Чем больше я смотрю на структуру OpenLedger, тем больше мне бросается в глаза, что дело не только в монетизации данных.
Это вопрос:
Как вы оплачиваете невидимых участников после того, как их работа становится частью живой модели ИИ?
Вот настоящая проблема, скрывающаяся под поверхностью.
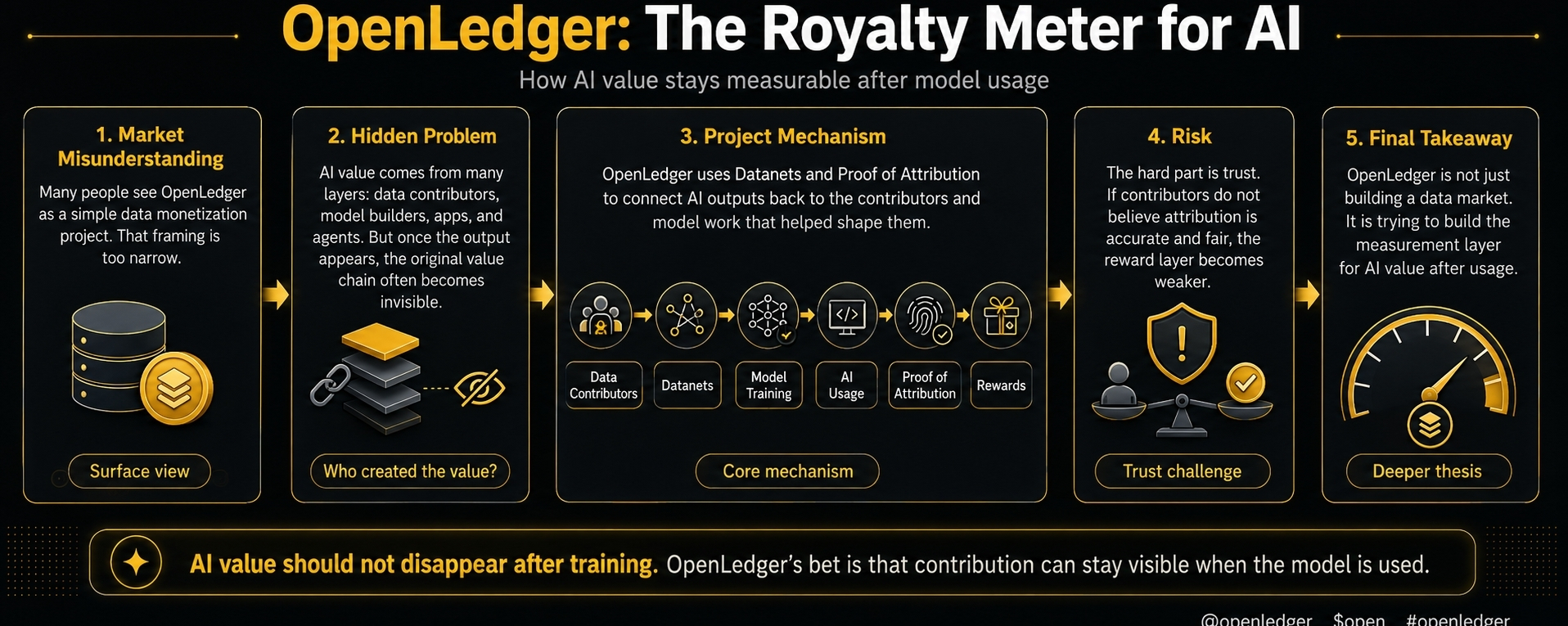
Многие люди могут описать OpenLedger как проект, который помогает владельцам данных зарабатывать на ИИ. Это определение не ошибочно, но недооценит механизм.
Более сложная проблема заключается в том, что происходит после того, как данные уже были использованы.
Набор данных может улучшить модель.
Модель может помочь в разработке приложения.
Приложение может обслуживать пользователей.
AI-агент может действовать поверх всего этого стека.
Но когда появляется финальный результат, оригинальная цепочка часто скрыта.
Кто помог создать эту ценность?
Кто должен получить признание?
Кто должен получать вознаграждения, когда модель используется впоследствии?
Вот где OpenLedger становится более интересным.
OpenLedger позиционируется как AI Blockchain для данных, моделей и агентов. Но более сильная идея заключается не только в том, чтобы "поместить данные AI в цепочку". Более сильная идея заключается в том, чтобы сохранить вклад AI измеримым после использования.
Вот где Datanets и Доказательство атрибуции имеют значение.
Данные поступают в Datanets. Модели могут быть обучены или дообучены на основе этих данных. Приложения и агенты затем могут использовать эти модели. Доказательство атрибуции предназначено для связи результата обратно с авторами, наборами данных и работой модели, которая помогла ему сформироваться.
Это тот момент, когда OpenLedger выходит за рамки простой идеи рынка данных.
Вопрос не только в том, имеет ли данные ценность. Большинство людей уже согласны с тем, что хорошие данные имеют ценность.
Лучший вопрос в том, увидит ли человек, чьи данные улучшили модель, что-то от этого, когда модель начнет давать результаты.
Вот почему я вижу OpenLedger меньше как обычный рынок данных и больше как счетчик роялти для AI.
Думай о музыкальных роялти, но для вывода AI.
Когда играется песня, существует как минимум структура для отслеживания прав и платежей. AI сложнее, потому что один ответ может формироваться множеством скрытых входов.
Небольшой набор данных может улучшить узкое умение.
Тонко настроенная модель может добавить специфические знания.
Строитель может упаковать эту модель в продукт.
Агент может использовать это в рамках задачи.
Без атрибуции вся эта работа может исчезнуть в одном финальном результате.
Тезис OpenLedger заключается в том, что эта цепочка должна измеряться, а не игнорироваться.
Это важно, потому что AI движется к более специализированному использованию. Не каждая ценная модель будет гигантским общим чат-ботом. Некоторая ценность будет исходить от меньших систем, построенных вокруг конкретных областей, сообществ или рабочих процессов.
Этим системам понадобятся полезные данные.
Но им также понадобится доверие к вкладу.
Если сообщество строит набор данных, и этот набор данных помогает обучить модель, вопрос вознаграждения не может оставаться неопределенным вечно. Если AI-агенты начинают использовать модели чаще, тот же вопрос становится еще более значительным.
Использование не всегда будет разовым событием.
Это может происходить снова и снова.
Рынок данных говорит, что покупатели и продавцы могут встретиться.
Счетчик роялти говорит, что использование создает связь даже после того, как актив уже работает.
Это ключевое отличие.
Ценность AI возникает не только когда данные загружаются. Она возникает позже, когда модель отвечает на запрос, когда приложение вызывает её, когда агент действует с её помощью, или когда результат решает реальную проблему пользователя.
Тем не менее, здесь есть реальный риск.
Атрибуция должна быть доверенной.
Недостаточно просто сказать, что участники будут вознаграждены. Более сложная часть заключается в том, чтобы убедить людей, что атрибуция реальна, а не просто число, которое выглядит справедливым снаружи.
Если участники не доверяют измерению, уровень вознаграждения становится слабее.
Это та часть, которую OpenLedger должен доказать со временем. Система должна показать, что Доказательство атрибуции может оставаться полезным, когда в цепочку входят больше данных, больше моделей, больше приложений и больше агентов.
Я не говорю, что OpenLedger решил все проблемы монетизации AI.
Сильный аргумент более узкий и полезный.
OpenLedger нацеливается на один из самых сложных экономических вопросов в AI: как сохранить ценность измеримой после того, как многие невидимые участники станут частью одного и того же результата модели.
Это более глубокий угол, который я вижу в @OpenLedger
$OPEN находится внутри этого более крупного вопроса вокруг данных, моделей, агентов и атрибуции.
OpenLedger не просто строит рынок данных. Он пытается создать уровень измерений для ценности AI. #OpenLedger