
昨天深夜调试一个老项目的训练 pipeline 时,我关掉IDE的高亮模式,只留屏幕上跳动的日志和测试网调用曲线。那种安静又略显疲惫的时刻,最容易让人把当下 AI 生态的格局想得更透彻。现在的大厂模式,越来越像一套高度集成的中心化工厂:无数开发者把零散的算力、标注数据和实验迭代默默输送上去,最后的模型红利却被少数几家牢牢握在手里。这让我不由想起早年以太坊生态里,一些早期应用对用户流动性和数据贡献的隐形调用,那种熟悉的循环感又一次浮现。
最近 OpenLedger 尝试构建的归因证明机制,@OpenLedger 倒是让我这个长期在去中心化赛道摸爬滚打的人多看了几眼。他们用数学模型去量化每份训练数据对最终模型输出的真实贡献,并尝试让这些贡献变成链上可验证、可流动的资产。这种把数据真正资产化的思路,在技术层面确实有它的诚恳之处,尤其搭配 OpenLoRA 这种支持多模型共享底层硬件的模块化设计,能让开发者不用每次都从头搭建全套环境,大幅降低了上手门槛。
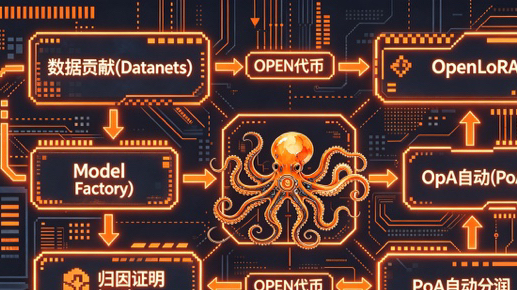
不过我这些年的经验告诉我,再前沿的架构也绕不开经济循环的自洽性。$OPEN 早期份额逐步释放带来的供给压力是客观存在的,如果生态里没有足够多的真实业务场景让开发者主动消耗或质押代币来对冲,单纯的概念热度很难长久支撑流动性。我自己过去在几个类似项目里踩过坑,所以现在看任何东西,第一反应都是去翻它的实际调用数据和代币绑定深度,而不是只听表面上的合作消息。$BTC
这两周我反复在测试网跑了几轮实验,模块化架构的实际感受确实不错。你可以把数据贡献、模型微调和推理服务拆成相对独立的乐高积木,按需拼装,不再像以前那样被显存冲突和版本管理拖住后腿。Openledger这种灵活性让我能把更多精力放在模型效果本身,而不是基础设施的琐碎维护上。当然,门槛降低也意味着需要更强的经济机制来过滤低质量噪声,否则长期看可能会稀释整个生态的信号强度,这一点我目前还在持续观察。
我现在每天都会抽时间看一眼测试网的质押曲线和调用频率,就像过去盯自己写的服务延迟指标一样,已经成了习惯。#OpenLedger 这套系统在技术拆解上给我留下了比较扎实的印象,它确实抓住了数据确权和硬件共享这两个老痛点,模块化的思路也让扩展性看起来更有潜力。但我对它的态度始终是吃过几次亏之后的谨慎乐观,主网上线后,真正的胜负手还是要看开发者是否愿意持续为高质量数据集和模型调用付出代币,而不是只停留在早期激励阶段。
总体而言,OpenLedger 的方向是值得认可的,实际工程体验也超出我最初的保守预期。但项目最终能不能跑通,还得靠长时间的真实业务吞吐量来验证。在这个阶段,我选择继续小范围测试,多留一份清醒,少一些冲动。这大概就是一个被市场反复教育过的开发者,最本能的自我保护方式。