.
Не является финансовым советом.
Как вы думаете: будет ли принятие ИИ зависеть больше от лучших моделей или от лучших доказательств того, кто владеет, использовал и получил что?