
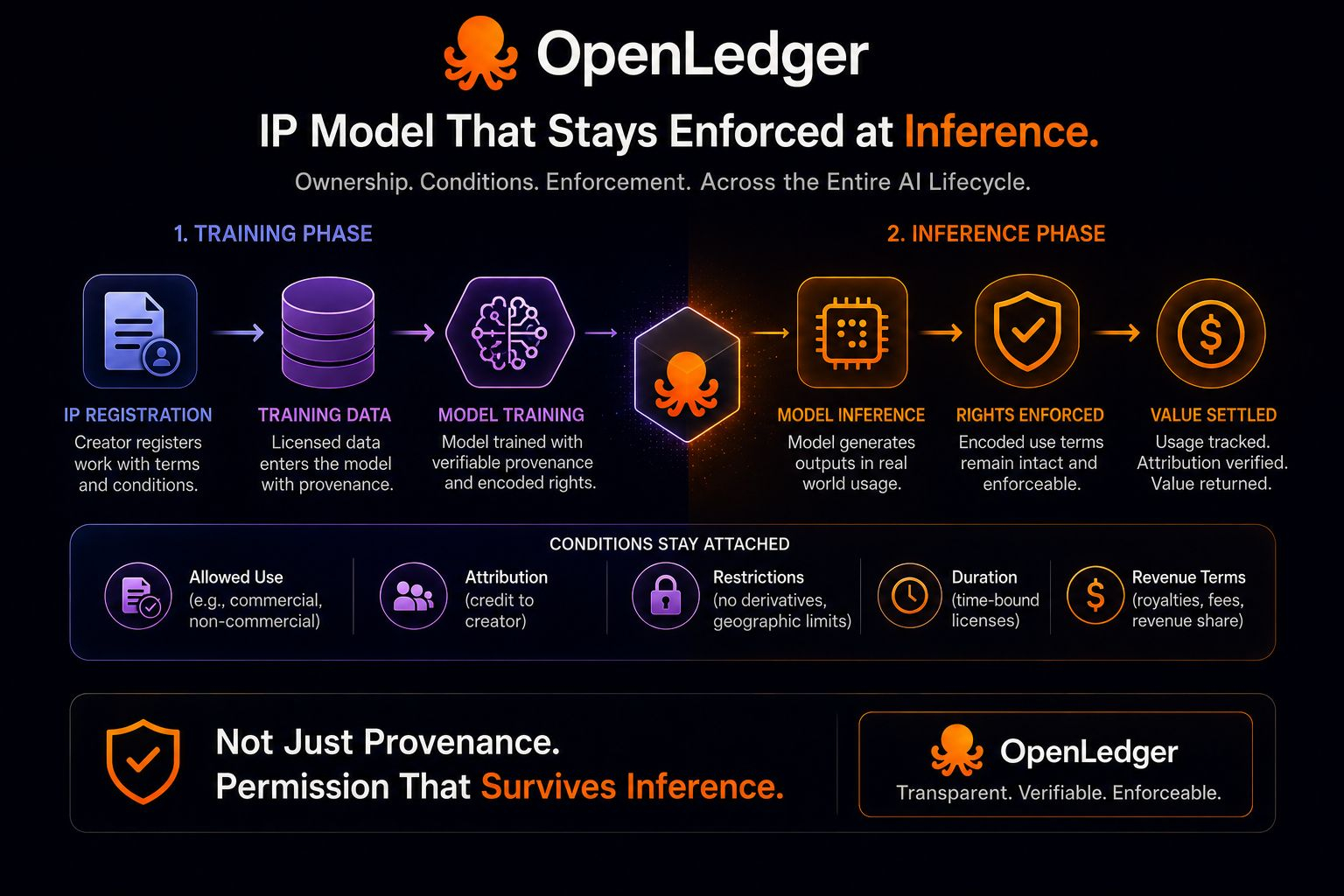
Когда я впервые прочитал о инфраструктуре ИП OpenLedger, я подумал, что основная идея заключается в происхождении.
Данные для обучения, модели и интеллектуальная собственность, входящие в ИИ-системы с привязанными правами, а не исчезающие в непрозрачных потоках. Честно говоря, это уже звучит полезно само по себе. Создатель мог бы хотя бы доказать, откуда что-то вошло в процесс и при каких условиях это стало доступно.
Сначала я считал эту точку входа сложной.
Если права собственности остаются видимыми с самого начала, если актив имеет читаемое происхождение до начала обучения, тогда система уже кажется более ответственной, чем большинство ИИ-потоков сегодня. Работа больше не начинается как анонимный ввод.
Но потом я остановился на части о кодировании разрешенного использования как в обучении, так и в выводе.
Это изменило мой взгляд на всю ситуацию.
Потому что обучение — это только один этап, где важны разрешения. Более сложный момент наступает позже, когда модель фактически используется. Вывод — это место, где генерируются результаты, принимаются решения, создается ценность, и где исходные условия, прикрепленные к работе, либо остаются значимыми, либо тихо исчезают.
Вот где утверждение OpenLedger становится гораздо более значительным, чем инфраструктура регистрации.
Чистая запись происхождения на этапе входа полезна, но сама по себе она не решает проблему координации. Правообладатель может разрешить использование своей работы в системе при определенных условиях, но если эти условия становятся нечитаемыми, как только модель начинает работать, то важная часть пути разрешений ломается именно там, где начинается экономическая активность.
И формулировка OpenLedger здесь важна, потому что она явно расширяет логику за пределы одного только происхождения. Интеграция описывается не только как отслеживание собственности вокруг обучающих данных и моделей. Она описывает разрешенное использование, остающееся закодированным как в обучении, так и в выводе вместе.
Это значит, что этап вывода не является какой-то дополнительной проблемой, добавленной позже.
Это фактическая проверка давления на то, выдержит ли структура разрешений, когда модель начнет использоваться в реальных условиях.
Чем больше я размышлял над этой идеей, тем больше OpenLedger переставал казаться мне простой регистрационной площадкой и начинал восприниматься как попытка сделать потоки разрешений ИИ понятными после развертывания, а не только до него.
И, честно говоря, это, вероятно, гораздо более сложная инфраструктурная проблема, чем большинство людей осознает на первый взгляд.
\u003cm-54/\u003e\u003cc-55/\u003e\u003cc-56/\u003e \u003cc-58/\u003e \u003ct-60/\u003e