I was going through my OpenLedger notes again late last Saturday, around the time when the market gets quiet but your mind keeps making noise, and one message from a friend stopped me for a moment. He works close to data infrastructure, so he does not ask random crypto questions just to sound smart. He asked, “If Google or Microsoft builds this tomorrow, what does OpenLedger still have left to defend?” And honestly, that question stayed with me longer than I expected, because it is not unfair. It is probably the exact question every AI crypto project has to answer at some point. If the problem is real, if the money is real, and if the demand becomes large enough, Big Tech will not sit outside and watch forever. They already have the clouds, the models, the users, the enterprise clients, the legal teams, the distribution, and the habit of turning messy ideas into neat products that companies feel safe buying.
That is the uncomfortable part about this whole OpenLedger discussion. Google does not need to understand crypto culture to build something that looks like AI data attribution. Microsoft does not need to care about decentralization to offer enterprises a dashboard that tracks datasets, model usage, payments, and permissions. They can wrap everything into Azure, GitHub, Copilot, or some clean enterprise product, then sell it with contracts, support, compliance, and a familiar invoice. For a large company, that kind of setup feels comfortable. Nobody has to explain wallets, protocols, reward systems, or why a new network matters. They just get storage, compute, model access, tracking, billing, and legal cover from the same place they already trust.
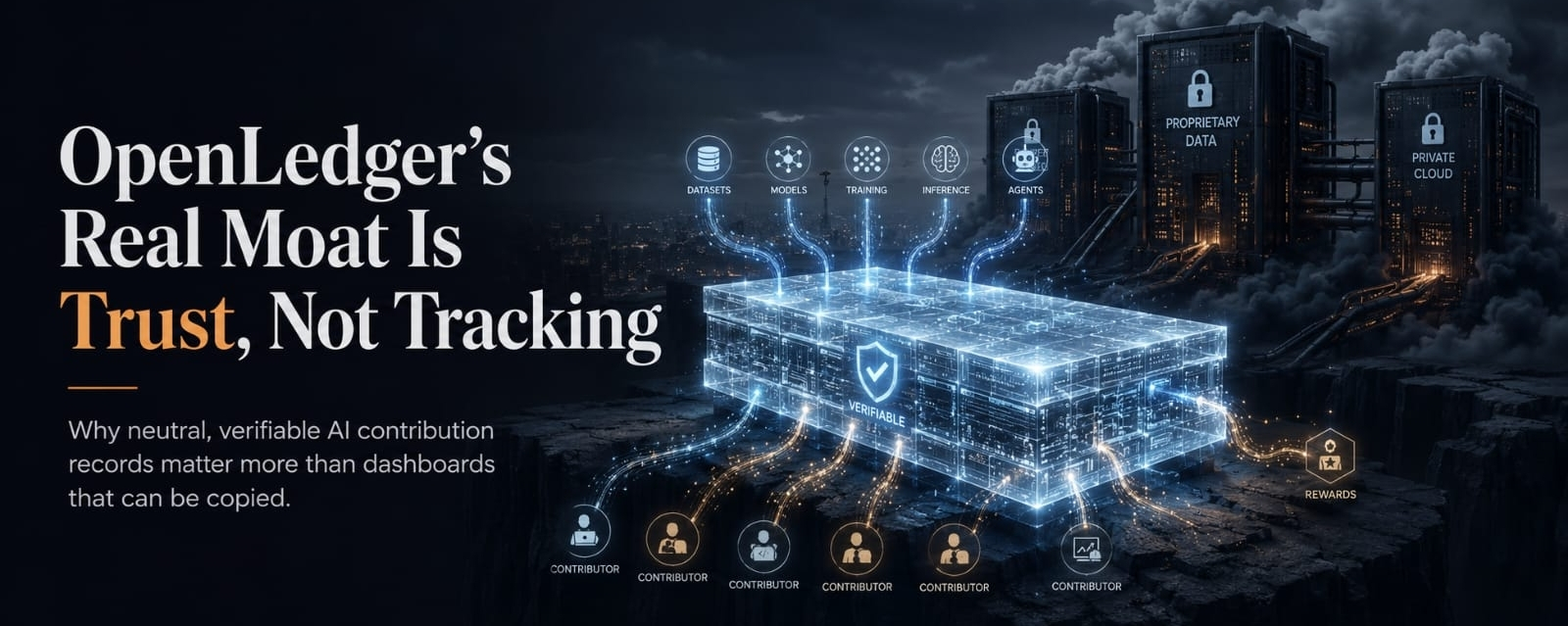
But that comfort comes with a problem that people do not always want to say out loud. Everything still happens inside someone else’s yard. The data sits in their cloud. The model runs on their infrastructure. The attribution is calculated by their system. The usage numbers come from their pipes. The billing goes through their counter. It may look clean, and it may work very well, but the warehouse owner still controls the keys, the cameras, the ledger, the shelves, and the cashier. So even if the dashboard says everything is fair, the user still has to trust the company that owns the dashboard. That is not verification. That is just a more polished form of dependence.
This is why I do not think OpenLedger can defend itself by saying it tracks data contribution. Tracking alone is not a moat. Tracking can be copied. Dashboards can be copied. Reward screens can be copied. Enterprise permissions can be copied. If enough serious customers ask for AI attribution, Big Tech can package that into a product faster than most crypto teams can fix their onboarding. So the real question is not whether OpenLedger can show who uploaded a dataset or who earned a reward. The real question is whether it can become the neutral record layer where the history of AI value is written in a way that many different participants can actually trust.
That is the bigger idea hiding underneath the simple version of the project. OpenLedger becomes more interesting when it is not just about one person uploading data and getting tracked. The stronger version is much wider than that. Who brought the dataset? Who cleaned it? Who trained or fine-tuned the model? Which data actually improved performance? Which inference request created revenue? Which AI agent used that model in a real workflow? Which contributor should receive value when the model starts producing value? If those steps can be recorded clearly enough, and if that record is not trapped behind one company’s private wall, then OpenLedger stops looking like a normal analytics tool. It starts looking like a shared memory layer for intelligence.
A simple example makes this easier to understand. Imagine a logistics company with years of delivery data sitting in ugly spreadsheets and internal systems. It knows which roads usually get congested, which warehouses slow down at certain times, which routes create missed delivery windows, and which patterns quietly damage efficiency every week. That data may not sound exciting on the surface, but for an AI model it can be extremely useful. If the model gets better at predicting delays, planning routes, reducing fuel waste, and improving delivery times, real money is created. But then the hard question starts. Which dataset actually made the model better? Was it the route data? The warehouse delay data? The driver schedule data? The weather-linked delivery history? And when that improved model is used by different agents and applications, who gets paid for the value it keeps producing?
If all of that sits inside Google’s system or Microsoft’s system, maybe the answer exists, but it exists behind their wall. They can give you reports. They can show you charts. They can write proper contracts. They can make the experience feel mature and safe. But the basic trust problem is still there. You are still depending on the same central platform to measure contribution, define value, count usage, and distribute rewards. For some enterprises, that may be acceptable because they already live inside those systems. But it does not solve the deeper issue. It only makes the issue look cleaner.
This is the lane where OpenLedger actually has a reason to exist. Not because it can beat Google at cloud. Not because it can beat Microsoft at enterprise sales. That would be an unrealistic way to frame it. Big Tech has advantages that are too large to ignore. But OpenLedger is trying to compete on a different layer. It is trying to make AI contribution more open, more visible, and more verifiable. It is trying to move attribution, usage, and rewards away from private dashboards and toward a shared record that different people can check without asking permission from one giant platform.
But even that does not automatically make OpenLedger safe. Crypto is full of beautiful words that sound powerful until the incentives disappear. Neutrality, ownership, openness, fairness, community, rewards. We have heard all of it many times. A neutral layer only matters if real participants use it for real reasons. If OpenLedger only attracts a few datasets, a few test models, and a crowd of users farming campaigns until the next shiny thing comes along, then the trust argument becomes weak. A network cannot survive on slogans. It needs useful data, serious model activity, active agents, builders who stay, contributors who care, and economic history that becomes harder to replace over time.
That is where the real moat could slowly form. A moat is not just code. It is not just a token. It is not just a loud community. In crypto, loud communities can vanish the moment rewards slow down or the chart stops moving. The stronger moat is built from trust, habit, shared history, real usage, and dependency. If contributors believe their work is being recorded fairly, if builders believe they can plug into OpenLedger without giving up control to a closed platform, and if models and agents begin carrying their contribution history through that system, then copying the surface becomes less dangerous. A company can copy the dashboard, but it cannot instantly copy the trust behind the record.
Google and Microsoft can build cleaner interfaces. They can build smoother onboarding. They can offer safer enterprise packaging. They can probably copy many of the visible features if the market becomes attractive enough. But neutrality is harder to copy because neutrality is not a button you add to a product. It is something people either believe or they do not. And people only believe it after seeing the rules work again and again without being quietly changed to benefit the platform owner. That is why OpenLedger’s real challenge is not only technical. It is social, economic, and trust-based at the same time.
The more AI grows, the louder this problem will become. Right now, people are still excited about models getting smarter and agents doing more work. But behind all of that is a messy question nobody can avoid forever. Who created the value? Who provided the data? Who improved the model? Who deserves the reward when an agent keeps using that intelligence again and again? This will not stay as a soft philosophical debate. It will become a business issue, a legal issue, a pricing issue, and eventually a market issue. When intelligence becomes a product, the history of how that intelligence was made starts to matter.
That is why I keep coming back to trust instead of tracking. Tracking is the visible feature. Trust is the actual fight. Big Tech can own the cloud, the model, the enterprise relationship, and the distribution. OpenLedger has to prove something different. It has to prove who fed the machine, who improved the machine, who used the machine, and who deserves value when the machine starts making money. If it can do that in a way people outside closed platforms actually trust, then it is not just another AI protocol trying to ride a narrative. It becomes a place where the market can check the history of intelligence itself.
And maybe that is the real moat. Not being louder than Big Tech. Not being smoother than Big Tech. Not pretending Google and Microsoft cannot copy features. The moat is giving people a reason to believe the record is fair when the value of AI starts flowing through many hands. Because if the future of AI is only a few giant companies absorbing all data, all models, all agents, and all rewards into their own private systems, then the internet becomes even more one-sided than it already is. But if OpenLedger can become a neutral place where contribution is seen, checked, and rewarded, then the question changes. It is no longer just “who built the best model?” It becomes “who actually helped create this intelligence, and who is only standing at the cash register?”
