I will be honest, Not access to chatbots.
That part has already become normal.
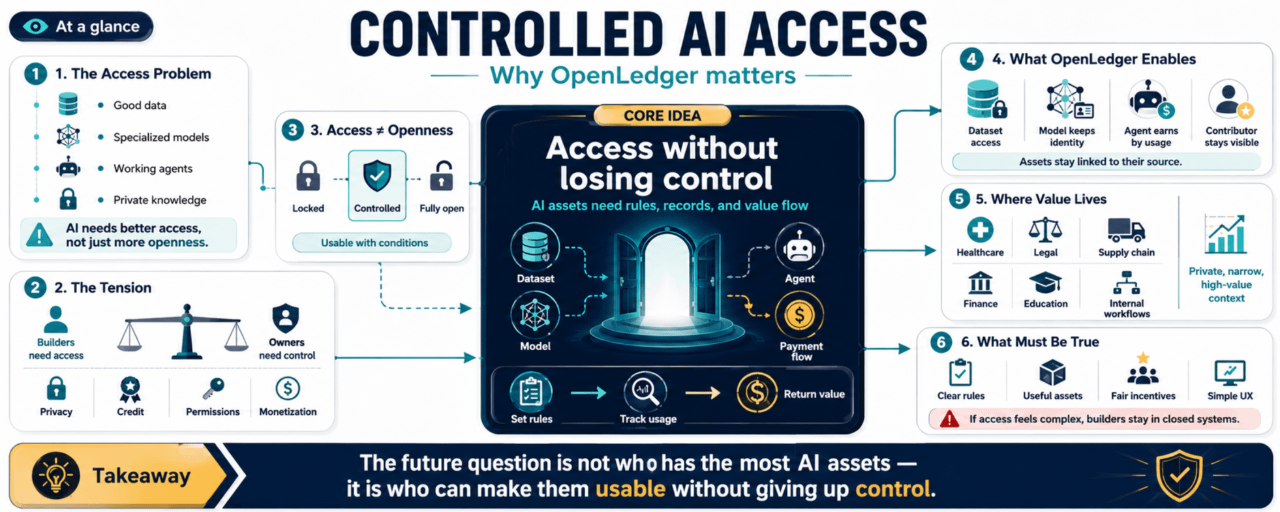
The deeper issue is access to the things that make AI useful.
Good data.
Specialized models.
Working agents.
Clean feedback loops.
Domain knowledge that did not come from the open internet.
Those things are not equally available.
Some companies have years of private information sitting inside their systems. Some teams have built small models that solve very specific problems. Some developers have agents that work well in narrow workflows. Some communities have created knowledge through repeated discussion, correction, and use.
But most of these assets do not move easily.
They are useful, but not always reachable.
That is where @OpenLedger feels worth looking at from another angle.
It is not only about monetizing AI assets. It is also about making access more structured.
Because access is not the same as openness.
This is an important difference.
A dataset does not need to be fully public to be useful.
A model does not need to be free for everyone to have value.
An agent does not need to run everywhere to create impact.
Sometimes the better question is not, “Can anyone use this?”
It is, “Can the right people use this under clear rules?”
That is where things get interesting.
AI builders often need specific inputs. Not just more data, but better-matched data. Not just bigger models, but models trained for the task. Not just general agents, but agents that understand a certain workflow.
At the same time, the owners of these assets may not want to simply hand them over.
And that makes sense.
A company may not want to expose raw customer data.
A researcher may not want a model reused without credit.
A developer may want to earn if an agent keeps being used.
A community may want control over how its shared knowledge is applied.
So there is a tension.
AI needs access.
Asset owners need control.
#OpenLedger seems to sit between those two needs.
It points toward a system where data, models, and agents can be made available without becoming completely detached from their source. The asset can have rules. The usage can be recorded. The value can flow back if the asset helps create something useful.
That may sound small, but it changes the relationship.
Instead of treating AI assets as things that must be either locked away or fully given up, there is a middle path. Controlled access. Traceable use. Ongoing monetization.
This is probably where blockchain has a more practical role.
Not as a replacement for AI.
Not as a slogan attached to AI.
More like a coordination layer for assets that need permissions, records, and payments.
You can usually tell when coordination is missing because people start building around the problem manually. Private deals. Custom licensing. Closed partnerships. One-off integrations. Long approval cycles. Trust-based sharing. $AIA
Those things can work, but they do not scale cleanly.
AI is moving too fast for every useful asset to require a private negotiation.
If OpenLedger can help make the rules clearer, then more assets may become usable without forcing owners to give up everything. That is the practical idea underneath the surface.
And it matters because the future of AI may not be built only from public data and giant models.
A lot of the next value may come from private, narrow, hard-to-access knowledge.
Healthcare workflows.
Legal documents.
Supply chain data.
Financial patterns.
Industrial logs.
Education feedback.
Support conversations.
Internal business processes.
These are not always glamorous sources. But they are often where real usefulness lives.
The problem is that they are sensitive, fragmented, and difficult to price.
So they stay behind walls.
OpenLedger’s approach suggests that these walls do not always need to be removed. Maybe they just need better doors. $PLAY
That is a calmer way to think about it.
Not everything should be open. Not everything should be hidden. Some things should be accessible with conditions.
And once conditions can be expressed clearly, new markets become possible.
A builder could access a dataset without owning it outright.
A model could be used in a larger system while still keeping its identity.
An agent could operate inside a workflow and earn from actual usage.
A contributor could participate without disappearing into the final product.
Of course, the system has to prove itself.
The rules need to be understandable. The assets need to be useful. The incentives need to be fair enough for people to care. And the experience has to be simple enough that builders do not avoid it.
That is always the hard part.
Still, the access problem is real.
AI wants more context, but the best context is often locked inside places that cannot simply open everything up. That is the gap OpenLedger is trying to work around. #BNBBreaks740USDTUp12Percent
Maybe that is the angle that makes the most sense.
Not AI data as something to extract.
Not models as files to sell once.
Not agents as isolated tools.
More like a controlled access layer for the useful pieces of AI that are currently hard to reach.
And if that layer works, even quietly, the question begins to shift.
From “Who has the most AI assets?”
to
“Who can make their AI assets usable without losing control?”
That feels like the real conversation starting to form.
$OPEN
Статья
One of the quiet problems in AI is access.
Указанный в этой статье токен может быть подвержен высокой волатильности. Изучите проект самостоятельно.
Отказ от ответственности: на платформе опубликованы материалы и мнения третьих лиц. Не является финансовой рекомендацией. Может содержать спонсируемый контент. См. Правила и условия.