
Годы назад интернет работал по грубой, но рабочей схеме. Ты вкладывал реальные мысли в что-то — четкое объяснение, острое наблюдение, годы сопоставления паттернов в каком-то узком углу — и если это было хорошим, люди находили это. Эта видимость приносила охват, а охват иногда превращался в работу, деньги, репутацию или просто тихое удовлетворение тем, что твои усилия имели значение для кого-то. Это никогда не было совершенно справедливо, но связь между вкладом и какой-то формой вознаграждения существовала.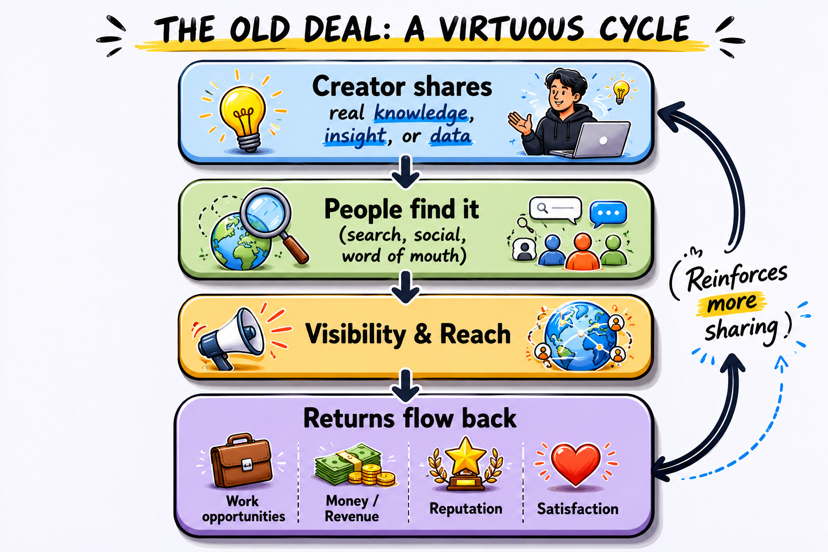
Искусственный интеллект тихо разорвал эту связь.
Теперь тот же поток или набор данных или аккуратное описание могут быть использованы в обучающих данных, формируя, как модели отвечают на вопросы для других людей, а человек, который действительно выполнил эту работу, никогда не узнает, что это произошло. Никакой кредит, никакой линк, никакой кусочек той ценности, которая была создана в дальнейшем. Знание просто поглощается, и оригинальный источник исчезает.
Масштаб делает это трудно игнорировать. Огромная доля того, что пошло в обучение многих современных крупных моделей, всё ещё поступает из публичных данных — в некоторых случаях 70-90 процентов токенов. В то же время, способ, которым люди на самом деле достигают оригинальных текстов, быстро меняется. Когда AI-сводки появляются в результатах поиска, клики по источникам резко падают. Исследования показали сокращение на 30-60 процентов в некоторых случаях. Издатели сообщили о медианном трафике из Google, снизившемся примерно на 10 процентов год к году, при этом некоторые издания наблюдают гораздо более резкие потери. Больше всего это чувствуют не крупные медиа-компании. Это независимые голоса, нишевые объяснители, те, чье преимущество исходило от глубокого знания своего предмета и четкого написания.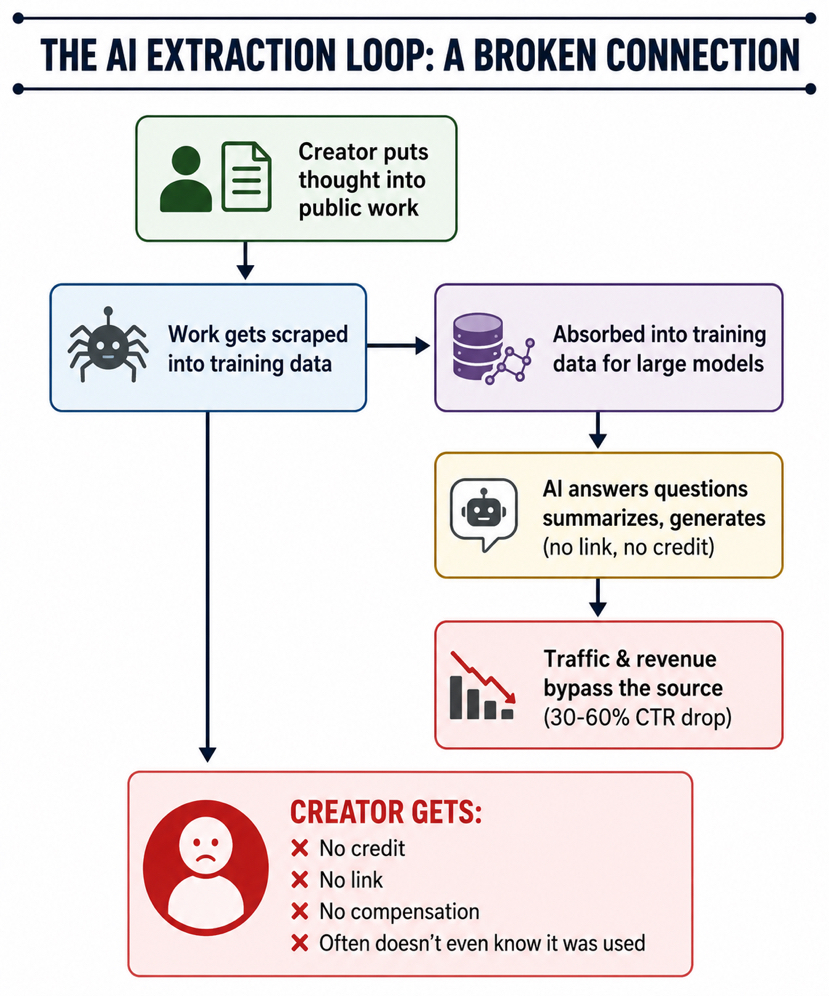
Старая система вознаграждала видимость. Новая реальность рискует вознаградить тех, кто контролирует модели, которые тихо поглотили всё остальное.
Сейчас выделяется попытка напрямую привязать вклад к компенсации. Не за счет увеличения просмотров или лайков, а отслеживая, когда конкретные данные или инсайты фактически используются в AI-системах и возвращая некоторую ценность обратно к источнику. Это небольшое изменение в логике, но оно меняет ощущение участия. Полезность снова начинает нести экономическую ценность, вместо того чтобы всё текло только к производительности финальной модели или платформам, её усиливающим.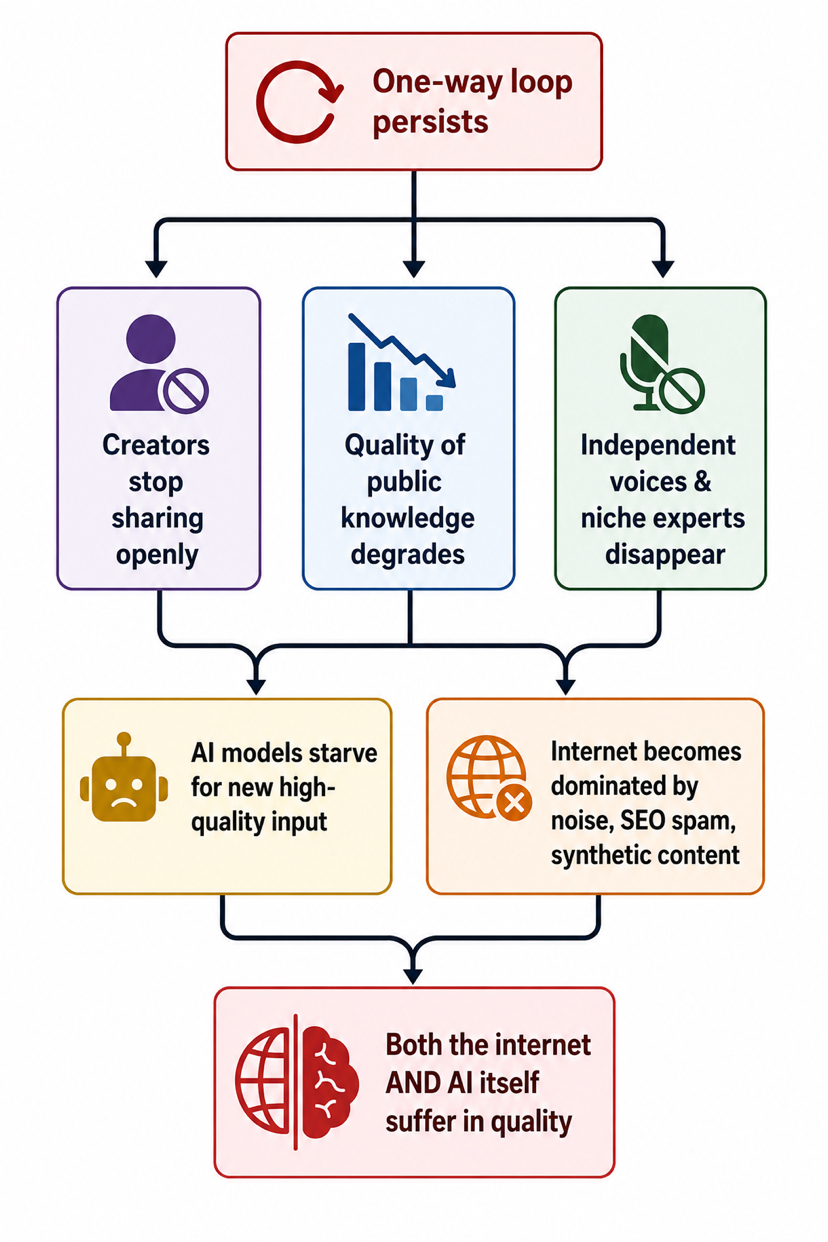
Если это направление будет развиваться, интернет может уйти от экономики, которая в основном вознаграждает за громкость и обнаружимость, к такой, где внесение реального сигнала в эти системы начинает иметь смысл само по себе. Люди, выполняющие аккуратную работу, могут на самом деле увидеть часть downstream-ценности, вместо того чтобы наблюдать, как она исчезает в модели кого-то другого.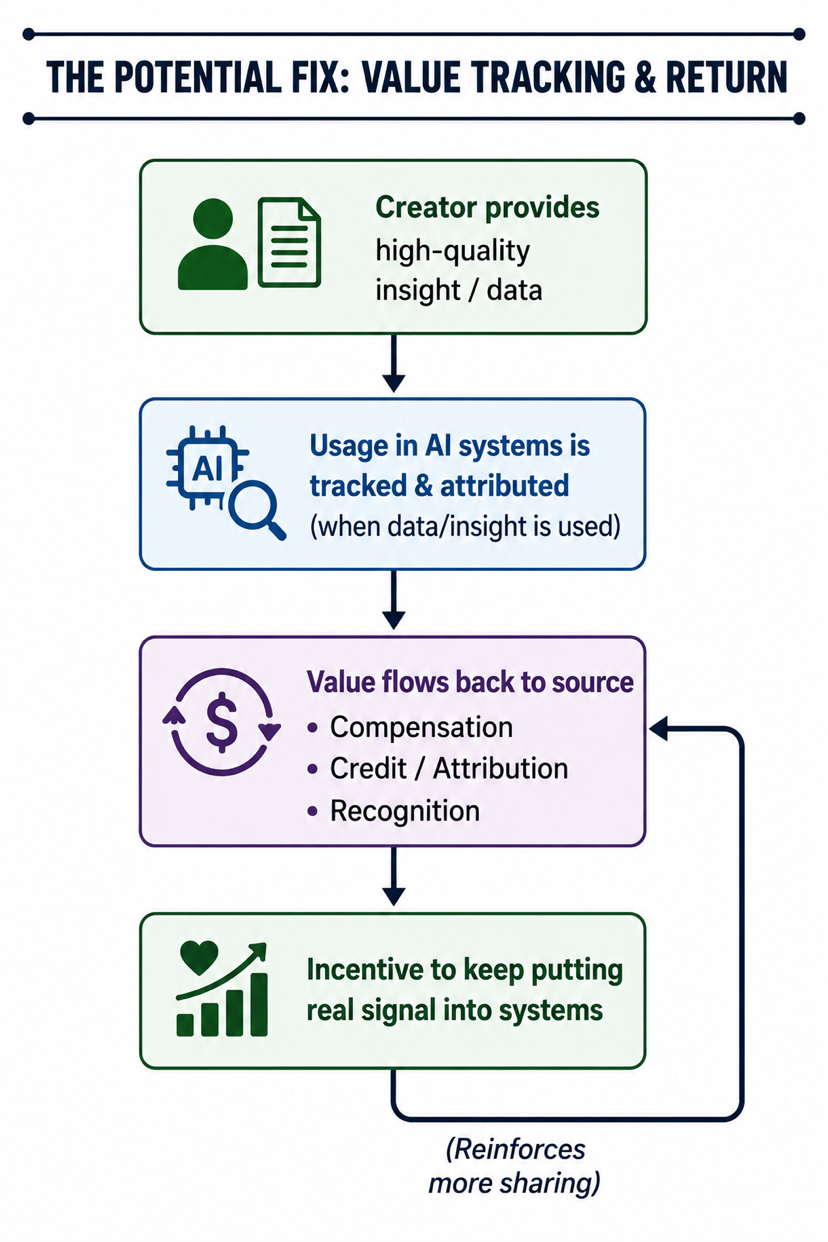
Напряжение простое. В данный момент знания самого высокого качества всё ещё могут быть извлечены при почти нулевых предельных затратах с почти никакой обратной связью для людей, производящих их. Это работает некоторое время. Но если люди, которые действительно знают вещи, решат, что цикл слишком сломан, чтобы продолжать кормить, качество того, что попадает в эти системы, в конечном итоге пострадает. Или они просто перестанут выкладывать хорошие вещи на публику.
Мы все еще на ранних стадиях. Большая часть индустрии всё ещё построена на том, чтобы захватить как можно больше. Но вопрос уже стоит: что произойдет с интернетом — и с качеством AI — если люди, которые действительно думают, перестанут видеть причину продолжать делиться этим открыто?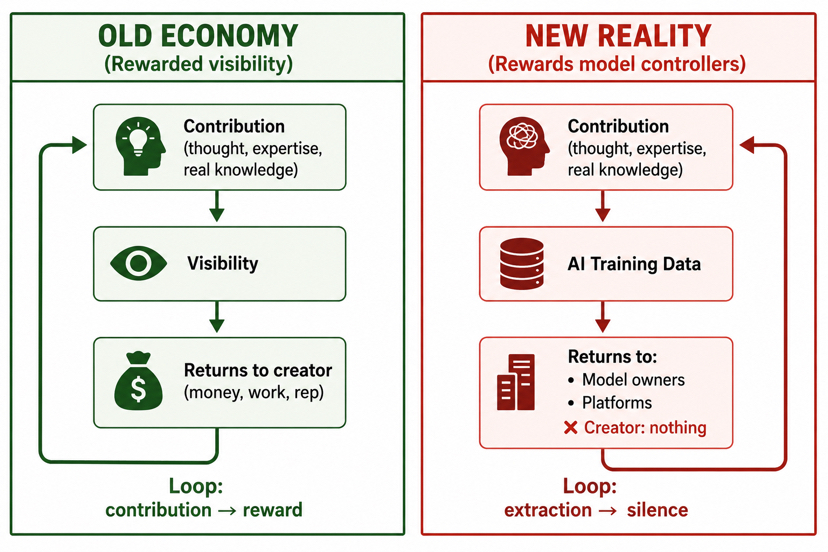
Что, по твоему, сломается первым, если этот цикл останется односторонним?
