 Я постоянно возвращаюсь к простой напряженности в крипте и ИИ: нам говорят, что децентрализованные системы будут вознаграждать вклад, но вещи, которые на самом деле создают ценность — данные, метки, настройка, обратная связь и невидимый труд кураторства — все равно исчезают на заднем плане. OpenLedger интересен мне, потому что он не притворяется, что это противоречие ново. Он начинает с него. Фрейминг проекта заключается в том, что большая часть ИИ работает за закрытыми дверями, с неясным происхождением и слабым признанием людей, чьи данные сформировали результат. В этом смысле OpenLedger — это не чистое изобретение, а серьезная попытка ответить на повторяющийся вопрос, который преследует весь бум ИИ: кто, собственно, должен получать оплату, когда модель оказывается полезной?
Я постоянно возвращаюсь к простой напряженности в крипте и ИИ: нам говорят, что децентрализованные системы будут вознаграждать вклад, но вещи, которые на самом деле создают ценность — данные, метки, настройка, обратная связь и невидимый труд кураторства — все равно исчезают на заднем плане. OpenLedger интересен мне, потому что он не притворяется, что это противоречие ново. Он начинает с него. Фрейминг проекта заключается в том, что большая часть ИИ работает за закрытыми дверями, с неясным происхождением и слабым признанием людей, чьи данные сформировали результат. В этом смысле OpenLedger — это не чистое изобретение, а серьезная попытка ответить на повторяющийся вопрос, который преследует весь бум ИИ: кто, собственно, должен получать оплату, когда модель оказывается полезной?
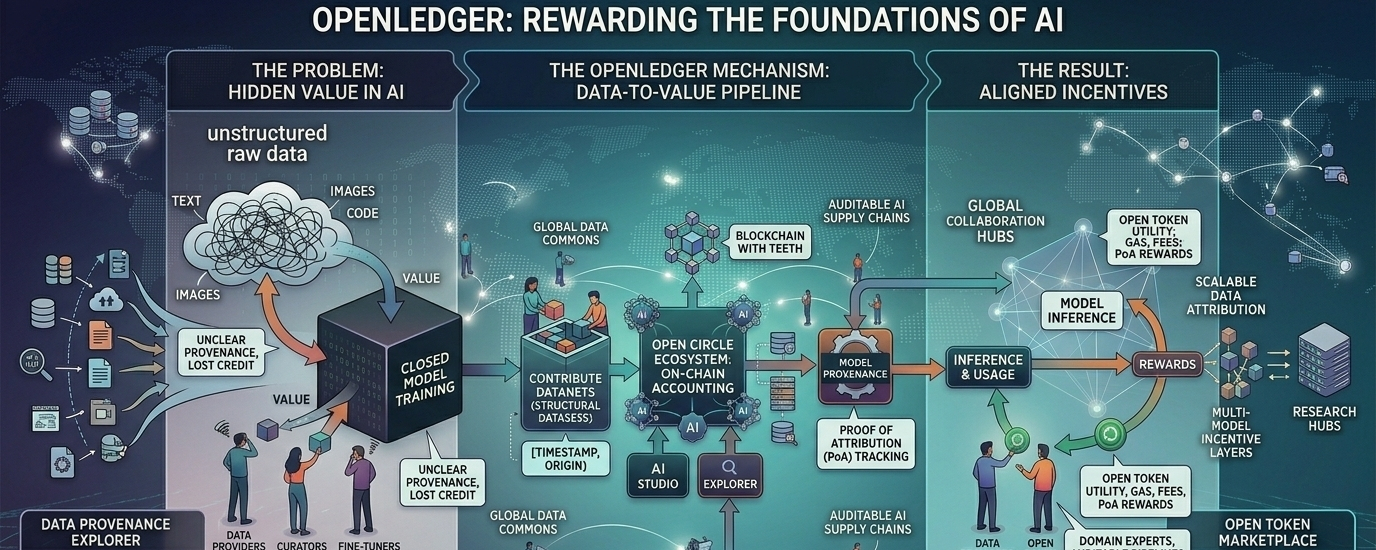
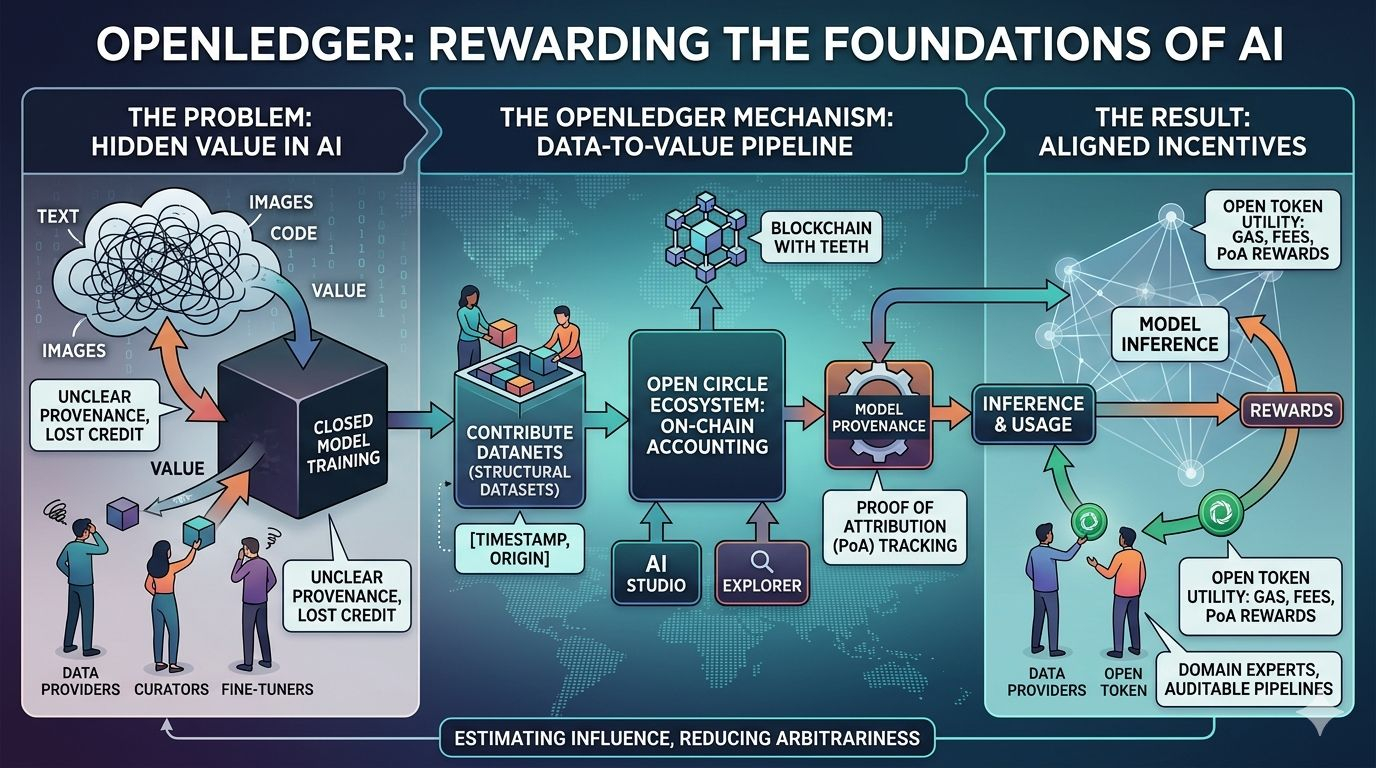
Этот вопрос снова возник, потому что старые ответы никогда полностью не удерживались. Открытые рынки для данных могут размещать активы, но они редко делают конечное использование понятным. Лицензии могут регулировать доступ, но не каждое заключение. Аудиторские следы могут фиксировать события, но не всегда назначать значительный кредит. Даже когда строители AI хотели быть более осторожными, структура современных моделей затрудняла отслеживание одного вклада к одному выходу с уверенностью. Белая книга OpenLedger достаточно откровенна по основной проблеме: вкладчики данных обычно отключены от ценности, которую создают их данные, и не было широко принятого механизма, чтобы признать или вознаградить их. Этот разрыв — не только этический, но и структурный.
То, что предлагает OpenLedger, это альтернативная структура, а не универсальный блокчейн с темой AI, прикрепленной сверху. Проект описывает себя как AI-блокчейн, построенный специально для данных, моделей и агентов, и его материалы многократно подчеркивают, что он не пытается быть всем для всех. Логика уже узкая: если AI собирается стать программируемым экономическим слоем, тогда происхождение его входов, родословная его моделей и распределение его вознаграждений должны быть родными для стека, а не добавляться позже. Я читаю это как аргумент, что полезная роль блокчейна здесь — это не абстрактная децентрализация, а бухгалтерия с зубами.
Основной механизм называется Proof of Attribution, и здесь проект становится более техническим, чем его маркетинговый сленг. В июньской статье 2025 года OpenLedger говорит, что система использует два метода атрибуции: приближения функции влияния для меньших моделей и атрибуцию токенов на основе префиксного массива для больших языковых моделей. Данные организованы в то, что они называют DataNets, которые представляют собой структурированные наборы данных, предоставленные одним или несколькими пользователями и зафиксированные с метаданными и временными метками. Модели затем регистрируют происхождение обучения относительно этих DataNets, чтобы выводы можно было связать с данными, которые на них повлияли, и вознаграждения могли быть распределены соответственно. Это амбициозный дизайн и также раскрывающий, потому что показывает, насколько трудно действительно решить проблему атрибуции: одного метода недостаточно, поэтому системе необходимо переключать инструменты в зависимости от масштаба модели.
Мне кажется, что двойной метод выглядит многообещающим и слегка беспокойным. Многообещающим, потому что он признает практическую реальность: атрибуция в компактной специализированной модели — это другая проблема, чем атрибуция в языковой модели на переднем крае. Беспокойным, потому что это также подразумевает, что система не находит идеальную причинно-следственную истину; она оценивает влияние в разных рамках. Это не критика, уникальная для OpenLedger. Это природа атрибуции в машинном обучении. Но это имеет значение, потому что система вознаграждений, основанная на уровне влияния, работает только так хорошо, каковы ее предположения. Если атрибуция слишком грубая, вкладчики могут быть переоценены или недооценены. Если она слишком затратная в вычислительном плане, система становится трудной для функционирования в больших масштабах. Элегантная часть OpenLedger в том, что она признает проблему. Сложная часть в том, что проблема не исчезает.
Язык продукта вокруг проекта пытается превратить эту теорию в рабочий процесс. Собственные страницы OpenLedger ссылаются на AI Studio, Explorer, Staking и экосистему Open Circle, в то время как блог о «10-миллиардных долларовых приложениях» описывает стек, где владение данными, доказательство атрибуции, создание моделей без кода и расширения RAG и MCP объединяются в прозрачную среду для построения моделей. Проще говоря, предполагаемый поток достаточно знаком: вносите данные в датасет, создавайте или настраивайте модель, развертывайте ее, а затем позволяйте использованию влиять на атрибуцию и оплату. Интересная часть заключается в том, что OpenLedger хочет, чтобы этот цикл был виден в блокчейне, а не скрыт внутри внутренней бухгалтерии закрытой платформы.
Дизайн токена следует той же логике. На странице токеномики фонда говорится, что OPEN является родным токеном ERC-20 для сети, с общим объемом в 1 миллиард и первоначальным обращением в 21.55%. Более важно для структуры системы, OPEN описывается как газ для сетевой активности, основной токен для уплаты сборов за выводы и создание моделей, а также механизм вознаграждений для вкладчиков данных через Proof of Attribution. В документации также говорится, что модель управления предназначена для того, чтобы напоминать управление в стиле Arbitrum, охватывая параметры протокола, обновления, передачи прав собственности и другие критически важные решения. Это последовательный дизайн, хотя и не окончательный: токен может выравнивать стимулы, но он также может импортировать обычные проблемы представительства, апатии избирателей и концентрации влияния.
Где я становлюсь более осторожным, так это в разрыве между моделью и принятием. Видение OpenLedger выглядит чисто на бумаге, но принятие в крипте редко терпит неудачу из-за того, что идея не связная; оно терпит неудачу из-за того, что трение носит операционный характер. Вкладчики данных должны достаточно заботиться, чтобы курировать структурированные наборы данных. Строители должны верить, что слой атрибуции стоит издержек. Пользователи моделей должны принять сбор на блокчейне и новую бухгалтерскую схему, а не удобство централизованного API. Управление должно оставаться значимым, не превращаясь в узкую игру, в которой участвует небольшая группа держателей токенов. И если проект хочет выйти за пределы ниши крипто-строителей, ему нужно будет доказать, что атрибуция не только философски привлекательна, но и операционно проще, чем альтернативы.
Существует также более тонкое ограничение: происхождение данных не равно их ценности. Вклад может быть отслеживаемым и все равно не заслуживать большого веса. Модель может зависеть от набора данных и при этом обобщаться таким образом, что трудно четко назначить. Логика вознаграждений в белой книге зависит от оценок влияния, но влияние по своей сути контекстно. Это делает систему справедливее, чем чистая догадка, но не делает ее абсолютно объективной. Я думаю, OpenLedger это понимает, что и является частью того, почему проект кажется более серьезным, чем многие нарративы AI-блокчейна. Он не обещает решить философию кредита в машинном обучении. Он пытается сделать кредит менее произвольным. Это значительная разница, но не окончательный ответ.
Если модель работает, то люди, которые, скорее всего, получат выгоду, это не спекулятивные трейдеры или абстрактные слоганы «сообщества», а более узкие группы: эксперты в своей области, которые могут предоставить высококачественные данные, строители, которым нужны аудируемые конвейеры моделей, и организации, которые хотят AI-системы с отслеживаемыми входами. Люди, которые могут остаться вне ее досягаемости, также важны для упоминания. Обычным пользователям, возможно, никогда не будет интересно, как работает граф атрибуции. Крупные предприятия могут предпочесть закрытые системы с более простым процессом закупки и меньшим количеством переменных управления. И многие вкладчики, даже если технически вознаграждены, могут все равно считать процесс слишком сложным или слишком косвенным, чтобы с этим заморачиваться. Другими словами, обещание OpenLedger зависит меньше от того, насколько умна архитектура, чем от того, найдут ли достаточно людей дополнительную структуру стоящей для принятия. Это гораздо более сложный тест. Что остается открытым для меня, так это то, действительно ли AI нуждается в новом экономическом слое, чтобы стать подотчетным — или подотчетность продолжит приходить только там, где у учреждений уже есть дисциплина требовать этого.