Я постоянно возвращаюсь к одному простому вопросу, когда смотрю на OpenLedger: если ИИ продолжает становиться умнее благодаря человеческим данным, человеческим знаниям, человеческой обратной связи и созданным людьми моделям, то почему большинство наград все еще идет платформам, которые сидят посередине?
Этот вопрос больше, чем открытость сама по себе, но именно он привлекает мое внимание к OpenLedger. Многие проекты ИИ говорят о скорости, агентах, вычислениях или производительности моделей. Эти вещи, конечно, важны. Но OpenLedger смотрит на что-то более глубокое: экономический слой под ИИ. Он задает вопросы о том, кто внес ценность, откуда эта ценность пришла и как награды должны распределяться, когда ИИ-системы на самом деле используют эти вклады.
Сейчас экономика ИИ все еще кажется мне очень неравномерной. Люди создают контент, производят данные, маркируют информацию, строят сообщества, тестируют продукты, дают обратную связь и улучшают системы каждый день. Эта активность становится полезным учебным материалом для моделей ИИ, но вкладчик обычно исчезает, как только данные попадают в машину. Модель улучшается, компания растет, продукт становится более ценным, а первоначальный источник этой ценности становится почти невозможно отследить.
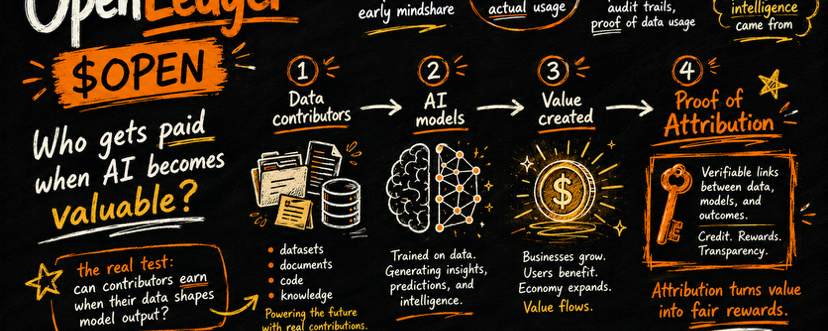
Вот где идея OpenLedger о Proof of Attribution важна. OpenLedger разработан для отслеживания того, какие данные влияют на выходы моделей ИИ и вознаграждения вкладчиков через $OPEN. Binance Research описывает OpenLedger как блокчейн ИИ, где разработчики могут собирать специализированные данные через Datanets, строить модели с помощью Model Factory и использовать Proof of Attribution, чтобы связать выходы моделей с данными, которые помогли их сформировать.
Для меня это меняет разговор. Это сдвигает ИИ от "кто владеет самой большой моделью?" к "кто помог создать интеллект внутри этой модели?" Это гораздо более интересный вопрос.
Почему данные не должны оставаться невидимыми навсегда.
Старый интернет заставлял данные казаться бесплатными. Люди публиковали, искали, комментировали, рецензировали, загружали, маркировали и взаимодействовали, не задумываясь о том, насколько ценным все это поведение станет позже. Платформы собирали это, потому что могли. ИИ сделал дисбаланс более очевидным, потому что теперь данные используются не только для рекламы или рекомендаций; они используются для создания интеллекта.
И интеллект становится экономической силой.
Вот почему концепция Datanets от OpenLedger кажется важной. Datanets - это наборы данных, принадлежащие сообществу, созданные для специализированного обучения ИИ, что означает, что данные не должны оставаться пассивным сырьем, контролируемым закрытыми платформами. Документация OpenLedger описывает это как инфраструктуру для обучения и развертывания специализированных моделей с использованием наборов данных, принадлежащих сообществу, с загрузками наборов данных, обучением моделей, кредитами вознаграждений и деятельностью управления, выполняемой в цепочке.
Мне нравится это направление, потому что я не верю, что будущее ИИ будет только одной гигантской общей моделью, отвечающей на все. Я думаю, что будущее также потребует меньших, специализированных моделей, построенных вокруг сильных нишевых данных. Данные в области здравоохранения, торговли, юриспруденции, образования, игр, предприятий — все эти области нуждаются в интеллекте, который понимает контекст. Общая модель может казаться умной, но специализированные данные делают ИИ полезным в реальных отраслях.
Вот где  имеет больше смысла для меня. Если специализированные данные становятся ценными, то должна быть возможность отслеживать их, оценивать, вознаграждать и связывать с ИИ моделями, использующими их. OpenLedger пытается построить этот слой.
имеет больше смысла для меня. Если специализированные данные становятся ценными, то должна быть возможность отслеживать их, оценивать, вознаграждать и связывать с ИИ моделями, использующими их. OpenLedger пытается построить этот слой.
Настоящая проблема - это измерение вклада.
Это также то, где я остаюсь реалистом. Легко сказать "вкладчики должны быть вознаграждены". Гораздо сложнее правильно измерить вклад.
ИИ не работает как простая машина, где один вход создает один выход. Модель может формироваться тысячами наборов данных, множеством раундов тонкой настройки, разными ярлыками, подсказками, адаптерами, петлями обратной связи и паттернами использования. Данные одного человека могут иметь большое значение в одном случае и очень мало в другом. Некоторые данные со временем становятся более ценными. Некоторые данные теряют ценность. Некоторые вклады являются основополагающими, но их трудно обнаружить позже.
Так что сложная часть для OpenLedger не только запись активности в цепочке. Сложная часть - это доказать влияние таким образом, чтобы вкладчики, разработчики и пользователи могли доверять.
Вот почему я думаю, что Proof of Attribution - это самая важная часть проекта. Если OpenLedger сможет сделать вклад ИИ измеримым на уровне инференции, тогда он станет больше, чем обычный утилитарный токен. Он станет частью системы оплаты и вознаграждений за создание ценности ИИ. Binance Academy также описывает OpenLedger как блокчейн-платформу для ИИ, где пользователи могут создавать, делиться и использовать наборы данных для обучения специализированных моделей, с взаимодействиями ИИ, прослеживаемыми обратно к источникам данных, а вкладчики вознаграждаются за свою работу.
Эта идея мощная, потому что она превращает использование ИИ в нечто более близкое к роялти. Если ваши данные помогают модели создавать ценность, вы должны иметь возможность зарабатывать на этой ценности. Это тот экономический цикл, которого не хватало ИИ.
Почему $OPEN не просто хайп.
Многие люди все еще будут смотреть на другие токены: цена, объем, листинг, хайп, ротация нарратива. Я понимаю это, потому что это крипто, и людям естественно сначала важны графики. Но я думаю, что OpenLedger нужно оценивать иначе.
Настоящий вопрос не только в том, будет ли памп во время цикла ИИ. Настоящий вопрос в том, сможет ли OpenLedger создать экосистему, где вкладчики данных, строители моделей, агенты и разработчики будут иметь причины для участия.
Токен $OPEN описан Фондом OpenLedger как поддерживающий три основных процесса: газ для блокчейна OpenLedger AI, сборы за проведение инференции и построение моделей ИИ, а также вознаграждения для вкладчиков данных через Proof of Attribution.
Это дает токену более четкую роль внутри системы. Он не просто сидит рядом с продуктом как спекулятивный актив. Он предназначен для движения через фактический рабочий процесс: вклад данных, построение моделей, инференция, вознаграждения и деятельность экосистемы.
Но снова, дизайн токена становится значимым только если платформа привлекает реальное использование. Токен вознаграждения без ценных данных становится шумом. Платформа модели без строителей становится пустой инфраструктурой. Система вкладов без справедливой проверки становится легкой для манипуляции.
Для меня $OPEN интересен, но ему еще нужно доказать самое сложное: устойчивое соответствие.
Проблема стимулов, которую никто не может игнорировать.
Когда деньги входят в систему, поведение меняется. Это справедливо для DeFi, игр, социальных платформ и сетей вкладов ИИ. Если OpenLedger вознаграждает людей за вклад данных, некоторые люди будут вносить высококачественную информацию. Другие могут загружать низкокачественные данные, дублированный контент, поддельные ярлыки или что угодно, что они думают, что система вознаградит.
Это не критика OpenLedger в частности. Это реальность открытых систем стимулов.
Лучшая версия OpenLedger - это сеть, где высококачественные данные становятся более ценными, потому что атрибуция и вознаграждения прозрачны. Слабая версия - это система, где люди оптимизируют вознаграждения вместо полезности. Разница между этими двумя результатами зависит от проверки, управления, контроля качества данных и от того, сможет ли модель вознаграждений противостоять манипуляциям.
Вот почему я не вижу OpenLedger только как технический проект. Это также эксперимент в области экономического дизайна.
И честно говоря, это делает его для меня более интересным. Проект не пытается решить небольшую проблему UX. Он касается одного из самых больших вопросов в ИИ: как мы можем справедливо координировать людей и ресурсы, которые делают интеллект возможным?
Более крупная ставка OpenLedger.
Более крупная ставка OpenLedger заключается в том, что ценность ИИ не останется запертой внутри нескольких централизованных компаний навсегда. Возможно, данные станут более ликвидными. Возможно, модели станут более модульными. Возможно, автономные агенты начнут взаимодействовать друг с другом экономически. Возможно, специализированные системы ИИ нуждаются в прозрачных слоях атрибуции, потому что бизнес, создатели и сообщества будут требовать доказательства того, как используются их данные.
Это будущее не гарантировано. Большие платформы ИИ все еще имеют огромные преимущества: вычисления, капитал, распределение, талант и доверие пользователей. Большинство людей выбирают удобство перед децентрализацией. Если централизованный инструмент ИИ быстрее, плавнее и дешевле, многие пользователи выберут его, не заботясь о том, куда течет ценность.
Так что OpenLedger не строит для самой легкой версии рынка. Он строит для будущего, где пользователи и строители ИИ больше заботятся о собственности, атрибуции и экономической видимости.
Я думаю, что это будущее возможно, но это займет время.
Тем не менее, некоторые идеи имеют значение до того, как рынок полностью их поймет. Биткойн заставил людей переосмыслить деньги. Эфириум заставил людей переосмыслить программируемые активы. DePIN заставил людей переосмыслить координацию физической инфраструктуры. OpenLedger пытается заставить людей переосмыслить вклад ИИ и собственность.
Вот почему я продолжаю следить за $OPEN.
Мой честный взгляд на $OPEN.
Я не вижу OpenLedger как идеальный проект. Я не думаю, что какой-либо проект блокчейна ИИ полностью решил вопросы атрибуции, качества данных, вознаграждений вкладчиков и экономики моделей. Это сложные проблемы. Будут грязные стимулы. Будут вопросы управления. Будут технические пробелы. Будут моменты, когда нарратив движется быстрее, чем продукт.
Но я также думаю, что OpenLedger задает правильный вопрос.
Будущее ИИ может принадлежать не только тому, кто создаст самую умную модель. Оно может принадлежать тому, кто построит наиболее справедливую и эффективную систему для организации ценности, стоящей за этой моделью.
Вот почему @OpenLedger выделяется для меня. Он не только пытается сделать ИИ более мощным. Он пытается сделать ценность ИИ более видимой.
И в мире, где интеллект становится одним из самых важных экономических активов, видимость может стать настоящим основанием собственности.