Большинство рынков ИИ потерпят неудачу, если не смогут понять, кто на самом деле сделал модель лучше.
OpenLedger ($OPEN) пытается решить сложную часть этого хаоса. Дело не только в том, кто предоставил данные. Не только в том, кто обучил что. Но и в том, какая именно часть работы помогла, когда модель дает хороший ответ.
На бумаге это выглядит чисто.
В реальной жизни все быстро становится странным.
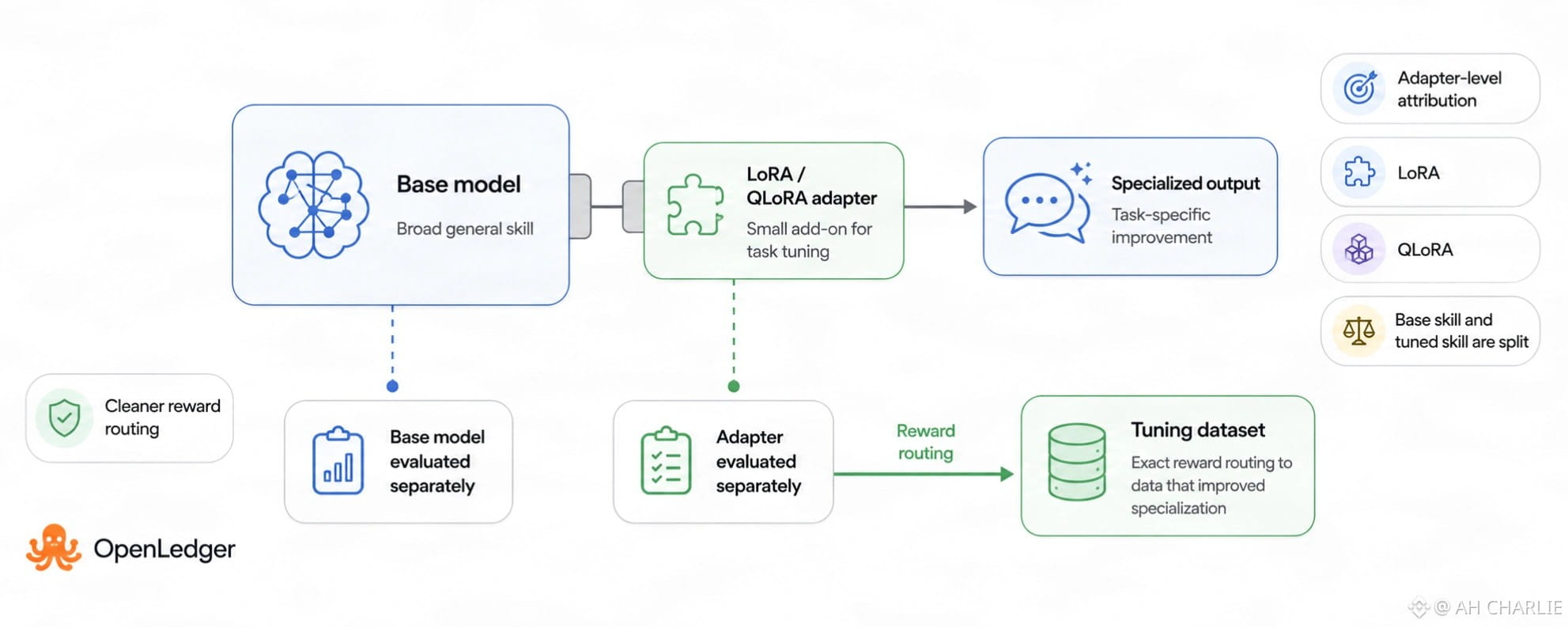
Базовая модель может уже знать много. Затем кто-то добавляет небольшой аддон, называемый LoRA. Представьте LoRA как тонкую линзу, помещенную на большую камеру. Она не перестраивает каждую часть. Она искажает, как выглядит выходной сигнал одним четким образом. QLoRA — это более легкая форма той же идеи, созданная для настройки с меньшими потерями. Простой концепт. Большой эффект.
Вот где мне стало интересно.
Когда модель использует LoRA или QLoRA, кто получает деньги за ценность? Человек, стоящий за базовой моделью? Команда, которая сделала данные для настройки? Оба? И сколько?
Здесь начинается важно учитывать атрибуцию на уровне адаптера. OpenLedger не рассматривает настроенную модель как одну большую черную коробку. Она разбивает её на части. Базовая модель с одной стороны. Адаптер с другой стороны. Каждая проверяется по своей роли.
Это хорошо, потому что это означает, что поток вознаграждений может стать менее расплывчатым.
Базовая модель может обладать широкими навыками. Она знает тон, факты, стиль кода, математическую форму, все эти основные вещи. Адаптер может добавить узкие навыки. Может, лучше юридический стиль. Может, лучше заметки по здоровью. Может, более острый бот поддержки крипты. Адаптер маленький, но он может изменить вывод так, как пользователи это почувствуют.
Без этого разделения маршрутизация вознаграждений становится запутанной.
Один набор данных может обучить базовому навыку. Другой может обучить навыку задачи. Если оба смешаны в один результат, ценность теряется в тумане. Идея OpenLedger состоит в том, чтобы проследить ценность обратно к тому, откуда она пришла. Не предполагая по названиям брендов. Видя, что сделала базовая часть, а затем что изменил адаптер.
Для OPEN это не просто техническая деталь. Это дизайн рынка.
Активы ИИ нуждаются в доверии, прежде чем они смогут справедливо оценить работу. Если данные для настройки делают модель лучше в одной задаче, эти данные не должны рассматриваться как шум. Они должны иметь право на ценность. Проверки на уровне адаптера делают это право более точным.
Тем не менее, ну… это не магия.
Атрибуция может быть чистой в концепции и сложной на практике. Модели размывают границы. Данные имеют пересечения. Хороший выход может возникнуть из базовой памяти, вкуса адаптера, формы запроса и контекста пользователя одновременно. Поэтому OpenLedger должен доказать, что он может разделить ценность так, как это примут создатели. Не только один раз. Снова и снова.
Это настоящая проверка.
Логика на уровне адаптера — это одна из тех скучно звучащих идей, которые могут стать очень серьезными позже. LoRA и QLoRA распространены, потому что они дешевы в использовании и легко перемещаются. Это означает, что многие будущие инструменты ИИ могут быть построены как базовые модели плюс маленькие адаптеры. Если логика вознаграждений останется грубой, маленькие команды данных будут погребены. Если логика вознаграждений станет острее, они смогут зарабатывать на своем точном преимуществе.
Это меняет, как люди смотрят на данные.
Не как куча.
Как инструмент с отпечатком.
OpenLedger (OPEN) делает ставку на то, что ценность ИИ не должна останавливаться на выходе. Она должна проходить через каждый слой, который сформировал этот выход. Базовая модель получает свою долю. Адаптер получает свою долю. Набор данных для настройки получает свой справедливый маршрут.
Не нужно громких обещаний.
Если это сработает, атрибуция на уровне адаптера может стать тихим мостом между навыками ИИ и справедливой оплатой. А тихие мосты в крипте могут иметь большее значение, чем громкие дороги.
