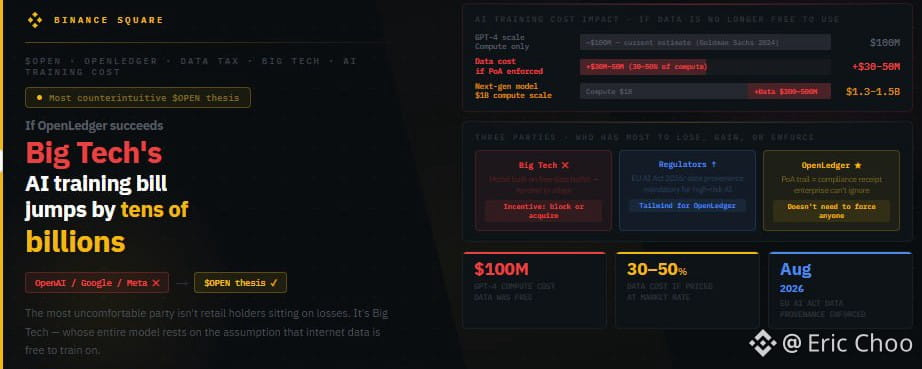
Я начал задумываться об этом после того, как прочитал цифры в отчете Goldman Sachs за 2024 год: оценочные затраты на обучение GPT-4 составляют около 100 миллионов долларов. Эта сумма не учитывает стоимость данных, потому что данные берутся бесплатно из интернета. Если данные не бесплатные, сколько это будет стоить? Никто точно не знает, но многие оценки предполагают, что высококачественные курируемые данные могут составлять 30 до 50% стоимости обучения, если их оценивать по рыночным ценам. Для GPT-4 это 30 до 50 миллионов долларов только за один запуск обучения. Для следующей модели может потребоваться 1 миллиард долларов на обучение, а стоимость данных составит от 300 до 500 миллионов долларов.
Это то, что @OpenLedger и $OPEN пытаются построить инфраструктуру для: мир, в котором каждый набор данных имеет ценник, каждое решение имеет тропу роялти, и лаборатории ИИ не смогут продолжать бизнес-модель "бесплатного буфета данных", как они это делают. Не через законы, не через адвокацию, а через протокольный слой on-chain, который, если будет достаточно принят, станет стандартом, игнорировать который нельзя.
Я хочу прямо сказать то, о чем оба исследовательских файла, которые я прочитал, намекают, но не говорят прямо. Модель Spotify является самым близким примером того, что пытается сделать OpenLedger. До Spotify маленькие музыканты ничего не получали от незаконных загрузок. После Spotify они получают микро-р royalty каждый раз, когда их песня транслируется, даже если это небольшая сумма. Более того, этот стандарт изменил всю индустрию музыки. Не потому, что Spotify добрый, а потому что они построили инфраструктуру достаточно хорошую, чтобы обеспечивать роялти в массовом порядке, так, что индустрия музыки не могла это игнорировать.
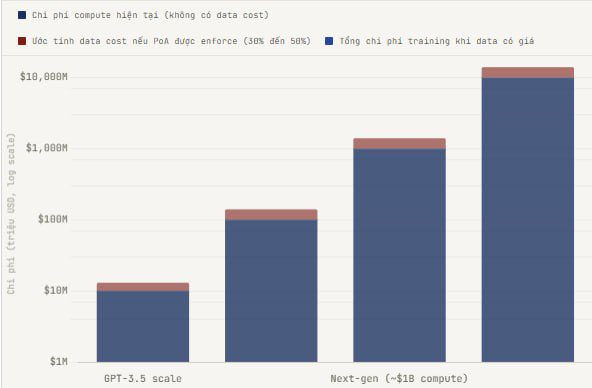
Проблема в том, что OpenLedger не может принудить Big Tech делать что-либо, по крайней мере, не в прямом смысле. Google может продолжать обучаться на Common Crawl бесплатно, даже если OpenLedger существует. Никто не может этому помешать с помощью смарт-контрактов. Это настоящая уязвимость тезиса, и я думаю, что важно сказать об этом, а не просто писать однобокий бычий контент.
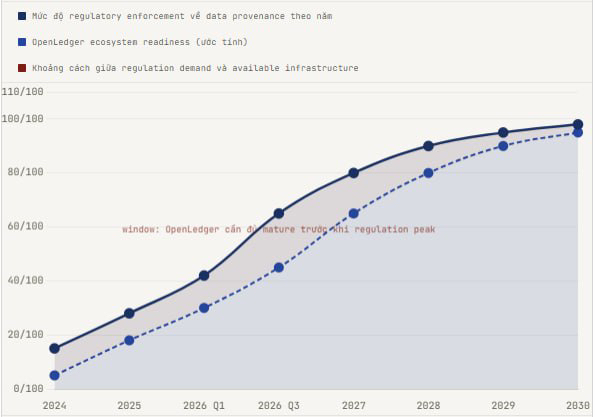
Но вот как OpenLedger может создать изменения не прямым принуждением, а альтернативным путем: если модель, обученная на OpenLedger DataNet с проверенными, курированными, специализированными данными, последовательно превосходит модели, обученные на шумных интернет-данных в регулируемых областях, таких как здравоохранение или юридический ИИ, то корпоративные покупатели предпочтут модели от OpenLedger. Не потому, что им важна справедливость, а потому что EU AI Act и другие регуляторные рамки начинают требовать документацию о происхождении. Больница, покупающая инструмент диагностики на базе ИИ, должна доказать регулятору, что данные для обучения этого инструмента соответствуют стандартам качества. Путь PoA OpenLedger предоставляет именно это. Естественно, без необходимости принуждать кого-либо.
Когда я смотрю на список инвесторов OpenLedger, в частности на Баладжи Сринивасана, который предсказал множество крупных технологий до их появления на рынке, это придаёт мне уверенности не потому, что Баладжи всегда прав, а потому, что он часто делает ставки, когда видит чёткий регуляторный ветер в спину. EU AI Act, указ Президента США по ИИ и рамки управления ИИ в Сингапуре все движутся в сторону обязательного происхождения данных. OpenLedger не нужно убеждать Big Tech. Им просто нужно дождаться, пока регуляторы сделают это за них.
 То, что заставляет меня верить в этот долгосрочный тезис, не хайп или FOMO. Это простая экономическая логика. За 20 лет интернета всё, что кажется бесплатным, в конечном итоге становится ценным. Бесплатная электронная почта, затем фильтры спама и email-маркетинг стали миллиардной индустрией. Бесплатный поиск, затем SEO и Google Ads стали значительной частью ВВП интернета. Бесплатные социальные медиа, затем экономика внимания и брокерство данных стали бизнес-моделью Meta и Twitter. Бесплатные данные ИИ, и что будет дальше? OpenLedger ставит ставку на то, что ответ — экономика атрибуции, где каждый след данных имеет ценник on-chain.
То, что заставляет меня верить в этот долгосрочный тезис, не хайп или FOMO. Это простая экономическая логика. За 20 лет интернета всё, что кажется бесплатным, в конечном итоге становится ценным. Бесплатная электронная почта, затем фильтры спама и email-маркетинг стали миллиардной индустрией. Бесплатный поиск, затем SEO и Google Ads стали значительной частью ВВП интернета. Бесплатные социальные медиа, затем экономика внимания и брокерство данных стали бизнес-моделью Meta и Twitter. Бесплатные данные ИИ, и что будет дальше? OpenLedger ставит ставку на то, что ответ — экономика атрибуции, где каждый след данных имеет ценник on-chain.
Я не знаю точные сроки. Может быть, 3 года. Может быть, 7 лет. Но когда все продают $OPEN из-за падения на 91%, я вижу, что то, что я покупаю, не токен, который теряет в цене. Это ставка на то, что ИИ придется платить за данные так же, как Netflix платит за контент, и OpenLedger строит инфраструктуру для сбора этих средств.
Если EU AI Act действительно введет требования по документации происхождения данных для высокорисковых систем ИИ с 2026 года, и OpenLedger будет единственной инфраструктурой с достаточным гранулярным on-chain PoA, чтобы удовлетворить эти требования, как вы думаете, Big Tech выберет интегрировать OpenLedger в свои процессы или создаст свои альтернативы, чтобы избежать зависимости от протокола on-chain, который они не контролируют?