
OpenLedger is not trying to be another loud AI token with a clean slogan and a thin product behind it. The project is aiming at something more specific: connecting AI data, models, agents, and liquidity into one working economic loop.
That sounds simple until you look at how AI usually works. Data goes in. A model gets trained. A user pays for the final output. Somewhere in the middle, a lot of people and systems create value, but most of them never get recognized. The dataset that made the model sharper disappears. The fine-tuning work gets buried. The agent that uses several intelligence layers looks like one smooth product from the outside. The value collects at the top, while the lower layers stay invisible.
OpenLedger is built around that gap.
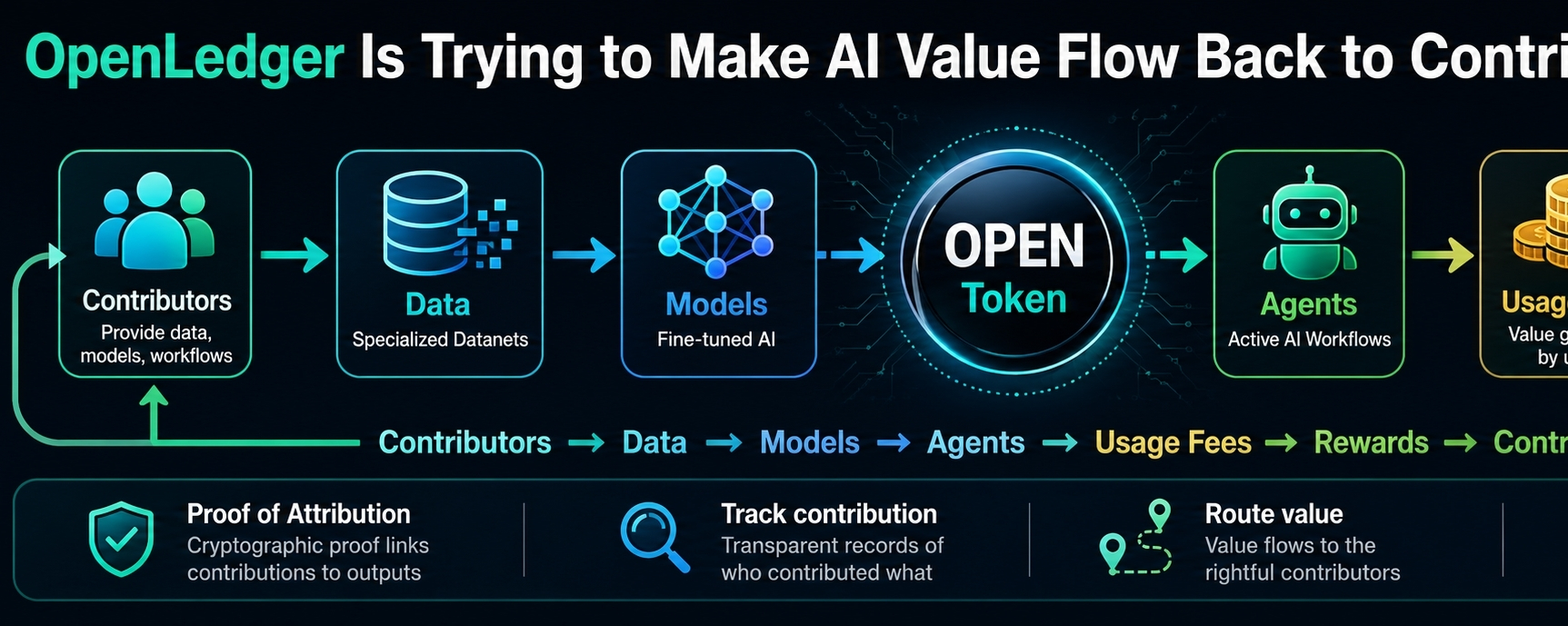
The project’s main idea is that AI should not only produce answers. It should also show where the value came from. If a dataset improves a model, that contribution should not vanish. If a model powers an agent, that usage should be trackable. If an agent creates real demand, the economics should move through the system instead of getting trapped in one place.
This is where OPEN becomes important. The token is not just there for market attention. In OpenLedger’s design, OPEN sits inside the network as the asset used for activity, access, payments, incentives, and rewards. It is meant to move across the AI stack, from data contribution to model usage to agent execution.
The strongest part of the project is the way it treats data. Most AI projects talk about data like it is just fuel. OpenLedger treats it more like an asset that can keep earning if it continues to create value. That is a big difference.
A good dataset is not just a file. In AI, it can be the reason a model understands a niche market, a local language, an industry workflow, or a specific user behavior pattern. But without ownership and attribution, that dataset becomes invisible once it is absorbed. OpenLedger is trying to keep that data economically alive.
Its Datanets are designed for specialized data communities. The point is not to collect random information and call it valuable. The point is to organize useful data around clear areas where AI models need depth. That could be finance behavior, on-chain activity, risk patterns, local knowledge, technical documentation, user intent, or any narrow field where generic models usually miss context.
This matters because AI is moving toward specialization. Broad models can answer many things, but serious use cases need sharper intelligence. A trading agent needs market structure and liquidity behavior. A security assistant needs contract patterns and exploit history. A research agent needs clean source material. A regional AI product needs language that sounds real, not translated.
OpenLedger wants these specialized data layers to connect directly with models and rewards.
The hard part is attribution. It is easy to say contributors should be paid. It is much harder to prove which contribution mattered. OpenLedger’s Proof of Attribution is the project’s attempt to solve that. The idea is to track how data, models, and other AI components influence outputs, then route rewards back to the right contributors.
This is where the project becomes more serious than a normal AI narrative. It is not only asking people to believe AI will grow. Everyone already knows that. It is asking whether AI value can be measured and shared in a cleaner way.
If OpenLedger gets this right, a contributor does not need to own the final product to earn from it. They can provide a useful data layer. A developer can build a model on top of that data. An agent can use the model. Users can create demand. The reward can move back through the chain.
That is the loop.
Data feeds models. Models power agents. Agents create usage. Usage creates fees. Fees move back through OPEN.
The model layer is the second major piece. OpenLedger is not only building around raw data. It also gives builders a way to turn that data into usable intelligence. This is important because data without deployment is just inventory. It may be valuable, but it is not active.
The project’s model-building side is meant to help specialized AI models come online faster. Builders can work with focused data, create model layers, register them, and make them usable inside applications or agents. Once that happens, data is no longer sitting still. It becomes part of a live system.
That is where liquidity begins to look different.
In normal crypto talk, liquidity usually means trading volume. For OpenLedger, liquidity has a wider meaning. It is about making AI contribution move. A dataset can become useful. A model can earn from usage. An agent can create recurring demand. A contributor can receive rewards when their input matters.
This is not the same as simply launching a token and waiting for attention. The project is trying to create a market where AI assets can have cash flow, reputation, and measurable use.
The agent layer makes this even more important. A model responds when someone asks. An agent can keep working. It can monitor, compare, execute, decide, route, and react. That makes agents much more active than normal AI tools.
Once agents become active, they need a deeper economic system behind them. They may use multiple data sources, several models, and different logic layers in one task. From the outside, the user may only see one result. Behind that result, many pieces may have created value.
OpenLedger’s structure is built for that kind of environment.
An agent using OpenLedger should not just consume intelligence blindly. It should create a trail of usage. Which model did it use? Which data made the model better? Which contributor helped shape the result? Which part of the system deserves payment?
These questions sound technical, but they are really economic questions.
AI agents will not scale cleanly if value cannot be tracked. If everyone contributes and only the final interface earns, the system becomes extractive. OpenLedger is trying to build a different version, where the backend intelligence layers can also participate in the upside.
This is why OPEN is positioned as more than a simple utility token. It is the connector between data ownership, model access, agent usage, and reward distribution. The token’s strength depends on how much real activity happens inside that loop.
That is also where the risk sits.
OpenLedger still has to prove that the system can attract useful data, serious builders, active agents, and real demand. A strong design is not enough. Crypto has seen many projects with clean architecture and weak usage. The market eventually stops rewarding diagrams. It starts asking for activity.
The biggest test for OpenLedger is not whether the AI story is exciting. It is whether the project can make attribution work in a way people trust.
If contributors believe the reward system is fair, they have a reason to bring better data. If better data comes in, models can improve. If models improve, agents become more useful. If agents become more useful, usage increases. If usage increases, OPEN has a stronger reason to move through the network.
That is the positive flywheel.
But the reverse is also possible. If attribution feels unclear, contributors may not care. If data quality stays weak, models lose edge. If models have no edge, agents become replaceable. If agents are replaceable, demand fades. That is the part people should not ignore.
OpenLedger’s opportunity is strongest in specialized AI, not generic AI. Generic AI is crowded. Specialized AI is where data ownership and attribution actually matter.
A finance-focused agent needs deep market behavior. A security model needs technical attack patterns. A research assistant needs trusted information. A regional model needs real language data. A workflow agent needs domain-specific instructions. These are the areas where OpenLedger’s structure can make sense because the data itself has clear value.
The project is trying to build the rail where those narrow intelligence markets can form.
That is the real picture of OpenLedger. It is not just about AI. It is about who gets paid when AI becomes useful.
OPEN is the asset designed to move value between the people providing data, the builders creating models, the agents generating activity, and the users creating demand. If the system works, OPEN becomes part of an AI economy where contribution does not disappear after training. It keeps a link to usage.
There is no need to dress that up with hype. The idea is already ambitious enough.
OpenLedger is trying to solve one of AI’s most uncomfortable problems: intelligence is built from many sources, but value is usually captured by very few. The project wants to make that value traceable, liquid, and shareable.
If it can do that, OpenLedger becomes more than another AI crypto project. It becomes a working market for AI contribution.