Я долгое время классифицировала OpenLedger как рынок данных. Это звучит как предложение: участники загружают данные, модели обучаются на них, участники получают оплату. Если вы понимаете проект именно так, вы не совсем неправы. Но вы упускаете более важный аспект.
Позволь мне рассказать, что изменило моё восприятие.
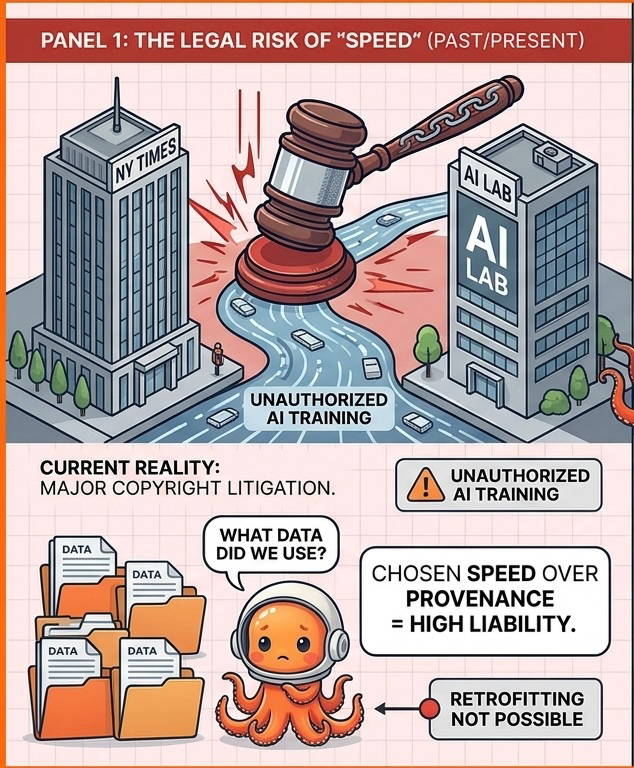
За последние 18 месяцев три крупных дела по авторскому праву в области ИИ достигли значительных юридических этапов. The New York Times подала в суд на OpenAI и Microsoft за обучение на своих статьях без лицензии или компенсации. Коалиция авторов подала в суд на Meta за аналогичные практики. Getty Images подала в суд на Stability AI за сбор миллионов лицензированных фотографий для обучения диффузионных моделей. Это не единственные дела. Они самые заметные. Основная схема остаётся неизменной: модели ИИ обучались на данных, у которых есть владельцы, и эти владельцы не получали компенсацию, не консультировались, а в многих случаях даже не были уведомлены.
Юридическая ответственность здесь не теоретическая. Суды сейчас активно работают над тем, как выглядит ответственность, и ранние сигналы показывают, что доказательства того, какие данные использовались для обучения, имеют огромное значение. Компании, которые могут продемонстрировать, на чем они обучались, с документированным происхождением, находятся в структурно лучшем положении, чем те, кто этого не может. Компании, которые могут продемонстрировать, что у них была авторизация для этих данных, находятся в еще более выгодном положении.
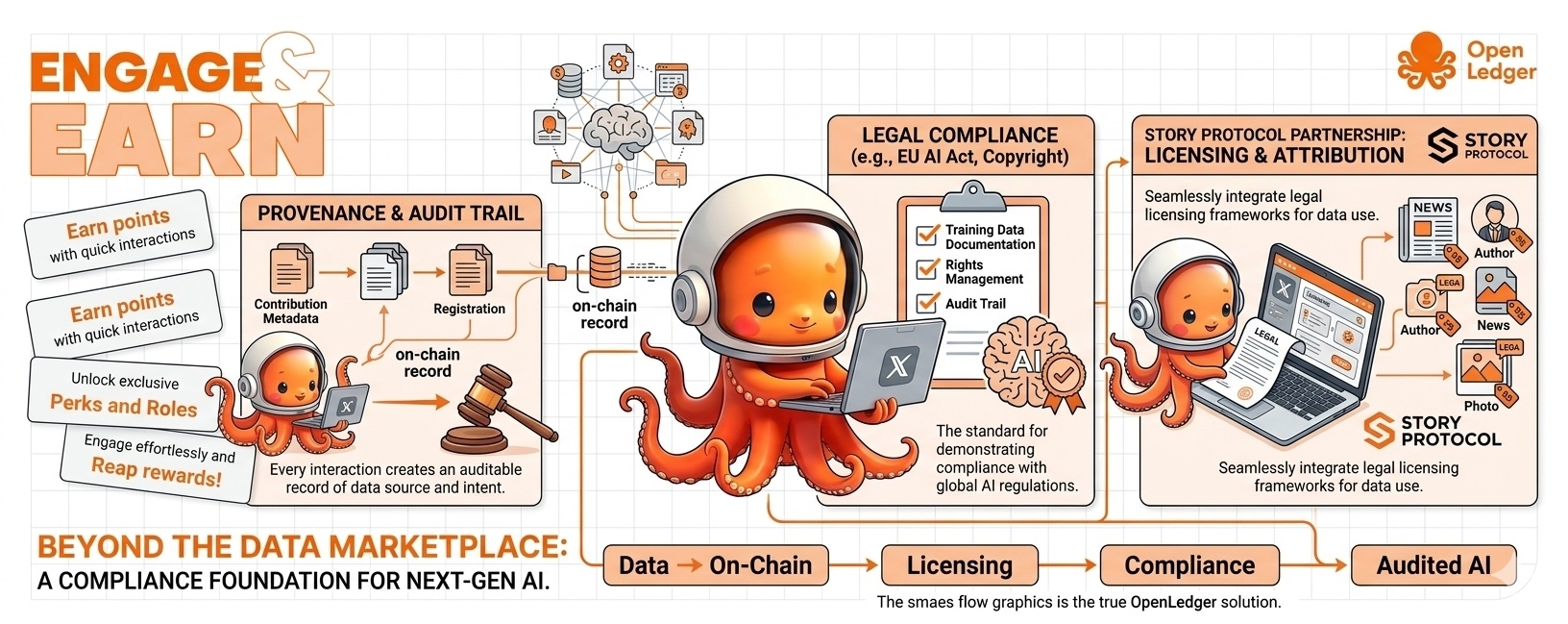
OpenLedger строит именно этот слой документации. Каждый Datanet создает ончейн-запись. Каждый вклад регистрируется с метаданными. Каждый запуск обучения на инфраструктуре OpenLedger оставляет аудируемую цепочку. Когда модель развертывается, ее происхождение можно отследить через цепочку, от вывода вывода обратно через обучение, назад к исходным данным, обратно к вкладчику, который их предоставил.
Это не маркетинговая функция. Это юридическая запись. И разница между наличием этой записи и ее отсутствием становится все более значительной с каждым месяцем.
Я хочу быть осторожным здесь, потому что я не предлагаю, что создание на OpenLedger автоматически решает риск авторского права или удовлетворяет каждое требование соблюдения норм. Атрибуция необходима, но недостаточна для соблюдения норм. Вам также нужно лицензирование, что и делает партнерство с Story Protocol важным, и вам нужны рамки управления для того, как авторизуется использование данных, которые OpenLedger все еще разрабатывает. Запись — это отправная точка, а не полный ответ.
Но вот конкурентный аргумент, который OpenLedger должен выдвигать громче: альтернатива ончейн происхождению — это не "лучше внутренней документации". Альтернатива — надеяться, что никто не подаст в суд, или соглашаться, если это произойдет. Крупные лаборатории ИИ построили свои обучающие наборы данных с такой скоростью и масштабом, что тщательное отслеживание происхождения стало невозможным. Они не выбирали плохое происхождение. Они выбрали скорость, и плохое происхождение стало следствием.
OpenLedger переворачивает это. Делая происхождение основой, а не второстепенным вопросом, любая модель, построенная на его инфраструктуре, начинает с уже установленной аудиторской цепочки. Стоимость — это накладные расходы во время обучения. Преимущество — это значительно уменьшенная юридическая ответственность в будущем.
Я был удивлен, когда впервые начал углубляться в ландшафт соблюдения норм, насколько четко архитектура OpenLedger соответствует тому, что на самом деле нужно юридическим отделам. Соглашения о использовании данных должны документировать, какие данные были использованы и на каких условиях. Аудиторские цепочки должны показывать цепочку владения. Записи атрибуции должны идентифицировать вкладчиков. Ончейн-запись не является идеальной заменой традиционной юридической документации, но она предоставляет основу, которая значительно облегчает создание этой документации.
Законодательство ЕС о ИИ, которое сейчас находится на этапе активного применения, строго требует, чтобы высокорисковые ИИ-системы поддерживали документацию обучающих данных. Это не будущее требование. Это текущее. Любая европейская компания, создающая или разворачивающая ИИ-системы в регулируемых категориях, должна иметь ответы на "на чем вы обучались и имеете ли вы на это права". Инфраструктура OpenLedger предоставляет технический слой для этих ответов.
США движутся в том же направлении, медленнее и через судебные разбирательства, а не через законодательство, но направление то же самое. Ответственность за данные обучения приближается. Вопрос в том, придет ли это до или после того, как OpenLedger займет позицию нейтрального инфраструктурного слоя для этой ответственности.
Теперь позвольте мне четко обозначить контраргумент, потому что он реален.
Организации, которым срочно нужны данные о происхождении обучающих данных, соответствующие требованиям соблюдения норм, — это те, кто строил свои модели на существующих данных, без OpenLedger. Невозможно добавить отслеживание происхождения к модели, обученной без него. Вы не можете добавить атрибуцию к решениям, принятым на основе данных, которые никогда не были атрибутированы. Проблема соблюдения норм, с которой сталкиваются эти организации, не та, которую OpenLedger может решить для их текущих моделей.
OpenLedger может решать проблему только в будущем. Для моделей, построенных в дальнейшем, на данных, внесенных через его инфраструктуру, происхождение присутствует. Для моделей, которые уже существуют в большом масштабе, проблема остается.
Это означает, что ценностное предложение OpenLedger по соблюдению норм в первую очередь актуально для разработки новых моделей, а не для устаревших систем. Это все еще большой рынок. Разработка ИИ не замедляется. Количество новых моделей, которые создаются, растет. Регуляторное давление на то, чтобы строить их ответственно, увеличивается. Тайминг обоснован.
Но проект должен быть честным в отношении этого объема. "Мы решаем проблему происхождения" и "мы решаем проблему происхождения для моделей, построенных на нашей инфраструктуре в будущем" — это разные утверждения. Второе — точное. Первое — это чрезмерное утверждение, которое снижает доверие со стороны профессионалов по соблюдению норм, которые имеют значение.
Я хочу поговорить о партнерстве Story Protocol конкретно, потому что думаю, что это элемент истории соблюдения норм OpenLedger, который большинство людей недооценили.
Story Protocol создает стандарт для юридической лицензии на творческие работы для обучения ИИ, с автоматизированными механизмами оплаты. Интеграция OpenLedger означает, что данные, внесенные через Datanets, могут быть оформлены в рамках лицензионной структуры Story Protocol, чтобы правообладатели получали компенсацию, когда их работа используется в обучении. Это сочетание решает проблему, которую ни один из проектов не мог бы решить в одиночку.
Широкая важность: большая часть ценного данных для обучения ИИ не находится в общественном достоянии. Она принадлежит журналистам, авторам, исследователям, медицинским специалистам, юридическим практикам. Эти владельцы в настоящее время не имеют механизма, чтобы сказать: "да, вы можете использовать мою работу для обучения ИИ, на этих условиях, с этой компенсацией." Story Protocol создает структуру условий. OpenLedger строит слой оплаты и атрибуции. Вместе они создают нечто, чего не существовало прежде: структуру для обучения ИИ на лицензированных, компенсированных, документированных данных.
Будут ли разработчики ИИ это принимать — другой вопрос, чем то, работает ли это. Стимул обучаться на лицензированных данных в настоящее время слабее, чем риск судебных разбирательств, в сознании многих разработчиков. Этот расчет меняется, но меняется медленно. Регуляторное принуждение, как правило, является движущей силой, которая ускоряет принятие инфраструктуры соблюдения норм, и это принуждение все еще формируется.
Что мне действительно интересно в позиции OpenLedger, так это то, что она сделала ставку на то, что момент принуждения наступит до того, как рынок закроется. Если требования соблюдения норм станут реальными и немедленными, OpenLedger — это инфраструктура, которая уже построена. Преимущество первопроходца в инфраструктуре соблюдения норм реально: как только организации строят свои рабочие процессы управления данными вокруг определенной системы, они не меняют их легко.
Я не могу уверенно сказать вам, что OpenLedger станет стандартом. Я могу сказать, что техническая инфраструктура существует, она решает реальную проблему, которая становится все более актуальной, и что большинство крипто-сообщества не рассматривает этот проект с точки зрения, которая позволила бы им увидеть его реальный потенциал.
Называть это рынком данных — все равно что называть SWIFT приложением для платежей. Технически точно, но фундаментально неверно о том, что это на самом деле.
Слой соблюдения норм строится. Вопрос в том, проявит ли рынок интерес до того, как кто-то другой создаст захваченный вариант, — это вопрос, на который у меня нет уверенного ответа.
@OpenLedger $OPEN #OpenLedger $BSB
