

Раньше я думала, что владение данными — это простая фраза, пока ИИ не сделал её скользкой. У фото есть владелец. У предложения есть автор.
Набор данных не остаётся простым надолго. После того как его очистят, пометят, смешают и используют ИИ, его оригинальный источник становится размытым. Когда появляется окончательный ответ, он может не напоминать ни один отдельный вклад. Вот где старые идеи о владении перестают быть достаточными. Это задаёт вопрос: кто владеет файлом? ИИ задает что-то страннее: кто сформировал поведение?
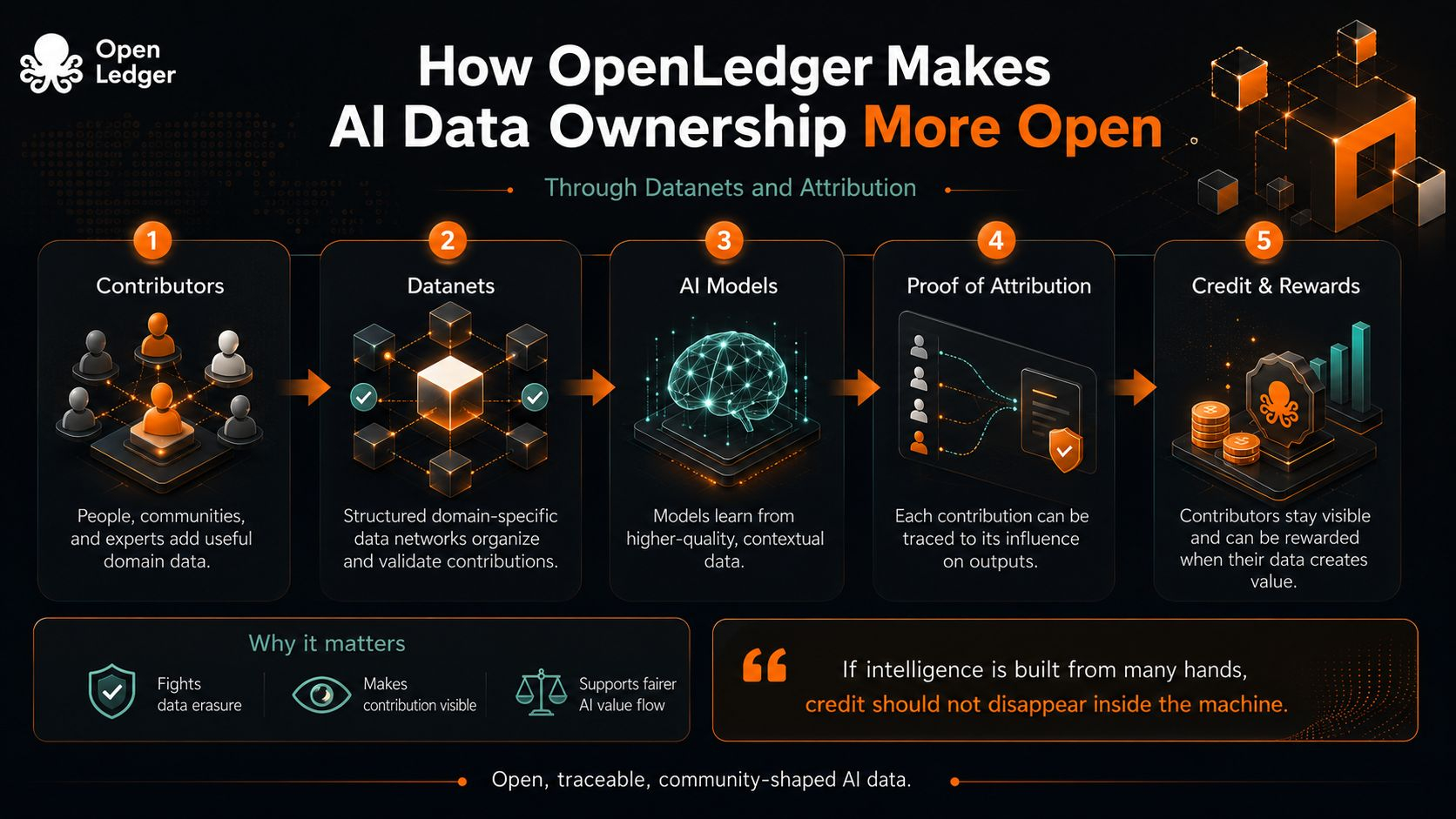
Вот в каком напряжении, похоже, находится OpenLedger с Datanets и атрибуцией. Он не только пытается сказать, что люди должны владеть данными в смысле частной собственности. Он пытается сделать владение более открытым, делая вклад видимым после того, как данные покидают чьи-то руки.
Я считаю это различие важным. В большинстве AI-систем данные входят как толпа, заходящая на стадион. Оказавшись внутри, лица исчезают. Финальная модель работает, приложение получает внимание, а люди, которые предоставили полезные примеры, становятся фоновым шумом. Иногда это были исследователи. Иногда сообщества. Иногда обычные пользователи, чьи знания имели структуру до того, как компания превратила их в топливо. Неприятный стандарт – это не просто экстракция. Это стирание.
Datanets, по крайней мере как идея, противостоят этому стиранию, предоставляя данным место для сбора с контекстом. Вместо того чтобы рассматривать всю информацию как одну гигантскую кучу, они организуют вклады вокруг конкретных областей, целей и сообществ. Это звучит мелко, почти административно, но это меняет моральную структуру системы. Вклад больше не просто поглощается моделью. Он входит в сеть, где его происхождение, использование и ценность могут быть обсуждены.
Атрибуция – это самая сложная часть. Записать, что кто-то что-то загрузил, легко. Гораздо сложнее доказать, что это действительно важно. Proof of Attribution от OpenLedger указывает на эту вторую проблему: не только отслеживание данных, но и связывание их с выходами модели и потоками вознаграждений. Вот где идея становится интересной для меня, потому что она рассматривает собственность не как закрытую коробку, а как живые отношения. Ваши данные важны, если они помогают формировать ответ. Ваши заслуги не должны исчезать только потому, что модель стала бегло говорить.
Тем не менее, я не хочу притворяться, что это решает все. Атрибуция может стать своей собственной бюрократией. Плохие данные можно аккуратно отслеживать. Поверхностные вклады могут преследовать вознаграждения. Сообщества могут быть сведены к таблицам лидеров, если дизайн небрежен. Реальный тест заключается не в том, сможет ли OpenLedger описать более чистую систему. Многие проекты могут это сделать. Тест в том, сможет ли система справляться с неаккуратным человеческим вкладом, не упрощая его до еще одной игры с очками.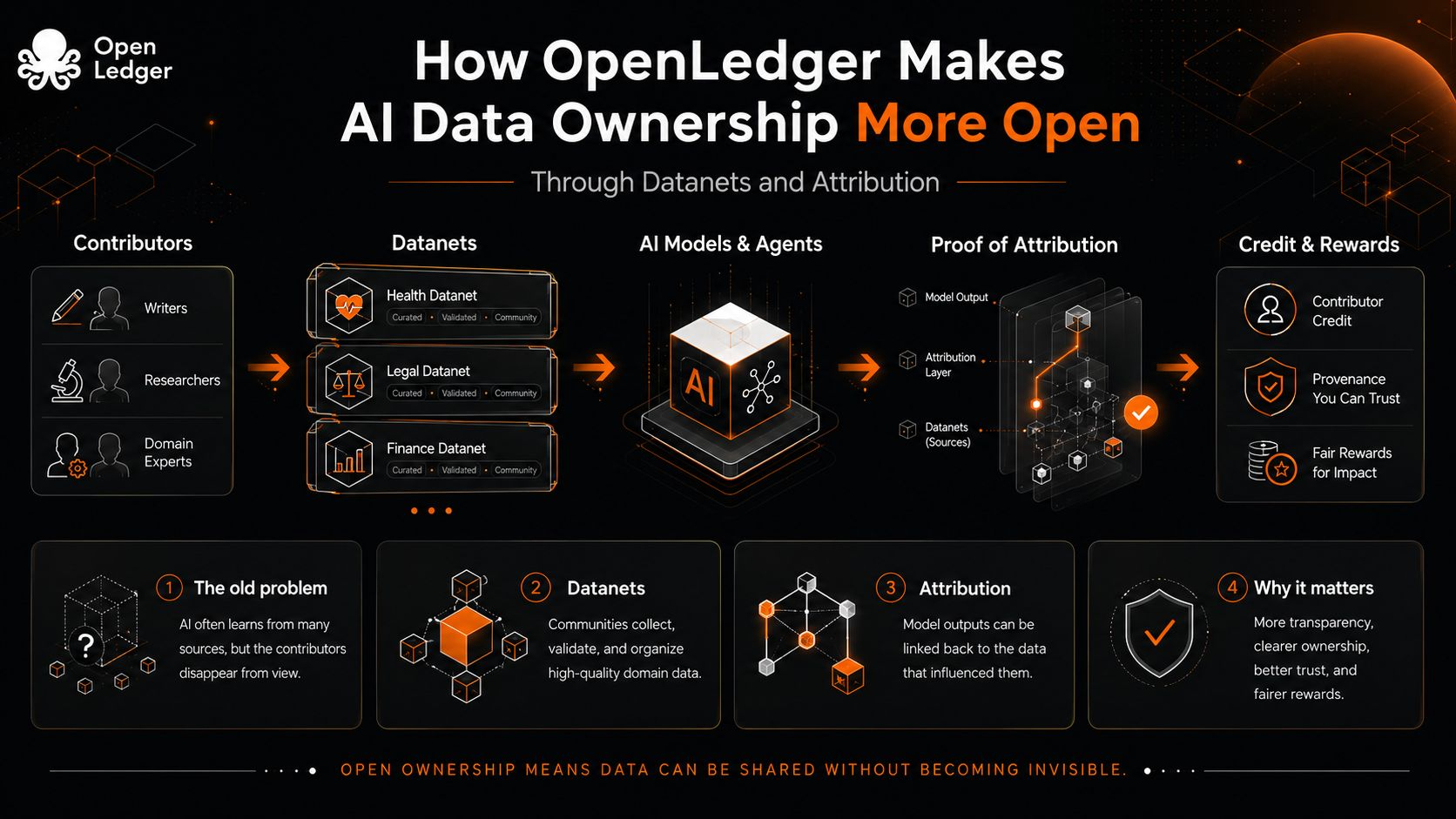
Но направление имеет значение. AI заставил собственность казаться странно закрытой, даже когда интернет выглядит открытым. Знания движутся повсюду, но заслуги часто никуда не уходят. Datanets и атрибуция предлагают другой стандарт: данные могут быть поделены, не становясь безхозными, использованы, не становясь невидимыми, и монетизированы, не притворяясь, что модель создала ценность одна.
Вот почему я вижу идею OpenLedger не как готовый ответ, а скорее как давление на экономику AI. Она задает простой, но трудный вопрос: если интеллект строится из многих рук, почему только у финальной машины должно быть имя? Этот вопрос кажется запоздалым и, возможно, полезным, потому что отказывается оставаться абстрактным.
