Я думал о @OpenLedger с противоположной стороны сегодня.
Обычно, когда люди обсуждают AI блокчейн проекты, они начинают с возможностей. Данные становятся монетизируемыми. Модели становятся активами. Агенты становятся экономическими игроками. Ликвидность входит в места, где ценность раньше была заточена. Это интересная теза, и это часть того, почему $OPEN продолжает появляться в разговорах об AI инфраструктуре.
Но более полезный вопрос может быть менее комфортным: что может замедлить этот процесс?
Не потому, что идея слабая. На самом деле, наоборот. Сильные идеи инфраструктуры часто терпят неудачу или движутся медленно, когда сталкиваются с существующим поведением, регулированием, затратными структурами и институциональными привычками. Поэтому вместо того, чтобы рассматривать #OpenLedger как окончательный ответ, может быть лучше задать вопрос, что должно пойти правильно, прежде чем это станет широко используемым.
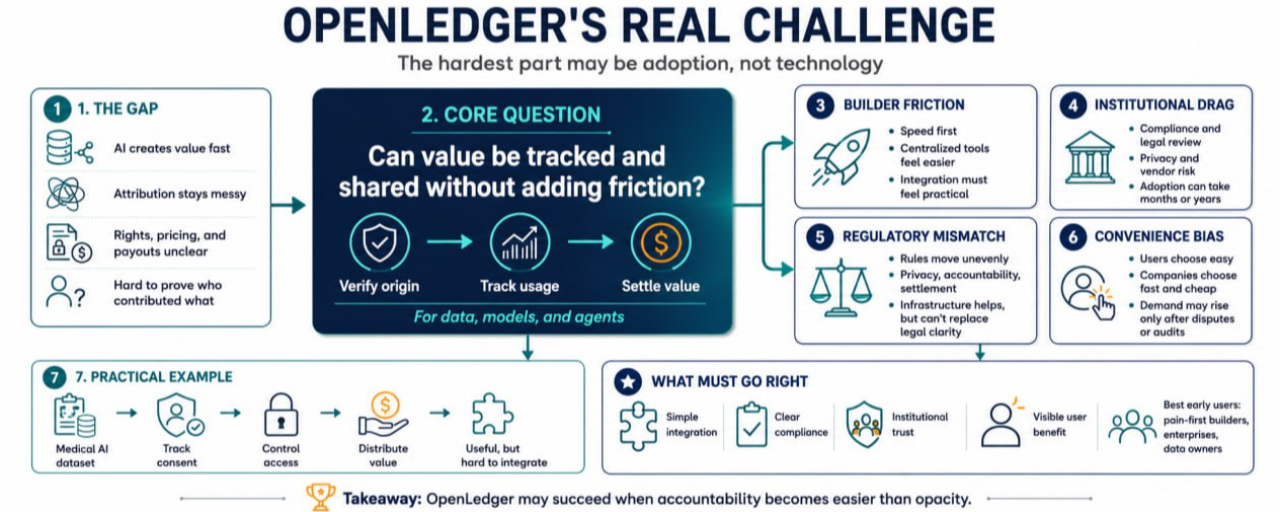
Проблема перед OpenLedger
ИИ уже проникает в бизнес-процессы, но экономический слой вокруг него беспорядочен.
Компания может использовать сторонние данные, донастраивать модели, развертывать агентов и автоматизировать решения, не имея четкого способа отслеживать, кто что внес. Пользователи часто не знают, как используются их данные. Создатели могут не знать, как оценить активы ИИ. Учреждения могут хотеть лучшее отслеживание аудита, но колебаться перед раскрытием чувствительных операций. Регуляторы все еще пытаются понять, где начинается и заканчивается ответственность.
Это создает странный разрыв. ИИ может быстро создавать ценность, но доказать, откуда эта ценность пришла, гораздо сложнее.
Ориентация OpenLedger на разблокировку ликвидности для монетизации данных, моделей и агентов непосредственно обращается к этому разрыву. Тем не менее, наличие правильной проблемы не гарантирует легкого принятия.
Риск один: создатели могут избегать дополнительного трения
Создатели обычно заботятся о скорости в первую очередь.
Если разработчик может выпустить приложение ИИ, используя централизованный API, простую базу данных и платежного провайдера, ему может не быть дела до более глубокой атрибуции или расчетов. Команды на ранних стадиях часто борются за пользователей, а не разрабатывают идеальную экономическую инфраструктуру.
Это реальный риск принятия для OpenLedger. Даже если проверяемые потоки данных и пути монетизации полезны, создатели должны чувствовать, что они практичны. Если интеграция кажется тяжелой, документация неясной, или выгоды приходят слишком поздно, многие команды могут отложить использование.
Проблема не только техническая. Она поведенческая. Люди принимают инфраструктуру, когда она устраняет боль, которую они уже чувствуют.
Риск два: учреждения движутся медленно
Учреждениям может понадобиться инфраструктура, похожая на OpenLedger, но они редко становятся быстрыми последователями.
Банки, страховщики, медицинские фирмы, университеты, логистические компании и государственные учреждения заботятся о соблюдении, закупках, юридическом анализе, риске поставщиков, конфиденциальности данных и внутреннем одобрении. Даже когда преимущества очевидны, внедрение может занять месяцы или годы.
Для учреждений обещание монетизации потоков данных ИИ недостаточно. Им нужна уверенность в том, что система может соответствовать стандартам аудита, требованиям безопасности, обязательствам по отчетности и ожиданиям регуляторов.
Вот где @OpenLedger должно стать чем-то большим, чем просто интересная сеть. Оно должно стать скучным в лучшем смысле: надежным, понятным и легким для оправдания внутри комитета по рискам.
Риск три: регуляторы могут не двигаться синхронно
Регулирование ИИ все еще неравномерно.
Одна юрисдикция может сосредоточиться на конфиденциальности. Другая может сосредоточиться на подотчетности модели. Третья может заботиться о финансовом расчете, защите потребителей или локализации данных. Для системы, которая работает с активами ИИ, правами на данные, деятельностью агентов и распределением ценности, это создает сложную среду.
OpenLedger мог бы помочь, сделав потоки более прозрачными и отслеживаемыми. Но регуляторы все еще могут не соглашаться с тем, что считается приемлемым доказательством, законным использованием данных или честной компенсацией.
Эта неопределенность может замедлить принятие. Учреждения могут ждать более четких правил, прежде чем глубоко погружаться. Создатели могут избегать регулируемых случаев использования. Пользователи могут оставаться скептичными, если не понимают, как защищаются их права.
Инфраструктура может поддерживать соблюдение, но она не может заменить юридическую ясность.
Практический пример: медицинский набор данных ИИ
Представьте, что компания хочет создать инструмент ИИ, который помогает клиникам анализировать формы приема пациентов.
Данные имеют ценность. Модель имеет ценность. Агент, который маршрутизирует дела, имеет ценность. Но риски серьезные. Конфиденциальность пациентов должна быть защищена. Согласие должно быть ясным. Доступ должен быть контролируемым. Если инструмент улучшает результаты или снижает затраты, могут возникнуть вопросы о том, кто получает финансовую выгоду.
Инфраструктура в стиле OpenLedger может помочь отслеживать разрешения, использование и распределение ценности. Это будет важно для создателей, учреждений, пользователей и регуляторов.
Но принятие все равно было бы сложным. Медицинские организации могут беспокоиться о раскрытии соблюдения. Юристы могут задаться вопросом, подходит ли модель расчетов под существующие правила. Пациенты могут не доверять неопределенным обещаниям о монетизации данных. Интеграция со старыми системами может быть дорогой.
Таким образом, ценностное предложение действительно, но путь не автоматический.
Риск четыре: рынок может предпочесть удобство
Самый большой риск может заключаться в том, что многие люди говорят, что хотят прозрачности, но выбирают удобство.
Пользователи кликают по условиям, которые не читают. Компании выбирают инструменты, которые дешевле и быстрее. Создатели оптимизируют под скорость запуска. Учреждения часто откладывают изменения в инфраструктуре, пока риск не станет неизбежным.
Это не означает, что OpenLedger не может работать. Это означает, что спрос может расти постепенно, особенно после споров, аудитов или давления регуляторов, которые делают непрозрачные системы ИИ более затратными.
Другими словами, необходимость в OpenLedger может стать очевидной только тогда, когда текущий способ создания ИИ начнет ломаться под давлением реального мира.
Основной вывод
Наиболее вероятными ранними пользователями OpenLedger могут быть создатели, которые уже чувствуют боль от атрибуции ИИ, монетизации данных, расчетов агентов или соблюдения учреждений. Это также может заинтересовать владельцев данных, которые хотят компенсацию, предприятия, которым нужна аудируемость, и команды, строящие рабочие процессы ИИ, где доверие важнее скорости.
Это может сработать, если #OpenLedger сделает верификацию и распределение ценности проще, чем управление частными соглашениями, ручными аудитами и неясными записями о праве собственности. Это может провалиться или двигаться медленно, если интеграция окажется слишком сложной, регулирования будут оставаться запутанными, или пользователи и компании продолжат выбирать удобство вместо подотчетности.
Вот почему я вижу $OPEN как простую нарративную ИИ, а не как тест поведения рынка. Люди хотят только более умный ИИ, или они также хотят системы ИИ, которые могут доказать, как создается и делится ценность?
Это не финансовый совет.
Как вы думаете, что является самой большой преградой для OpenLedger: регулирование, принятие создателями, доверие учреждений или осведомленность пользователей?