
The upload passes, the wallet shows up, the validation score looks normal, and nobody thinks about it again until rewards land lower than expected. Then the whole thing becomes a support problem.
That is the annoying Datanet case. Not the file that gets rejected because someone shoved audio into a text dataset, or because the structure is broken, or because the material does not fit the Datanet. Rejection is irritating, but at least it is a clean failure. The contributor knows where the door closed.
The worse case is the accepted file.
A contributor sees a valid submission. Maybe their address moves on the leaderboard. Maybe the score looks decent enough that they assume the upload did its job. Three weeks later the model has trained, some inference has happened, rewards have shifted, and now the person is in Discord asking why their wallet got almost nothing.
Not calmly asking either. It is usually three screenshots, one cropped leaderboard row, one wallet balance from a block explorer, and somebody typing “SCAM?” before a mod has even found the right internal dashboard. Another contributor says their lower score paid better. Someone else posts an Imgur album with red boxes around two different wallet addresses. Half the thread is people comparing numbers they do not actually understand. The mod is stuck saying “we’re checking” for the sixth time that day.
That is where accepted data and attributed data stop being the same thing.
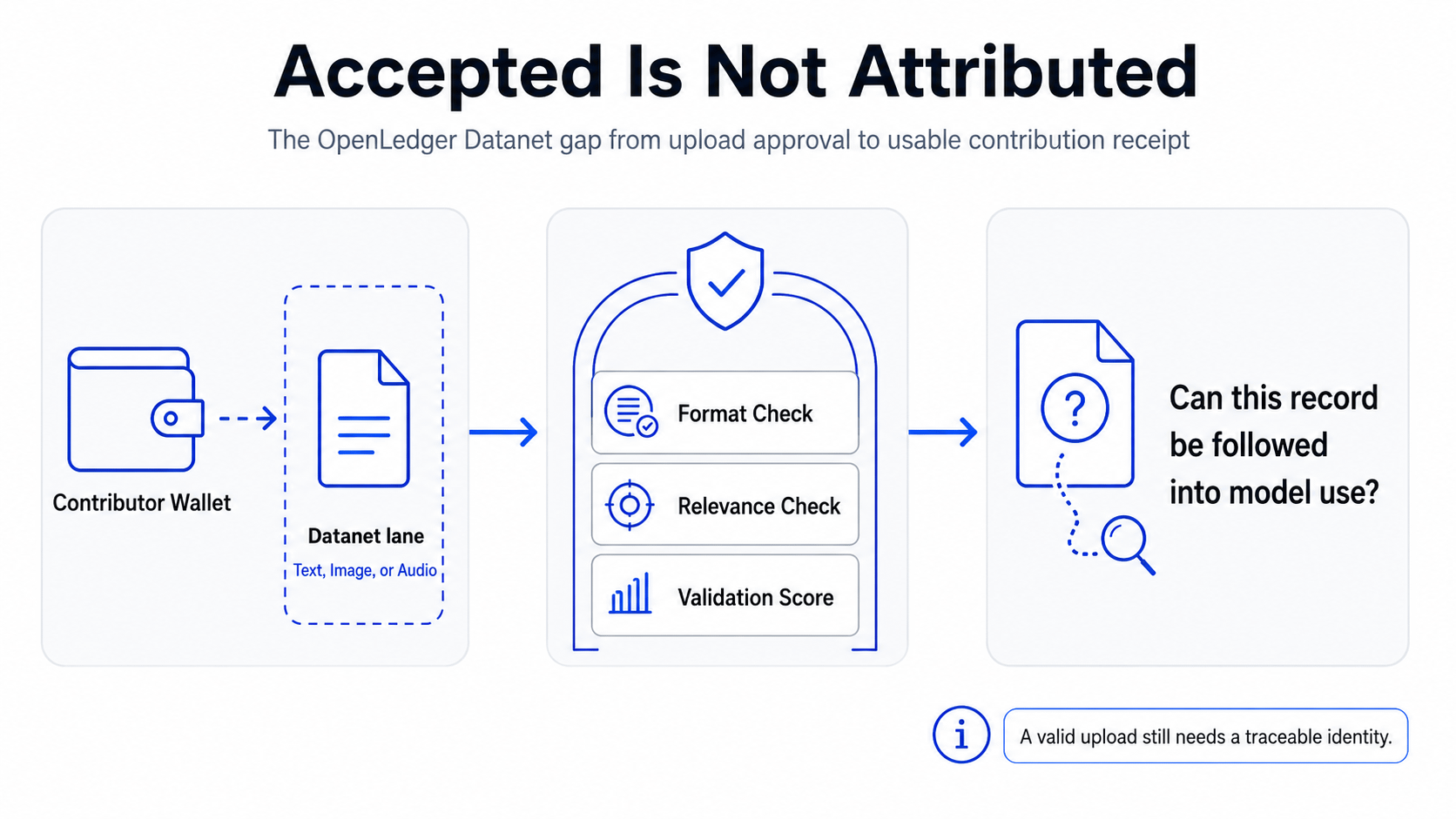
The Datanet lane itself is not the problem. I actually like that OpenLedger treats a Datanet as a defined data surface instead of a random dumping ground. If the Datanet is text, it is text. If it is image, it is image. If it is audio, it is audio. Mixed uploads do not belong there, and once a lane is set, changing the nature of that dataset casually would make the whole thing sloppy fast.
That constraint keeps out a lot of junk before it gets expensive.
But the moment the file is accepted, the system needs to attach a boring identity to it that survives the rest of the pipeline. Not a nice “valid” badge. Not just a score. Something an engineer can actually chase later when a wallet owner is yelling about credit.
In practice, that means I should be able to look up the contribution by wallet, see the Datanet it entered, check the file hash, see the data type, pull the validation score, see which validator version passed it, and then keep following it into the training run. If the file got included in run 184 but not run 185, that matters. If its influence weight was tiny because the same domain had already been covered by cleaner submissions, that matters too. If a later quality pass reduced the reward because the content was redundant or low impact, that cannot live in someone’s head or in a private spreadsheet.
A validation score only proves the file cleared the front gate. It says the upload fit the Datanet well enough on relevance, structure, integrity, and purpose. Fine. Useful. Necessary.
It does not prove the model leaned on that file later.
It does not prove the output had any meaningful dependency on it.
It does not prove the reward calculation gave the contributor credit in a way that can survive an argument.
This is where leaderboards make the social side worse. They are useful because people need visible participation signals, but they also train contributors to trust the wrong thing. A ranked address feels like a claim on future rewards, even if the actual payout is supposed to follow impact rather than upload count. So when a lower ranked wallet earns more, or a bulk submitter appears to benefit more than someone with cleaner domain data, the leaderboard stops looking motivational and starts looking like evidence.
The operator then has to explain something the interface may not be built to explain.
That explanation cannot be “the attribution layer handled it.” Nobody accepts that once token rewards are involved. They want to know which accepted file got used, which training run touched it, whether any inference events leaned on it, what influence score was assigned, what reward epoch paid it, and whether a penalty or reduction hit the final amount. Not in a polished PDF. In a database row, a log entry, an internal trace, something with enough ugly detail that a developer can say, “Here is why your reward is low,” and not sound like they are inventing policy in real time.
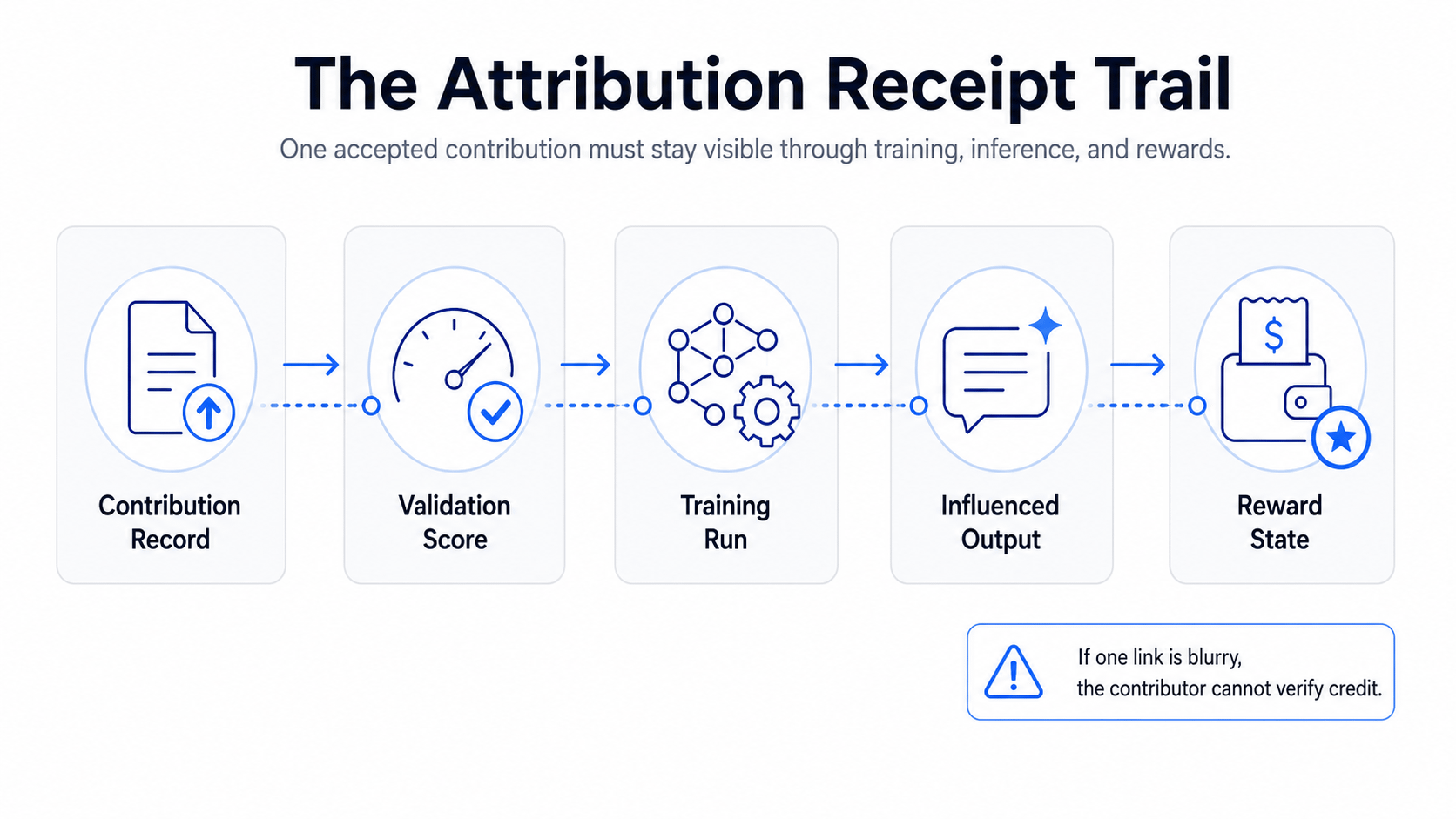
The technical mess starts after the part contributors can see.
On the upload side, the file still has a name, a hash, a wallet, a Datanet, a validation result. It feels traceable. Once training starts, that clean contributor view gets crushed into batches, checkpoints, embeddings, gradients, weights, and whatever attribution math OpenLedger uses to connect data impact back to outputs and rewards. The file no longer looks like a file. It becomes part of a giant anonymous training state unless the system keeps a deliberate mapping around it.
That mapping is the expensive part people usually underbuild.
A model answer does not come out holding up a placard that says it used wallet 0xabc’s upload from Tuesday. Influence has to be measured, logged, and attached back to the contribution. If bad data is later found to be low quality, redundant, biased, or adversarial, that needs to be reflected without turning the payout table into a mystery box. If two contributors upload overlapping material and one version is cleaner, the reward logic needs to show why one got more credit. If the model improved in a domain after training on a Datanet, the impact cannot just be waved at from thirty thousand feet.
This is the sort of pipeline that looks fine in a demo and becomes miserable in production.
The demo shows accepted files, scores, maybe a leaderboard, maybe a reward state. Production gives you edge cases. Duplicate submissions. Domain experts who submit less but contribute more useful data. Low effort wallets gaming volume. Validators that changed between epochs. A training run that used one slice of the Datanet but not another. Inference events that are easy to claim credit for and hard to prove. A community that thinks every accepted upload deserves a payday.
Some of those complaints will be wrong. A lot of them, probably. Passing validation does not mean the file was valuable. A leaderboard rank does not mean the model needed your data. A wallet can be active and still have low influence.
That is exactly why the attribution record has to be boring and inspectable.
I do not want a contributor support flow where the operator is alt-tabbing between a dashboard, a block explorer, a Discord thread, and some half-exported CSV trying to reconstruct why a reward moved. That is how mods burn out and builders start giving vague answers because the real answer takes two engineers and an afternoon to assemble.
The better version is unglamorous. Query the wallet. Find the contribution. Join it to the Datanet. Check the file hash. Pull the validator result. Trace it into the training run. See which inference events got linked to it. Look at the influence score. Check the reward epoch. Check whether the amount was reduced because the data overlapped, failed a later quality filter, or simply did not move the model enough.
If that sounds boring, good. Reward disputes should be boring.
OpenLedger’s Datanet idea only gets harder as more value moves through it. The more $OPEN rewards depend on data impact, the less room there is for soft attribution language. A fuzzy upload badge is tolerable when everyone is farming points and pretending not to care. It is not tolerable when the reward line changes and a contributor can point to an accepted file that nobody can follow through training.
That missing join becomes economic exposure.