
Я начал замечать что-то странное в индустрии ИИ в последнее время.
Чем громче разговоры об искусственном интеллекте, тем меньше людей обсуждают то, что на самом деле его подпитывает. Все спорят о моделях, агентах, автоматизации, системах рассуждений, прорывах с триллионом параметров, замене рабочих мест ИИ, замене поиска ИИ, замене в принципе всего ИИ. Но чем глубже я наблюдаю за развитием этого пространства, тем труднее игнорировать невидимый слой под всем этим.
Данные.
Не "данные" в холодном техническом смысле, который люди бросают на подкастах и конференциях. Я имею в виду человеческое поведение. Реальные люди постоянно подпитывают эти системы каждую секунду, даже не осознавая, сколько ценности они создают. Разговоры. Загрузки. Коррекции. Предпочтения. Обратные связи. Маленькие взаимодействия, повторяющиеся миллиарды раз по всему интернету.
И честно говоря, этот дисбаланс начинает беспокоить меня больше, чем сам ажиотаж вокруг ИИ.
Несколько дней назад я увидел еще один стартап ИИ, который публиковал скриншоты бенчмарков повсюду, почти не упоминая, откуда вообще пришла базовая ценность обучения. Этот разрыв становится все труднее игнорировать, когда ты его замечаешь.
Потому что каждый цикл ИИ теперь кажется структурно одинаковым.
Новая волна проектов обещает более умных агентов, более быстрые выводы, автономные рабочие процессы, бесконечную продуктивность. Брендинг немного меняется, но система под ним обычно остается той же. Пользователи предоставляют сырье. Платформы его поглощают. Модели улучшаются. Затем большая часть экономической выгоды сосредотачивается вокруг того, кто владеет конечным интерфейсом.
Тем временем, оригинальные вкладчики исчезают почти полностью.
Наверное, поэтому OpenLedger привлек мое внимание по-другому.
Не потому, что я думаю, что децентрализация волшебным образом решает проблемы ИИ. Она этого не делает. Крипта уже доказала, насколько запутанными становятся системы стимулов, как только деньги входят в уравнение. И не потому, что OpenLedger обещает какой-то научно-фантастический прорыв. Честно, мне надоели проекты ИИ, которые делают вид, что они решили вопрос интеллекта каждую вторую неделю.
На самом деле меня интересовал тот угол, с которого OpenLedger, похоже, подходит к проблеме.
Это не рассматривает ИИ исключительно как проблему модели.
Это рассматривается больше как проблема координации.
Проблема отслеживаемости.
Может быть, даже проблема учета собственности.
И я думаю, что это различие имеет гораздо большее значение, чем люди сейчас осознают.
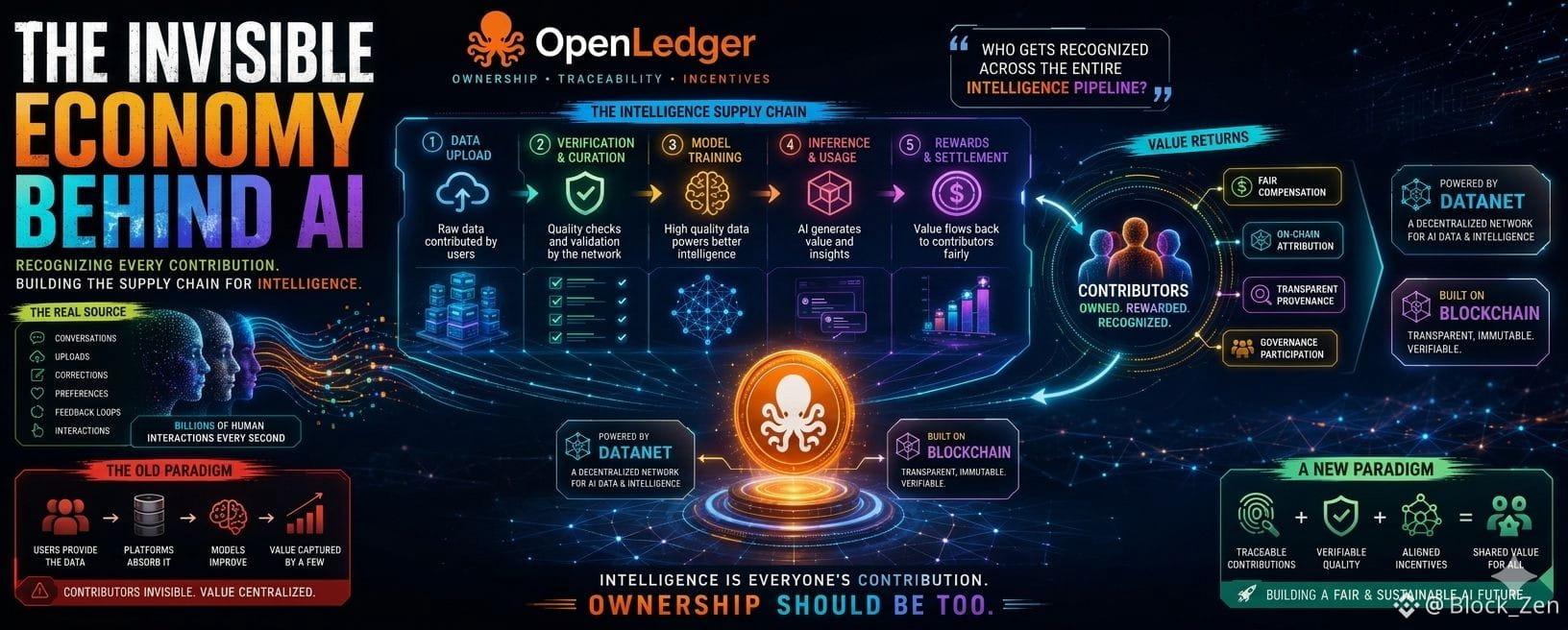
Чем больше я изучал структуру Datanet OpenLedger, тем меньше она казалась еще одним приложением ИИ, гонящимся за хайпом, и тем больше начинала выглядеть как инфраструктура для отслеживания того, как интеллект сам по себе производится. Загрузки данных становятся отслеживаемыми входами. Вклады становятся атрибутируемыми. Модели обучаются на организованных наборах данных вместо невидимых циклов извлечения. Выводы соединяются обратно с вкладчиками, вместо того чтобы ценность только бесконечно поднималась вверх.
Когда ты отдаляешься достаточно, все это начинает выглядеть меньше как продукт ИИ и больше как цепочка поставок для интеллекта.
Эта идея продолжает оставаться у меня в голове.
Потому что, если быть честным, большинство систем ИИ сегодня работают как огромные машины извлечения. Человеческие знания бесконечно поступают, но атрибуция почти исчезает, как только модели становятся достаточно большими. Машина становится продуктом, в то время как люди, формирующие ее, медленно исчезают в статистическом шуме.
Может быть, это было неизбежно в ранней фазе ИИ. Честно, я не знаю.
Но как только блокчейн ввел прозрачную собственность и проверяемое цифровое участие, казалось, что кто-то в конечном итоге применит аналогичную логику и к экосистемам обучения ИИ.
Вот где OpenLedger становится действительно интересным для меня.
Не потому, что успех гарантирован. Далеко не так на самом деле.
Если на то пошло, напряжение внутри этой модели может быть самой важной частью.
Потому что децентрализованные экономики вкладов звучат элегантно, пока в систему не входит реальное человеческое поведение. Стимулы начинают 'фермиться'. Спам появляется немедленно. Управление становится политическим. Низкокачественные вклады заливают сети, как только существуют награды. Крипта уже неоднократно показывала нам этот паттерн в DeFi, платформах для создателей и экосистемах валидаторов.
Инфраструктура ИИ не сможет волшебным образом избежать тех же проблем.
И странным образом, именно поэтому этот проект кажется мне более реальным, а не менее.
Подобные системы находятся в постоянном балансе. Открытость против контроля качества. Децентрализация против эффективности. Честные вознаграждения для вкладчиков против предотвращения коллапса экосистемы в шум.
Эта сложность имеет значение.
Потому что скрытая проблема внутри ИИ сегодня может не быть даже качеством интеллекта. Это может быть упадок координации. Никто по-настоящему не знает, кто что внес, как только системы масштабируются глобально. Происхождение данных становится размытым. Вклад человека становится невидимым. Платформы поглощают коллективный интеллект, в то время как атрибуция тихо исчезает на фоне.
Чем лучше становится ИИ, тем менее заметными начинают казаться люди под ним.
И, возможно, это в конечном итоге становится неустойчивым.
То, что похоже на то, что делает OpenLedger, это смещение разговора от "Кто владеет моделью?" к гораздо большему вопросу:
Кто получает признание в целом интеллекте?
Это полностью меняет контекст.
Вместо того чтобы ИИ вел себя как закрытая черная коробка, магически производящая результаты, интеллект начинает выглядеть больше как многослойная экономическая инфраструктура, где на каждом этапе остаются финансовые следы. Загрузки. Верификация. Обучение. Вывод. Управление. Награды.
Почти как если бы наблюдать за тем, как интеллект сам по себе становится экономически наблюдаемым в реальном времени.
Я все еще не полностью уверен, что обычным пользователям важна атрибуция для того, чтобы эта модель масштабировалась глобально. История обычно предпочитает удобство прозрачности. Люди говорят, что хотят собственности, пока не возникает трение, затем все тихо возвращаются к более простым системам.
Мы уже видели, как это происходило в Web2.
Большинство людей обменяли приватность на удобство, не подумав дважды.
Так что, может быть, то же самое происходит и с ИИ.
Но ИИ создает другой вид давления, потому что вклад сам по себе становится все труднее увидеть. И чем более невидимым становится вклад, тем более концентрированной становится собственность в конечном итоге.
Это та часть, о которой я не могу перестать думать в последнее время.
Может быть, OpenLedger приходит слишком рано.
Может быть, экономики атрибуции станут важными позже.
Или, может быть, люди просто перестают беспокоиться, пока результаты остаются полезными и увлекательными.
Я искренне пока не могу сказать.
Но я знаю одно:
OpenLedger продолжает отвлекать разговор об ИИ от зрелища и обратно к инфраструктуре. К потокам собственности. К выравниванию стимулов. К тому, кто на самом деле захватывает ценность, когда интеллект становится непрерывно циркулирующей экономической системой, а не просто еще одним программным продуктом.
Сейчас это кажется гораздо более важным, чем очередная война бенчмарков или еще одна демонстрация ИИ, притворяющаяся, что автономность решила все за ночь.
Не хайп.
Просто любопытство о том, куда движется структура под всем этим.