 Что произойдет, когда искусственный интеллект перестанет быть инструментом и начнет становиться самостоятельной экономической средой?
Что произойдет, когда искусственный интеллект перестанет быть инструментом и начнет становиться самостоятельной экономической средой?
Этот вопрос может показаться абстрактным сегодня, но структура уже тихо формируется вокруг нас. Модели ИИ больше не являются изолированными программными продуктами. Они становятся рынками данных, системами влияния, слоями автоматизации и, всё более, механизмами, через которые извлекается ценность из человеческого поведения. Каждый поисковый запрос, исправление, загрузка изображения, запрос, отзыв, аннотация и взаимодействие питают более крупные системы, которые постоянно улучшаются. Тем не менее, большинство участников этого процесса остаются экономически невидимыми.
Интернет однажды создал идею, что «данные — это новая нефть», но сравнение всегда было неполным. Нефть потребляется один раз. Данные ведут себя иначе. Их можно копировать бесконечно, комбинировать бесконечно и повторно использовать в системах, даже не зная, куда они перемещались после этого. Искусственный интеллект еще больше ускорил этот дисбаланс, потому что современные системы ИИ зависят не только от количества данных, но и от постоянного уточнения на основе коллективного человеческого взаимодействия.
Это создало странное противоречие в цифровой экономике. Системы ИИ выглядят все более интеллектуальными, но экономическая структура, стоящая за ними, остается высоко централизованной. Небольшое количество компаний обладает инфраструктурой, вычислительной мощностью и собственными каналами, необходимыми для обучения и распространения современных моделей в больших масштабах. Тем временем, участники, чья информация косвенно укрепляет эти системы, часто не получают ни видимости, ни долгосрочного участия в создаваемой позже ценности.
Блокчейн-проекты ранее пытались бросить вызов частям этой структуры. Некоторые сосредоточены на децентрализованном облачном вычислении. Другие создавали токенизированные обмены данными или рынки для ИИ-услуг. Но многие предыдущие попытки страдали от общей слабости: они рассматривали ИИ так, как будто он ведет себя как простая финансовая сеть.
Нет.
Финансовые системы перемещают балансы между счетами. Системы ИИ впитывают паттерны из миллиардов фрагментированных входных данных. Как только начинается обучение, атрибуция становится нечеткой. Один набор данных влияет на другой. Модели многократно уточняются. Выходы развиваются непредсказуемо. К тому времени, когда система ИИ становится коммерчески полезной, отслеживание значимого вклада часто становится технически неопределенным.
Вот где OpenLedger входит в обсуждение с немного другой стороны.
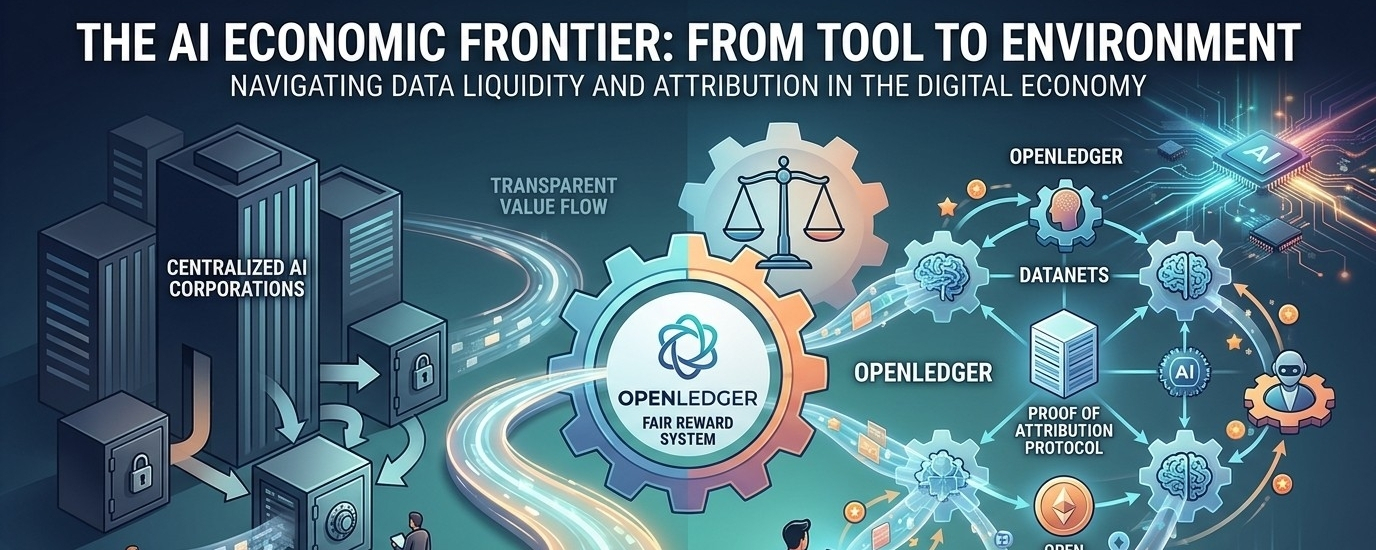
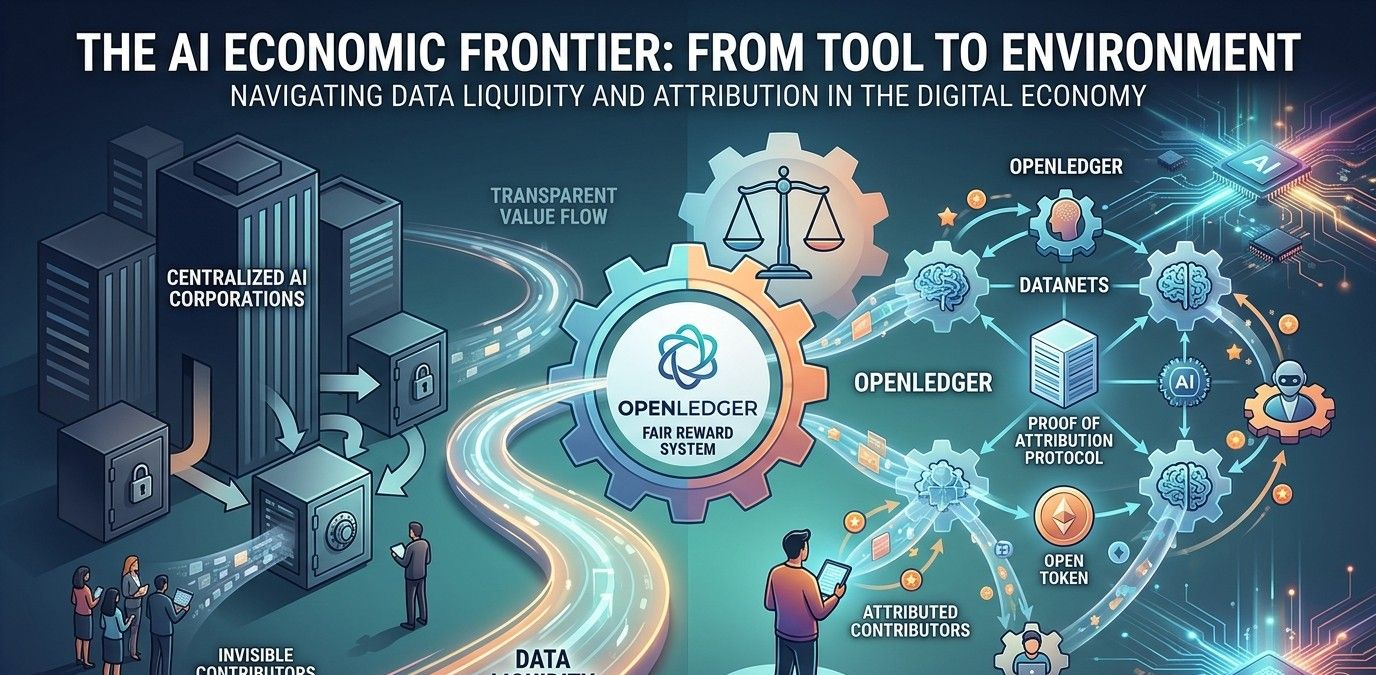
Вместо того чтобы представлять себя просто как еще один ИИ-блокчейн, OpenLedger формулирует свою роль вокруг идеи «ликвидности данных». Проект утверждает, что данные, модели и агенты ИИ должны функционировать в рамках открытой экономической системы, где вклад может оставаться видимым, а не исчезать в централизованных черных ящиках.
В центре архитектуры OpenLedger находится концепция «Датанетов». Они описываются как совместимые наборы данных, которые сообщества могут создавать, управлять и потенциально монетизировать вместе. Вместо того чтобы наборы данных были навсегда заблокированы внутри частных корпоративных систем, OpenLedger предлагает среду, где наборы данных становятся отслеживаемыми активами на блокчейне, связанными с разработкой моделей ИИ.
Проще говоря, проект пытается ответить на трудный вопрос: если данные помогают создавать ценность ИИ, может ли связь между вкладом и вознаграждением оставаться измеримой с течением времени?
Ответ OpenLedger — это то, что они называют «Доказательством атрибуции». Идея заключается в том, что инфраструктура блокчейна может записывать, как участники данных, строители моделей или агенты ИИ участвуют в сети и соответственно распределяют стимулы. Токен OPEN функционирует как часть этого экономического координационного слоя, обрабатывая транзакции, участие в управлении и распределение вознаграждений.
Концептуально это одно из более амбициозных направлений в секторе ИИ-блокчейн, поскольку атрибуция, пожалуй, является одной из наименее решенных проблем в современной индустрии ИИ. Большинство людей, обсуждающих ИИ, сосредоточены на возможностях модели или вычислительной масштабируемости. OpenLedger вместо этого фокусируется на экономической отслеживаемости.
Это различие имеет значение.
Современная разработка ИИ все больше напоминает закрытую промышленную систему. Крупные компании собирают огромные наборы данных, обучают модели в частном порядке и монетизируют выходы через централизованные платформы. OpenLedger, похоже, спрашивает, может ли ИИ вместо этого эволюционировать больше как открытая экономическая сеть, где наборы данных, участники и модели остаются видимыми участниками, а не исчезают в корпоративной инфраструктуре.
Технический дизайн проекта также отражает степень реализма относительно текущей экономики ИИ. OpenLedger не позиционирует себя как прямого конкурента передовым лабораториям ИИ, создающим системы с триллионом параметров. Вместо этого проект подчеркивает специализированные модели, модульную инфраструктуру и совместимые наборы данных. Это может быть одним из его более реалистичных решений.
Обучение ИИ в больших масштабах крайне дорого. Экономика сильно благоприятствует концентрации, потому что разработка продвинутых моделей требует огромного доступа к вычислительным ресурсам и капитальным затратам. Многие децентрализованные проекты ИИ недооценивают эту реальность и создают нарративы, которые звучат технически революционно, но экономически хрупко. OpenLedger, похоже, больше сосредоточен на создании инфраструктуры вокруг более узких проблем координации ИИ, а не на утверждении, что он может полностью децентрализовать передовой ИИ.
Тем не менее, несколько трудных вопросов остаются неразрешенными.
Наибольшая проблема касается самой точности атрибуции. Модели ИИ не являются прозрачными бухгалтерскими книгами. Влияние внутри систем машинного обучения часто статистическое, косвенное и трудно точно изолировать. Один набор данных может незначительно улучшить производительность модели по тысячам параметров, не создавая измеримого события вклада, которое можно было бы легко вознаградить на блокчейне.
Это создает серьезное напряжение в основной тезисе OpenLedger. Запись участия относительно достижима. Надежное измерение долгосрочного влияния гораздо сложнее.
Публичные объяснения проекта четко описывают видение, но многие операционные детали остаются абстрактными. Как именно сеть определяет пропорциональное влияние между наборами данных? Насколько устойчива система к манипуляциям или синтетическому сбору данных? Что мешает участникам заполнять сеть низкокачественной информацией просто для максимизации вознаграждений?
Эти вопросы важны, потому что токенизированные системы вкладов часто сталкиваются с проблемами искажения стимулов с течением времени. Как только экономические вознаграждения существуют, участники оптимизируют свои действия для извлечения вознаграждений, а не обязательно для улучшения качества системы. Поддержание полезных наборов данных в открытой сети может потребовать механизмов управления, которые намного строже, чем обычно предпочитают децентрализованные сообщества.
Существует также более широкая структурная проблема, которую OpenLedger самостоятельно не может решить. Разработка ИИ все больше вознаграждает скорость, масштаб и эффективность интеграции. Централизованные компании могут действовать быстро, потому что они контролируют инфраструктуру внутри. Блокчейн-системы, в свою очередь, вводят накладные расходы на управление, сложность координации и транзакционные трения.
OpenLedger пытается сбалансировать это через специализацию. Вместо того чтобы функционировать как универсальный блокчейн, он сосредоточен специально на инфраструктуре координации и атрибуции, ориентированной на ИИ. Но более крупное экономическое давление на централизацию все еще существует по всей индустрии ИИ.
Кто получает наибольшую выгоду от этой модели также остается открытым вопросом. Независимые разработчики, небольшие стартапы ИИ, нишевые исследовательские сообщества или наборы данных, специфичные для домена, могут получить наибольшее от прозрачных систем атрибуции. Для них OpenLedger может снизить барьеры для участия в экономиках ИИ, которые в настоящее время благоприятствуют крупным игрокам.
Но стимулы для доминирующих компаний ИИ остаются менее очевидными. Крупные фирмы уже обладают собственными наборами данных, силой распространения и вычислительными преимуществами. Участие в открытых системах атрибуции потенциально может перераспределить ценность от централизованных моделей собственности, которыми они в настоящее время контролируют.
Возможно, самый интересный аспект OpenLedger заключается не в том, удастся ли проекту полностью добиться технического успеха, а в том, что его существование подразумевает о направлении самой индустрии ИИ.
На протяжении многих лет обсуждения вокруг ИИ сосредоточивались почти исключительно на интеллекте: более крупные модели, более быстрый вывод, более сильное рассуждение. OpenLedger смещает внимание на нечто иное — экономическую архитектуру, лежащую в основе интеллекта.
Если искусственный интеллект в конечном итоге станет глубоко интегрированным в глобальные экономические системы, то настоящая долгосрочная дискуссия может касаться не просто того, какие модели становятся наиболее мощными, а того, останется ли созданная этими системами ценность сосредоточенной вокруг владельцев инфраструктуры, или же начнут появляться совершенно новые формы цифрового участия и собственности вокруг невидимого человеческого труда, на котором ИИ по-прежнему тихо зависим.
