OpenLedger — это один из тех проектов, которые я не хочу переоценивать слишком рано.
Я видел, как этот рынок перерабатывает одни и те же аргументы слишком много раз. ИИ. Данные. Владение. Награды. Децентрализация. Эти слова начинают звучать как шум со временем, особенно когда половина проектов, использующих их, никогда не проходит дальше чистой посадочной страницы и нескольких восторженных тем.
Но у OpenLedger есть одна часть, к которой я продолжаю возвращаться.
Это рассматривает неприятную сторону ИИ, которую большинство людей все еще избегает: проблема данных.
Не та проблема "ИИ нужно больше данных". Все об этом говорят. Эта часть очевидна.
Настоящая проблема в том, кто получает оплату, когда эти данные начинают создавать ценность.
Прямо сейчас ИИ кажется гигантской машиной, поглощающей все, что попадает ей на пути. Человеческие тексты, исследования, рыночные заметки, код, работы создателей, знания сообщества, случайные посты, очищенные наборы данных, грязные наборы данных — все это идет внутрь. Модель становится умнее. Продукт продается. Участник обычно не получает ничего.
Это и есть трение.
И честно говоря, здесь идея OpenLedger начинает иметь смысл. Он пытается построить систему, где данные не просто исчезают в модели ИИ, как дым. Проект хочет, чтобы у данных был след. Источник. Запись. Какая-то форма доказательства, которая говорит, да, этот вклад имел значение.
Это кажется простым, пока вы действительно не подумаете об этом.
Атрибуция ИИ — это не простая проблема. Она запутанная. Модели запутанные. Влияние данных не всегда чистое. Один кусок информации может напрямую формировать выход. Другой может только улучшить модель на заднем плане. Некоторые данные полезны. Некоторые — мусор. Некоторые скопированы с копий. Некоторые выглядят ценными, пока вы не попытаетесь их использовать.
Это та работа, с которой OpenLedger должен справляться.
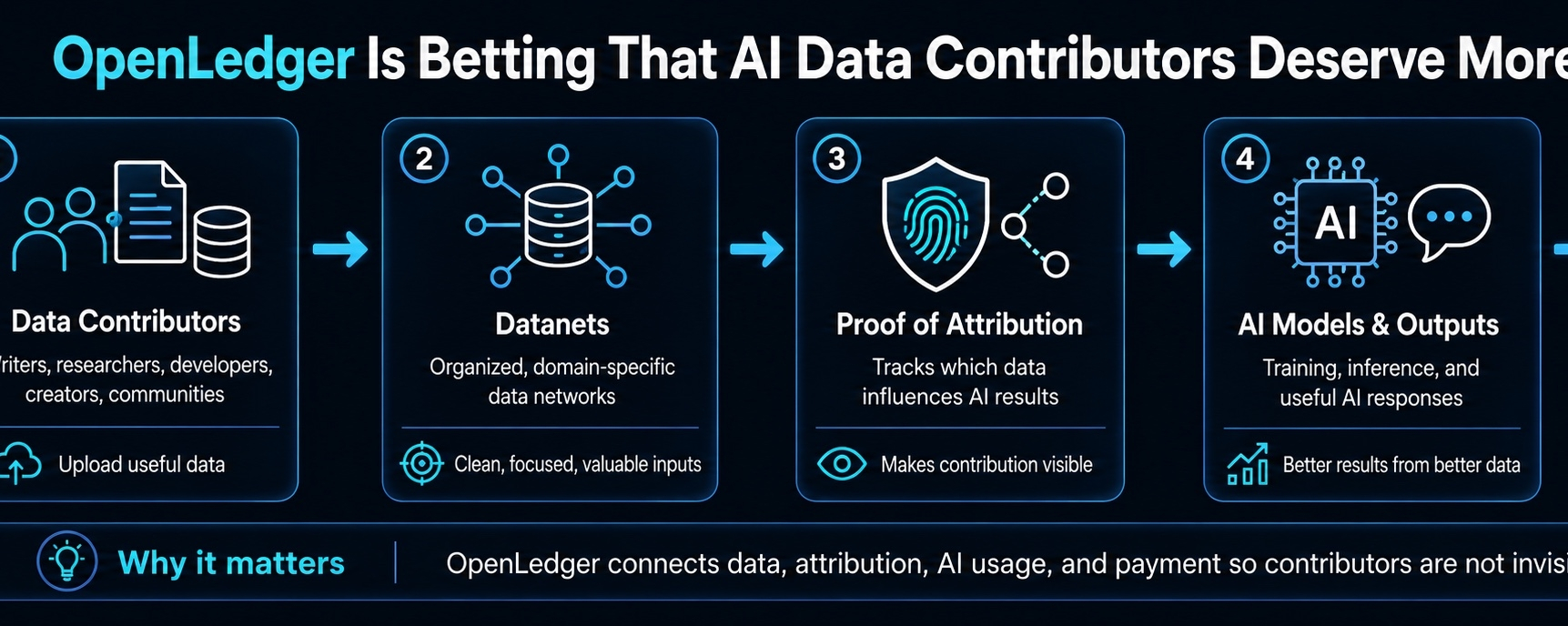
Проект использует доказательство атрибуции как свою основную идею. Цель — проследить, как данные способствуют выходам ИИ, а затем связать этот вклад с наградами. Мне нравится направление. Я не собираюсь притворяться, что это уже решено, потому что это было бы лениво. Но я действительно думаю, что это правильный вопрос.
Если ваши данные помогают ИИ модели стать лучше, почему вы невидимы?
Это действительно впечатляет.
Потому что текущая экономика ИИ в основном построена на невидимых участниках. Люди создают знания, платформы захватывают ценность, а всем остальным говорят, что так работает прогресс. Я видел то же самое в крипте. Пользователи развивают сети, сообщества привлекают внимание, ранние участники несут нагрузку, а затем выгода тихо концентрируется где-то еще.
Разные сектора. Один и тот же старый запах.
OpenLedger пытается противостоять этому, превращая вклад данных в что-то измеримое и вознаграждаемое. Не просто «загрузить и надеяться». Не просто фармить пустые очки. Сильная версия этого проекта — это когда полезные данные могут отслеживаться, ранжироваться, использоваться и оплачиваться на основе реального влияния.
Это версия, за которой стоит следить.
Слабая версия тоже легко представить. Поток низкокачественных загрузок. Люди гонятся за наградами. Наборы данных становятся шумными. Атрибуция становится слишком сложной для обычных пользователей. Строители приходят за стимулами и уходят, когда награды иссякают.
Я видел этот фильм.
Так что реальный тест — это не то, есть ли у OpenLedger хорошая идея. Она есть.
Реальный тест — это может ли система отделить сигнал от мусора.
Вот почему Датасеты важны. OpenLedger использует Датасеты как сфокусированные сети данных, а не бросает все в одну кучу. Эта часть кажется практичной. ИИ не нуждается в бесконечных случайных данных. Ему нужны чистые, полезные, специфические данные, которые действительно улучшают выход.
Модель ИИ в крипте нуждается в крипто-родной информации.
Торговый ассистент нуждается в реальной рыночной структуре.
Исследовательская модель требует чистого контекста.
Строительный инструмент нуждается в технических данных, которые не устаревают через три месяца.
Плохие данные не просто бесполезны. Они дорогие. Они тратят время, добавляют шум и ухудшают модель.
Так что если OpenLedger сможет сделать Датасеты полезными, это станет настоящим базовым слоем. Не модные слова. Не нарратив. Качество данных.
Я также наблюдаю, как участники вписываются в это.
Большинство проектов говорит о сообществе, как о декорации. Модель OpenLedger зависит от того, что участники действительно ценны. Люди приносят данные. Они помогают их организовать. Они поддерживают сеть. Они становятся частью цепочки ценности ИИ, а не сидят снаружи, хлопая, пока кто-то другой монетизирует их работу.
По крайней мере, это идея.
И это хорошая версия.
Но я больше не раздаю бесплатное доверие.
Проект, подобный этому, должен доказать, что участники могут зарабатывать что-то значимое, а не символическую пыль. Он должен доказать, что строители хотят использовать слой данных. Он должен доказать, что атрибуция может работать так, чтобы не стать еще одной черной коробкой с более красивым брендингом.
Потому что если пользователи все еще не могут понять, как движется ценность, тогда все начинает казаться слишком знакомым.
Токен OPEN находится в той же напряженности.
Если экосистема растет, если Датасети становятся полезными, если строители ИИ действительно подключаются, если вклад данных создает реальный спрос, тогда токен имеет смысл. Но если активности мало, а история остается больше, чем использование, рынок в конечном итоге устанет.
Это всегда так.
Нарративы сначала прокачивают. Использование проверяется позже. Этот разрыв — это то место, где много проектов погибает.
OpenLedger интересен тем, что он не гонится за мелкими проблемами. Владение ИИ станет более крупной борьбой, а не меньшей. Данные уже ценны. ИИ делает их еще более ценными. И как только люди поймут, что их работа помогла обучить инструменты, которые теперь с ними конкурируют, разговор станет более серьезным.
Кто владеет входными данными?
Кто зарабатывает на выходных данных?
Кто исчезает посередине?
Вот где OpenLedger пытается занять свою позицию.
Я уважаю это.
Не потому что это звучит чисто, а потому что это звучит сложно. Лучшие проблемы в крипте обычно таковы. Легкие копируются, перерабатываются и превращаются в шум за один цикл. Сложные требуют лет, выжигают людей и имеют значение только если кто-то продолжает строить через скучную часть.
OpenLedger все еще должен пройти через эту скучную часть.
Часть, где идея встречается с реальными пользователями.
Часть, где награды должны иметь смысл.
Часть, где качество данных проверяется.
Часть, где строители решают, полезно ли это или просто еще один слой, который они могут игнорировать.
Вот что я наблюдаю.
Потому что если OpenLedger сможет превратить данные из чего-то, что ИИ потребляет, в что-то, чем люди могут действительно владеть, отслеживать и зарабатывать, тогда у него есть реальный путь.