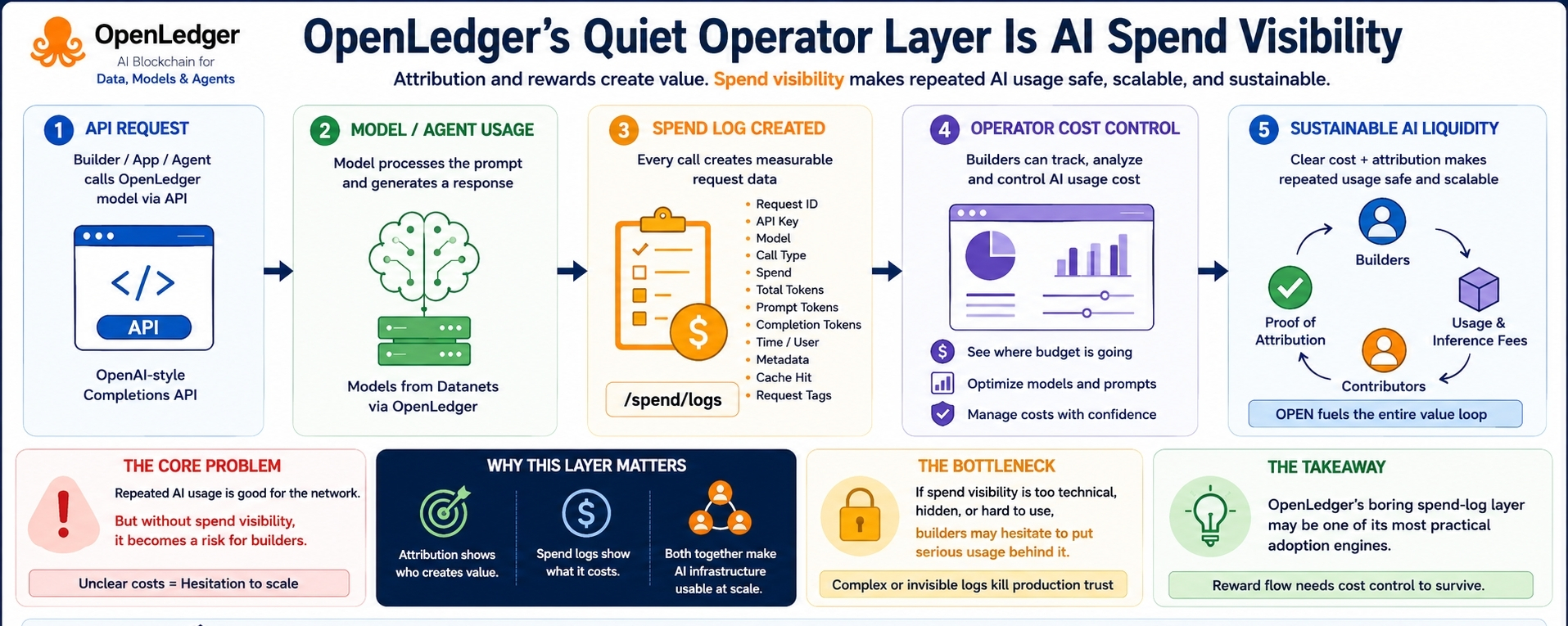
Чем больше я смотрю на OpenLedger, тем больше чувствую, что маленький слой /spend/logs может иметь больше значения, чем громкая история вознаграждений.
Большинство людей естественно смотрят на OpenLedger с точки зрения участников. Это имеет смысл. Дата-сети, доказательства атрибуции, данные, модели, агенты, вознаграждения, OPEN — всё это звучит как основная идея. Если данные помогают модели ИИ, система должна показывать эту ценность и создавать маршрут для вознаграждений. Это простая история для понимания.
Но я думаю, что эта точка зрения все еще неполная.
Потому что как только данные, модели и агенты становятся платинной инфраструктурой ИИ, у строителя появляется другая проблема. Строитель не только спрашивает, кто должен получать оплату. Он спрашивает: «Сколько стоит мне это использование каждый раз, когда оно запускается?»
Этот вопрос скучен, но он серьезный.
OpenLedger имеет API завершений в стиле OpenAI. Он также управляет моделями через /v1/models и /model/info. Это означает, что строители могут вызывать модели, проверять детали моделей и использовать ИИ через более знакомый стиль API. Но часть, которая выделяется для меня, — это отслеживание бюджета и расходов через /spend/logs.
Это звучит как деталь бэкенда. Для меня это не так.
Журнал расходов может показать такие вещи, как ID запроса, API ключ, модель, тип вызова, расходы, общее количество токенов, токены запросов, токены завершения, время, пользователь, метаданные, попадание в кэш и теги запроса. Проще говоря, это помогает строителю увидеть, что произошло, когда использовался ИИ, какая модель была вызвана, сколько токенов было использовано и как выглядели затраты.
Вот где OpenLedger становится более практичным.
Доказательство атрибуции может показать, как ценность возвращается к участникам. Но видимость расходов показывает, может ли строитель позволить себе продолжать использовать эту ценность снова и снова. Это две разные стороны одной и той же экономики. Одна сторона объясняет вознаграждение. Другая сторона объясняет контроль.
Без контроля использование становится рискованным.
Представьте себе небольшого разработчика ИИ-приложений, использующего модель OpenLedger через API завершений. Сначала вызовы низкие. Затраты выглядят управляемыми. Затем пользователи начинают задавать более длинные вопросы. Агенты могут вызывать чаще. Модель может использовать больше токенов запросов или токенов завершения, чем ожидалось. Может быть, некоторые вызовы полезны, а некоторые — пустая трата. Если строитель не может четко прочитать эти расходы, проект становится страшным для масштабирования.
Вот где начинается настоящая проблема оператора.
Повторное использование хорошо для экономики OpenLedger. Больше использования может означать больше сборов за вывод, больше событий атрибуции и больше причин, чтобы Datanets и модели имели значение. Но повторное использование также означает повторные затраты. Если эти затраты скрыты или их трудно понять, строители не могут развиваться с уверенностью. Они замедляются. Они ограничивают использование. Или оставляют идею в режиме тестирования.
Это мое честное мнение: ликвидность ИИ — это не только о том, чтобы сделать активы вознаграждаемыми. Это также о том, чтобы сделать использование управляемым.
Модель, которая может зарабатывать вознаграждения, но не может быть правильно отслежена, не подходит для производства. Агент, который создает ценность, но оставляет непонятные затраты, трудно доверять. Datanet может быть полезен, но если приложения, построенные поверх, не могут контролировать расходы, весь круг ценности становится слабее.
Вот почему слой учета расходов важен.
Это дает оператору способ связать использование ИИ с реальностью бюджета. Какой API ключ сделал запрос? Какая модель создала затраты? Были ли это токены запросов или токены завершения? Какой был тип вызова? Когда это произошло? Эти детали могут не выглядеть захватывающе в посте, но это именно те детали, которые серьезные строители проверяют перед тем, как запустить реальный трафик через систему.
Риск также очевиден.
Если видимость расходов OpenLedger остается слишком технической, скрытой или трудной для использования, тогда строители могут по-прежнему любить идею доказательства атрибуции, но колебаться в серьезном использовании через нее. Атрибуция может быть умной, но если оператор не может контролировать счет, система остается трудной для принятия в больших масштабах.
Вот в чем я вижу напряжение.
OpenLedger нуждается в потоке вознаграждений для участников, да. Но ему также нужна ясность затрат для строителей. Если одна сторона сильна, а другая слабая, рынок становится несбалансированным. Участники могут ждать спроса, в то время как строители остаются осторожными, потому что каждый повторный вызов ИИ имеет прикрепленную к нему стоимость.
Поэтому для меня тихий слой оператора не является мелкой деталью. Это может быть одной из самых практичных частей всей экономики ИИ OpenLedger.
Вознаграждения заставляют сторону предложения работать.
Видимость расходов делает сторону использования более безопасной.
И если @undefined сможет прояснить обе стороны, тогда $open имеет более сильную историю, чем просто "активы ИИ монетизируются." Это становится системой, где строители могут на самом деле видеть, измерять и контролировать стоимость использования этих активов ИИ.
Вот что делает разницу между классной идеей ИИ и чем-то, что строители могут запускать снова и снова. #OpenLedger
