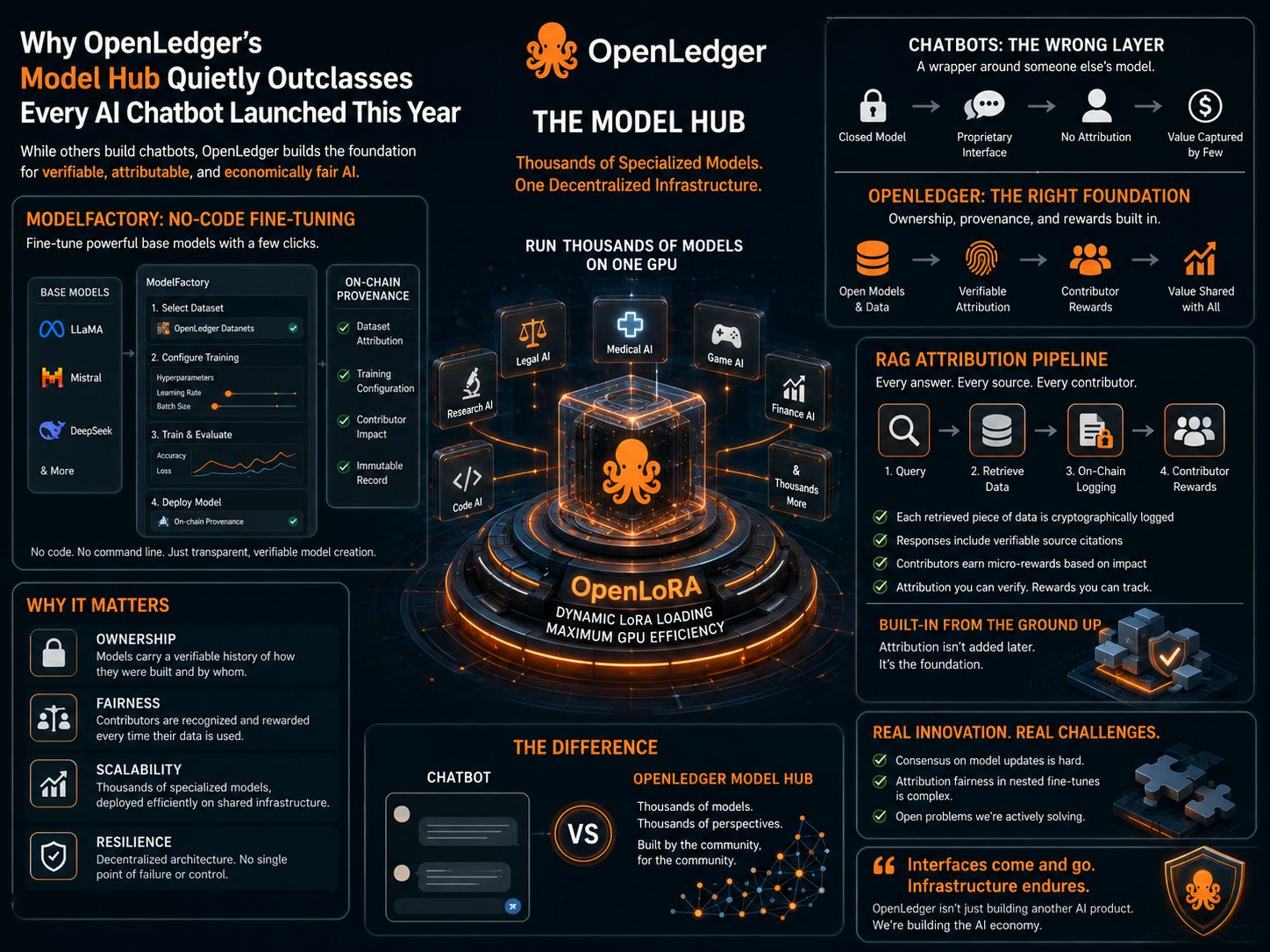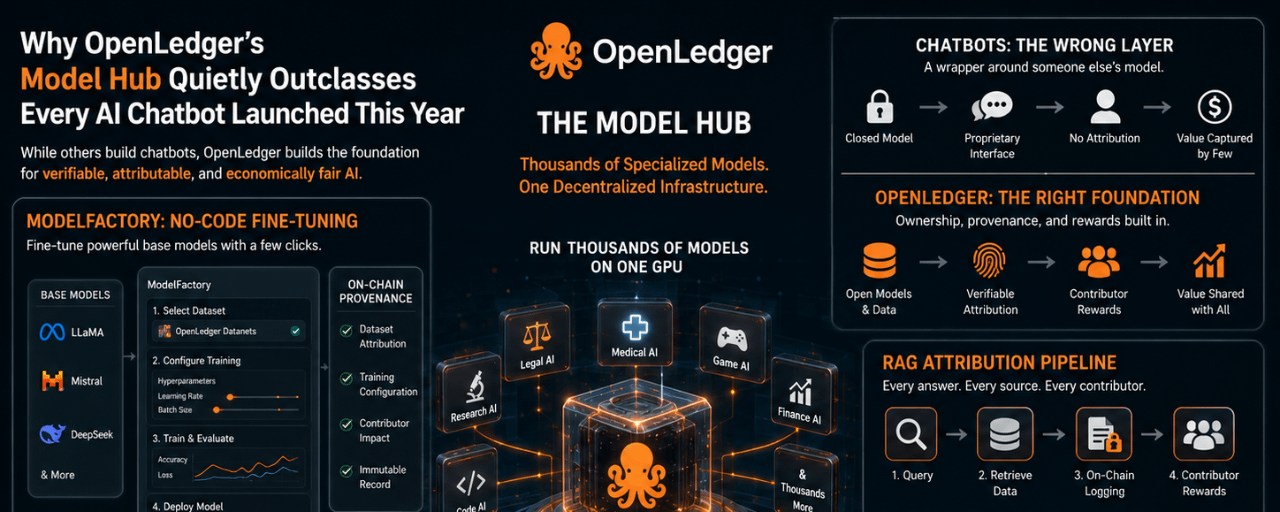
Большинство хабов моделей решают проблему распределения. Ты загружаешь модель, кто-то её скачивает, сделка завершена. Хаб моделей OpenLedger решает что-то другое: что происходит с отношениями между моделью и данными, на которых она была обучена, после завершения обучения?
Этот вопрос архитектурный. Он начинается внутри ModelFactory и не останавливается на развертывании.
Интерфейс ModelFactory скрывает значительную сложность за графическим рабочим процессом, который не требует командной строки. Пользователь выбирает базовую модель из списка, в который входят LLaMA, Mistral и DeepSeek. Затем он запрашивает доступ к конкретному Datanet, набору данных, специфическому для домена, куда контрибьюторы загрузили и атрибутировали свои данные. Этот доступ предоставляется по разрешению. Контрибьюторы, владеющие данными внутри Datanet, устанавливают условия использования их данных для дообучения. Как только доступ предоставлен, набор данных интегрируется прямо в рабочий процесс обучения.
Отсюда пользователь настраивает обучение через графический интерфейс, который открывает гиперпараметры, такие как скорость обучения, размер батча и количество эпох через поля, а не конфигурационные файлы. Тонкая настройка происходит через LoRA или QLoRA в зависимости от размера модели и ограничений оборудования, с аналитической панелью в реальном времени, отображающей кривые потерь и метрики валидации во время выполнения задачи. Пользователь может протестировать тонко настроенную модель через встроенный чат-интерфейс перед развертыванием.
Необычно то, что записывается в блокчейн на каждом этапе. OpenLedger фиксирует, какой Datanet был использован, какая версия набора данных, какие конфигурационные выборы сформировали запуск и какие данные участников были включены. Эта запись не является лог-файлом на сервере. Это запись происхождения в блокчейне, которая сопровождает модель с момента окончания обучения.
Это дизайнерское решение отделяет ModelFactory от всех других платформ тонкой настройки. Цепочка происхождения не заканчивается на обучении. Когда модель развертывается через OpenLoRA, каждый вызов вывода прикрепляется к той же цепочке. Система знает, какая модель произвела данный вывод, какой Datanet сформировал эту модель и какие участники должны получить атрибуцию за это событие вывода. Модель несет свою собственную историю в продакшн и продолжает обновлять её с каждым использованием.
OpenLoRA делает это экономически жизнеспособным в масштабе, решая проблему стоимости развертывания, которая в противном случае сделала бы рынок специализированных моделей непрактичным. Система использует динамическую загрузку адаптеров LoRA: специализированные модели не занимают постоянно память GPU. Они загружаются по запросу, когда приходит запрос на вывод, и выгружаются, когда простаивают. Один GPU обслуживает тысячи различных тонко настроенных моделей таким образом, циклически переключаясь между адаптерами в зависимости от входящего трафика, а не поддерживая выделенные мощности для каждого из них.
Что это позволяет, стоит обдумать. Если стоимость развертывания модели стремится к нулю, барьер для поддержания активной специализированной модели — не стоимость оборудования, а качество вклада и потребность в использовании. Модель медицинского Datanet остается активной, пока медицинские специалисты продолжают её запрашивать. Юридическая модель остается активной, пока она превосходит общие альтернативы в своей области. Давление выбора смещается от "может ли эта модель существовать" к "действительно ли эта модель полезна". Это фундаментально другая рыночная динамика, чем та, которую создают большинство AI-платформ.
Пайплайн атрибуции RAG добавляет третий уровень поверх происхождения обучения ModelFactory и эффективности развертывания OpenLoRA. Когда развернутая модель запрашивает внешние данные для ответа на запрос, каждый извлеченный контент криптографически регистрируется в блокчейне в момент извлечения. Ответ модели включает проверяемые цитаты, указывающие обратно на конкретные источники данных. Участники, чей контент был извлечен, получают микро-награды, рассчитанные пропорционально тому, насколько их данные повлияли на вывод, автоматически распределяемые по событию вывода на основе весов атрибуции, которые система назначает.
Сочетание всех трех уровней создает категорию AI-актива, которой не существует больше нигде: модель, которая одновременно является функциональным инструментом вывода, проверяемой записью своего собственного создания и постоянным каналом дохода для всех, кто внес вклад в её создание. Одна модель на рынке, построенном таким образом, уже имеет больше информации, чем весь продукт чат-бота. Хаб OpenLedger оптимизирует проверяемое происхождение для тысяч таких моделей, каждая из которых обслуживает свою конкретную область, каждая экономически связана с сетью участников, стоящей за ней.
Неразрешенное напряжение заключается в том, сохраняется ли справедливость атрибуции, когда модели тонко настраиваются на основе других тонко настроенных моделей. Когда вторичная модель наследует веса от первичной тонко настроенной модели, отслеживать, какие оригинальные вклады Datanet повлияли на поведение вторичной модели, становится действительно сложно. Белая книга OpenLedger по доказательству атрибуции рассматривает это, используя приближения функции влияния для меньших моделей и атрибуцию на основе градиентов для больших, но точность на нескольких уровнях удаления все еще остается открытым вопросом для исследования.
Это напряжение отмечает, где находится следующая тяжелая работа, а не где архитектура терпит неудачу. Хаб моделей, который фиксирует, что он построил, кто его построил и кто получает деньги, когда он используется, — это другая категория инфраструктуры, чем та, которая ничего не фиксирует. Запись является продуктом.
$OPEN #OpenLedger