Автор: 0xjacobzhao | https://linktr.ee/0xjacobzhao
Этот независимый отчет поддерживается IOSG Ventures, процесс исследования и написания был вдохновлен отчетом по обучению с подкреплением Сэма Леймана (Pantera Capital), благодарим Бена Филдинга (Gensyn.ai), Гао Юаня (Gradient), Самуэля Дейра и Эрфана Миахи (Covenant AI), Шашанка Ядава (Fraction AI), Чао Ванга за ценные советы, данные по этой статье. Мы стремимся к объективной и точной информации, некоторые мнения могут содержать субъективные суждения и неизбежно могут быть искажены, просим читателей отнестись с пониманием.
Искусственный интеллект переходит от статистического обучения, основанного на "подгонке моделей", к способности, сосредоточенной на "структурированном рассуждении", и важность постобучения (Post-training) быстро возрастает. Появление DeepSeek-R1 знаменует собой парадигмальный переворот в эпоху больших моделей в области обучения с подкреплением; сформировалось общее мнение в отрасли: предварительное обучение создает универсальную основу для модели, а обучение с подкреплением больше не является просто инструментом согласования ценности, а доказало свою способность систематически повышать качество цепочки рассуждений и сложные способности принятия решений, постепенно эволюционируя в технический путь для постоянного повышения уровня интеллекта.
Тем временем Web3 перестраивает производственные отношения AI через децентрализованную сеть вычислительных мощностей и систему крипто-вознаграждений, в то время как структурные требования обучения с подкреплением к выборке rollout, сигналам вознаграждения и проверяемому обучению естественным образом сочетаются с совместной работой вычислительных мощностей блокчейна, распределением вознаграждений и проверяемым выполнением. Этот отчет систематически разбирает парадигму обучения AI и принципы технологии обучения с подкреплением, доказывает структурные преимущества RL × Web3 и проводит анализ таких проектов, как Prime Intellect, Gensyn, Nous Research, Gradient, Grail и Fraction AI.
1. Три стадии обучения AI: предварительное обучение, микронастройка инструкции и согласование постобучения
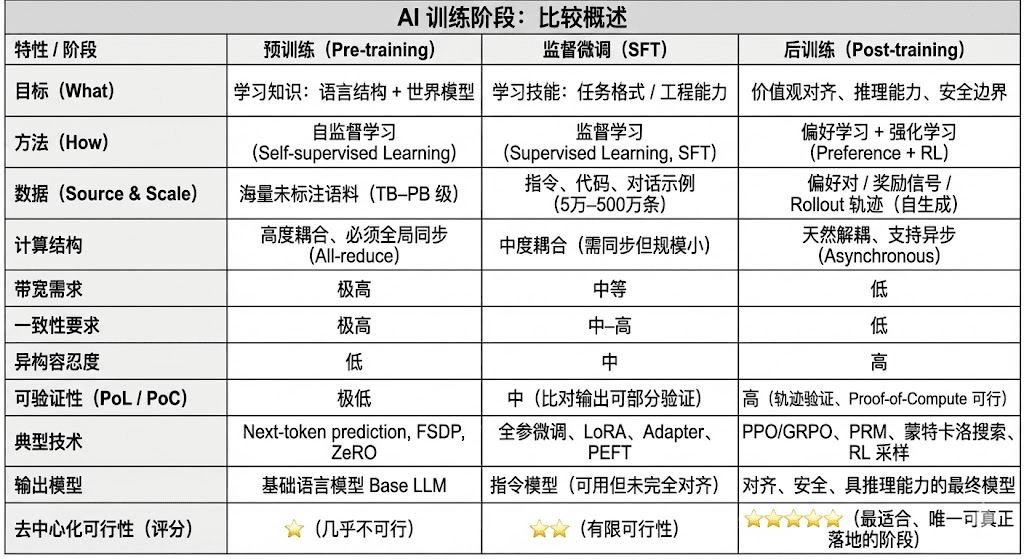
Современный жизненный цикл обучения больших языковых моделей (LLM) обычно делится на три основных этапа: предварительное обучение (Pre-training), контролируемая микронастройка (SFT) и постобучение (Post-training/RL). Каждый из них выполняет функции «создания мировой модели — внедрения способностей задачи — формирования вывода и ценностей», их вычислительная структура, требования к данным и сложность верификации определяют степень соответствия децентрализованности.
Предварительное обучение (Pre-training) строит языковую статистическую структуру модели и кросс-модальную мировую модель через крупномасштабное самообучение (Self-supervised Learning), что является основой возможностей LLM. На этом этапе необходимо обучать на триллионах образцов синхронно в глобальном масштабе, полагаясь на тысячи до десятков тысяч однотипных кластеров H100, затраты составляют до 80–95%, они крайне чувствительны к пропускной способности и авторским правам на данные, поэтому должны выполняться в высоко централизованной среде.
Микронастройка (Supervised Fine-tuning) используется для внедрения задач и форматов команд, объем данных мал, затраты составляют около 5–15%, микронастройка может проводиться как в полном объеме, так и с использованием методов эффективной микронастройки параметров (PEFT), среди которых LoRA, Q-LoRA и Adapter являются мейнстримом в индустрии. Однако все еще требуется синхронная передача градиентов, что ограничивает ее децентрализованный потенциал.
Постобучение (Post-training) состоит из нескольких итерационных подэтапов, определяющих способности модели к выводу, ценностные ориентиры и пределы безопасности, методы включают как системы обучения с подкреплением (RLHF, RLAIF, GRPO), так и методы оптимизации предпочтений без RL (DPO), а также модели вознаграждений процессов (PRM). На этом этапе объем данных и затраты невысоки (5–10%), в основном фокусируются на Rollout и обновлении стратегий; он естественно поддерживает асинхронное и распределенное выполнение, узлы не обязаны удерживать полные веса, при сочетании проверяемых вычислений с цепочкой стимулов может формироваться открытая децентрализованная сеть обучения, что является наиболее подходящим этапом для Web3.
2. Полный обзор технологий обучения с подкреплением
2.1 Архитектура системы обучения с подкреплением и ключевые элементы
Обучение с подкреплением (Reinforcement Learning, RL) управляет улучшением способности модели к принятию решений через «взаимодействие со средой — обратная связь вознаграждения — обновление стратегии», его основная структура может рассматриваться как замкнутый цикл обратной связи, состоящий из состояния, действий, вознаграждений и стратегии. Полная система RL обычно включает три типа компонентов: Policy (сеть стратегии), Rollout (образец из опыта) и Learner (обновитель стратегии). Взаимодействие стратегии с окружающей средой генерирует траектории, Learner обновляет стратегию на основе сигналов вознаграждения, создавая непрерывный процесс обучения с итерациями и оптимизацией:
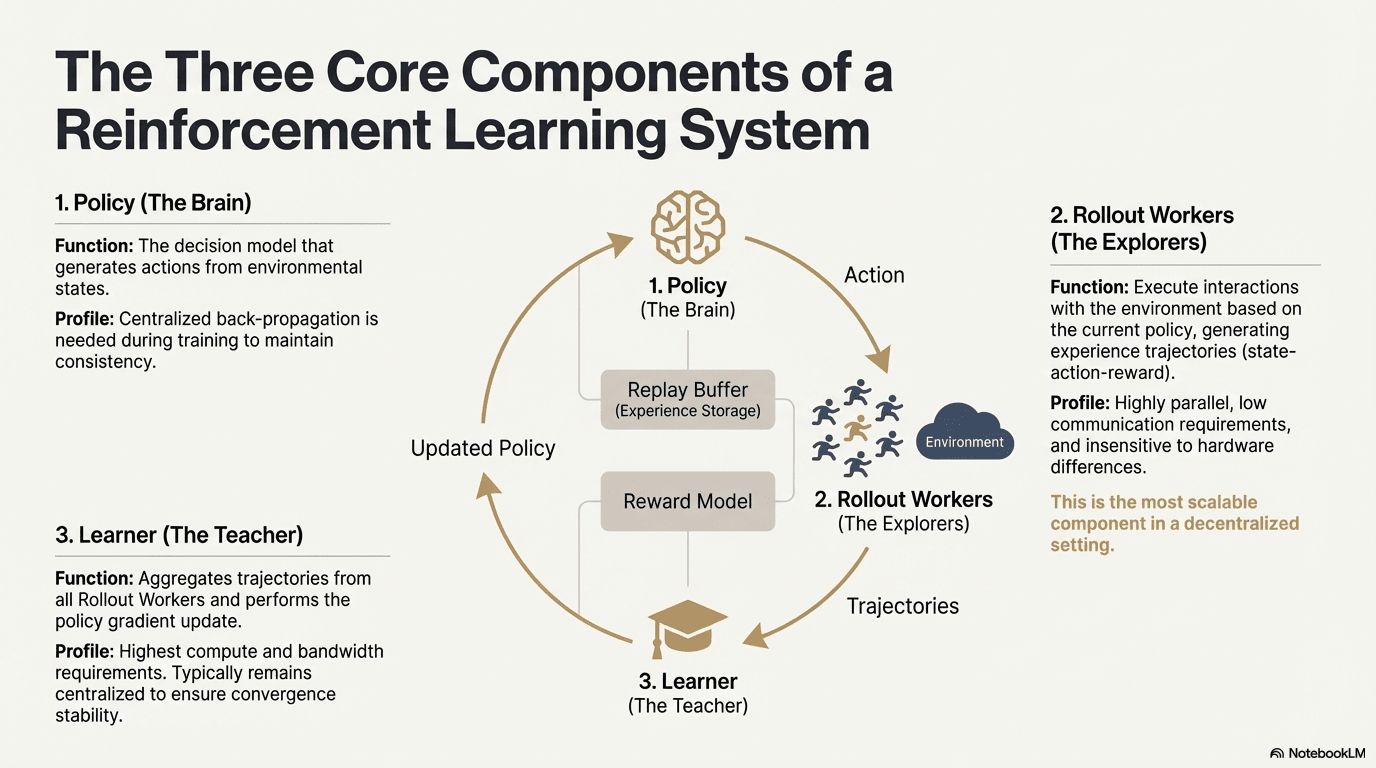
Сеть стратегии (Policy): генерирует действия из состояния среды, является ядром принятия решений системы. Во время обучения требуется централизованное обратное распространение для поддержания согласованности; во время вывода может быть распределено по различным узлам и работать параллельно.
Образец из опыта (Rollout): узлы выполняют взаимодействие со средой в соответствии со стратегией, генерируя траектории состояния-действия-вознаграждения и т. д. Этот процесс высоко параллелен, имеет очень низкую связь, и не чувствителен к различиям в оборудовании, является наиболее подходящим этапом для масштабирования в децентрализованных условиях.
Обучающий модуль (Learner): агрегирует все траектории Rollout и выполняет обновление градиента стратегии, является единственным модулем с наивысшими требованиями к вычислительной мощности и пропускной способности, поэтому обычно остается централизованным или слабо централизованным для обеспечения стабильности сходимости.
2.2 Рамка этапов обучения с подкреплением (RLHF → RLAIF → PRM → GRPO)
Обучение с подкреплением обычно делится на пять этапов, общий процесс описан ниже:
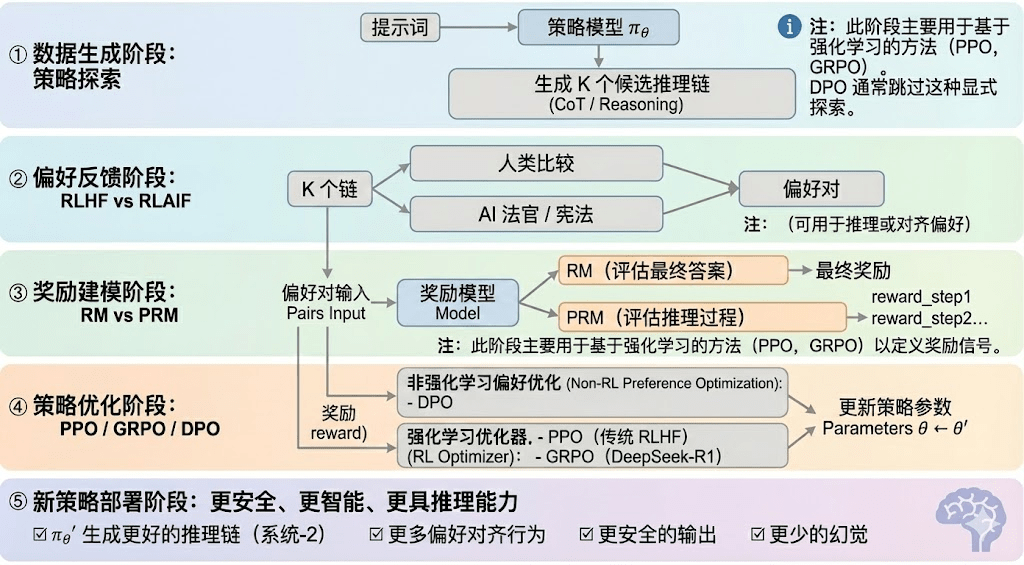
Этап генерации данных (Policy Exploration): при заданных входных подсказках модель стратегии πθ генерирует несколько候选推理链 или полные траектории, предоставляя образцы для последующей оценки предпочтений и моделирования вознаграждений, определяя широту исследования стратегии.
Этап обратной связи по предпочтениям (RLHF / RLAIF):
RLHF (обучение с подкреплением на основе человеческой обратной связи) использует множественные候选回答, аннотирование предпочтений человеком, обучение модели вознаграждений (RM) и оптимизацию стратегии с помощью PPO, чтобы сделать выводы модели более соответствующими человеческим ценностям, что является ключевым этапом перехода от GPT-3.5 к GPT-4.
RLAIF (обучение с подкреплением на основе обратной связи AI) заменяет ручную разметку на AI-судью или правила в стиле Конституции, достигая автоматизации получения предпочтений, значительно снижая затраты и обладая масштабируемыми характеристиками, став основным подходом согласования для Anthropic, OpenAI, DeepSeek и т. д.
Этап моделирования вознаграждений (Reward Modeling): предпочтения влияют на модель вознаграждений, обучая ее сопоставлять выводы с вознаграждениями. RM обучает модель «что является правильным ответом», PRM обучает модель «как правильно рассуждать».
RM (модель вознаграждений) используется для оценки качества конечного ответа, присваивая оценку только выходу:
Модель вознаграждений процесса PRM (Process Reward Model) больше не оценивает только конечный ответ, а также присваивает оценки каждому шагу вывода, каждому токену, каждому логическому сегменту, что является ключевой технологией OpenAI o1 и DeepSeek-R1, по сути это «обучение модели тому, как мыслить».
Этап верификации вознаграждений (RLVR / Reward Verifiability): в процессе генерации и использования сигналов вознаграждения вводятся «проверяемые ограничения», чтобы обеспечить получение вознаграждений от воспроизводимых правил, фактов или консенсуса, тем самым снижая риски манипуляции вознаграждениями и предвзятости, а также повышая аудируемость и масштабируемость в открытой среде.
Этап оптимизации стратегии (Policy Optimization): обновление параметров стратегии θ на основе сигналов, предоставленных моделью вознаграждений, с целью получения более сильной способности к выводу, большей безопасности и более стабильных моделей поведения стратегии πθ′. Основные методы оптимизации включают:
PPO (Proximal Policy Optimization): традиционный оптимизатор для RLHF, отличающийся стабильностью, но часто сталкивающийся с медленной сходимостью и недостаточной стабильностью в сложных задачах вывода.
GRPO (Group Relative Policy Optimization): является ключевой инновацией DeepSeek-R1, моделируя распределение преимуществ среди кандидатов для оценки ожидаемой ценности, а не просто сортируя. Этот метод сохраняет информацию о величине вознаграждения, лучше подходит для оптимизации цепочек вывода, процесс обучения более стабилен, и рассматривается как важный фреймворк для усиленного обучения, ориентированный на глубокие выводы после PPO.
DPO (Direct Preference Optimization): метод постобучения, не связанный с обучением с подкреплением: не генерирует траектории, не создает модель вознаграждений, а оптимизирует непосредственно на предпочтительных парах, низкая стоимость, стабильные результаты, поэтому широко используется для согласования открытых моделей, таких как Llama, Gemma и т. д., но не улучшает способности к выводу.
Этап развертывания новой стратегии (New Policy Deployment): оптимизированная модель проявляет себя как более мощная способность к генерации цепочек вывода (Reasoning System-2), более соответствующее человеческим или AI предпочтениям поведение, более низкий уровень ошибок и более высокая безопасность. Модель постоянно обучается предпочтениям, оптимизирует процесс и улучшает качество решений в процессе итераций, создавая замкнутый цикл.

2.3 Пять основных категорий применения обучения с подкреплением в промышленности
Обучение с подкреплением (Reinforcement Learning) эволюционировало от раннего игрового интеллекта до основного фреймворка автономного принятия решений в различных отраслях, его области применения могут быть классифицированы по уровню зрелости технологий и степени внедрения в промышленность на пять основных категорий, каждая из которых продвигает ключевые прорывы в своих направлениях.
Системы игр и стратегий (Game & Strategy): направление, где RL было впервые подтверждено, в таких средах, как AlphaGo, AlphaZero, AlphaStar, OpenAI Five, демонстрируя способности к принятию решений на уровне, сопоставимом с человеческими экспертами или даже превосходящим их, что стало основой для современных алгоритмов RL.
Роботы и воплощенный интеллект (Embodied AI): RL через непрерывное управление, моделирование динамики и взаимодействие со средой позволяет роботам обучаться манипуляции, контролю движений и выполнению кросс-модальных задач (таких как RT-2, RT-X) и быстро движется к индустриализации, что является ключевой технологической дорожной картой для внедрения роботов в реальный мир.
Цифровое рассуждение (Digital Reasoning / LLM System-2): RL + PRM продвигает большие модели от «языкового подражания» к «структурированному рассуждению», к числу достигнутых результатов относятся DeepSeek-R1, OpenAI o1/o3, Anthropic Claude и AlphaGeometry, которые в основном оптимизируют вознаграждение на уровне цепочки рассуждений, а не просто оценивают конечный ответ.
Автоматизированные научные открытия и математическая оптимизация (Scientific Discovery): RL ищет оптимальные структуры или стратегии в средах без аннотации, сложных вознаграждений и огромного пространства поиска и уже достигло таких прорывов, как AlphaTensor, AlphaDev, Fusion RL, демонстрируя способности к исследованию, превосходящие человеческую интуицию.
Экономические решения и торговые системы (Economic Decision-making & Trading): RL используется для оптимизации стратегий, высокоразмерного контроля рисков и генерации адаптивных торговых систем, в отличие от традиционных количественных моделей, он способен постоянно учиться в условиях неопределенности и является важной частью интеллектуальных финансов.
3. Естественное соответствие обучения с подкреплением и Web3
Глубокое соответствие обучения с подкреплением (RL) и Web3 основано на том, что оба по своей сути являются «системами, управляемыми стимулами». RL полагается на сигналы вознаграждения для оптимизации стратегий, блокчейн полагается на экономические стимулы для координации поведения участников, что делает их естественно согласованными на механическом уровне. Основные требования RL — масштабные гетерогенные Rollout, распределение вознаграждений и проверка подлинности — являются структурными преимуществами Web3.
Разделение вывода и обучения: процесс обучения с подкреплением может быть четко разделен на две стадии:
Rollout (образец исследования): модель генерирует большое количество данных на основе текущей стратегии, это вычислительно интенсивная, но разреженная по связи задача. Не требует частой связи между узлами, подходит для параллельной генерации на потребительских GPU, распределенных по всему миру.
Обновление (обновление параметров): обновление весов модели на основе собранных данных, требуется высокопропускная централизованная нода.
Разделение «вывода — обучения» естественным образом соответствует децентрализованной гетерогенной структуре вычислительных мощностей: Rollout может быть делегирован открытой сети, а обновление модели остается централизованным для обеспечения стабильности.
Проверяемость (Verifiability): ZK и доказательство обучения (Proof-of-Learning) предоставляют средства для проверки того, действительно ли узлы выполняют вывод, решая проблемы честности в открытых сетях. В детерминированных задачах, таких как код, математические рассуждения и т. д., проверяющим нужно просто проверить ответ, чтобы подтвердить объем работы, значительно повышая доверие к системе децентрализованного RL.
Уровень вознаграждений, основанный на экономике токенов: механизм обратной связи Web3 может напрямую вознаграждать участников, вносящих отзывы о предпочтениях RLHF/RLAIF, обеспечивая прозрачную, расчетную и не требующую разрешений структуру стимулов; ставки и снижение (Staking/Slashing) дополнительно ограничивают качество обратной связи, формируя более эффективный и согласованный рынок обратной связи по сравнению с традиционным краудсорсингом.
Потенциал многопользовательского обучения с подкреплением (MARL): блокчейн по своей сути является открытой, прозрачной и постоянно эволюционирующей многопользовательской средой, где учетные записи, контракты и агенты постоянно адаптируют стратегии в соответствии с стимулирующими факторами, что делает его естественным для создания масштабных экспериментов MARL. Хотя он все еще находится на раннем этапе, его открытость, проверяемость выполнения и программируемые стимулы предоставляют принципиальные преимущества для будущего развития MARL.
4. Анализ классических проектов Web3 + обучения с подкреплением
Основываясь на вышеуказанной теоретической базе, мы кратко проанализируем наиболее представительные проекты в текущей экосистеме:
Prime Intellect: асинхронная парадигма обучения с подкреплением prime-rl
Prime Intellect стремится создать глобальный открытый рынок вычислительных мощностей, снижая порог обучения, способствуя децентрализованному обучению в сотрудничестве и развивая полноценный стек технологий открытого суперинтеллекта. Его система включает: Prime Compute (единая облачная/распределенная вычислительная среда), модельную семью INTELLECT (10B–100B+), центр открытых сред обучения с подкреплением (Environments Hub) и движок синтетических данных большого масштаба (SYNTHETIC-1/2).
Основной компонент инфраструктуры Prime Intellect, фреймворк prime-rl, специально разработан для асинхронной распределенной среды и тесно связан с обучением с подкреплением, остальные компоненты включают протокол связи OpenDiLoCo, который преодолевает узкие места пропускной способности, механизм верификации TopLoc, который гарантирует целостность вычислений и т. д.
Обзор основных компонентов инфраструктуры Prime Intellect

Техническая основа: фреймворк асинхронного обучения с подкреплением prime-rl
prime-rl является основным движком обучения Prime Intellect, специально разработанным для масштабных асинхронных децентрализованных условий, достигая высокой пропускной способности вывода и стабильного обновления через полное разъединение Actor-Learner. Исполнители (Rollout Workers) и обучающие (Trainer) больше не блокируют синхронно, узлы могут в любое время подключаться или отключаться, просто продолжая запрашивать последнюю стратегию и загружать сгенерированные данные:
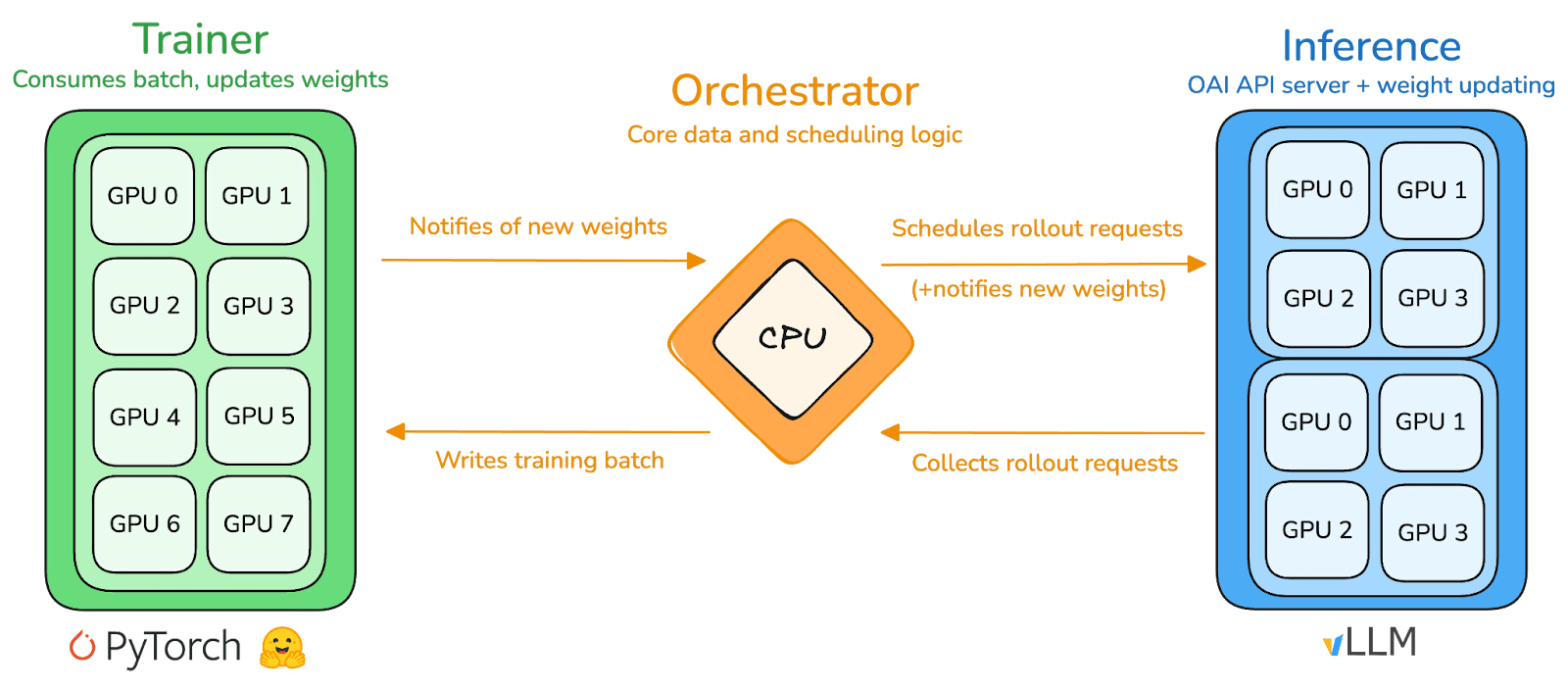
Исполнители Actor (Rollout Workers): отвечают за вывод модели и генерацию данных. Prime Intellect инновационно интегрирует движок вывода vLLM на стороне Actor. Технология PagedAttention vLLM и возможности непрерывной пакетной обработки (Continuous Batching) позволяют Actor генерировать траектории вывода с высокой пропускной способностью.
Обучающие Learner (Trainer): отвечают за оптимизацию стратегии. Learner асинхронно извлекает данные из общего буфера обратного опыта (Experience Buffer) для обновления градиентов, не дожидаясь завершения всех Actor текущей партии.
Координатор (Orchestrator): отвечает за управление потоками данных и весами модели.
Ключевые инновации prime-rl:
Полная асинхронность (True Asynchrony): prime-rl отказывается от традиционного синхронного подхода PPO, не дожидаясь медленных узлов и не требуя выравнивания по пакетам, позволяя любому количеству и производительности GPU подключаться в любое время, закладывая основы для реальной децентрализованной структуры RL.
Глубокая интеграция FSDP2 и MoE: через разбиение параметров FSDP2 и разреженные активации MoE prime-rl позволяет эффективно обучать модели с десятками миллиардов параметров в распределенной среде, активируя только активных экспертов, значительно снижая затраты на память и вывод.
GRPO+ (Group Relative Policy Optimization): GRPO исключает сеть критиков, значительно снижая вычислительные и память, естественным образом адаптируясь к асинхронной среде, GRPO+ от prime-rl дополнительно обеспечивает стабильную сходимость в условиях высокой задержки.
Семья моделей INTELLECT: символ зрелости децентрализованных технологий RL
INTELLECT-1 (10B, октябрь 2024 года) впервые доказал эффективность OpenDiLoCo в децентрализованной сети, охватывающей три континента (доля связи <2%, использование вычислительных мощностей 98%), разрушая физическое восприятие межрегионального обучения;
INTELLECT-2 (32B, апрель 2025 года) как первая модель RL без разрешений проверяет стабильность сходимости prime-rl и GRPO+ в условиях многократной задержки и асинхронной среды, реализуя децентрализованное RL с участием глобальных открытых вычислительных мощностей;
INTELLECT-3 (106B MoE, ноябрь 2025 года) использует разреженную архитектуру, активируя только 12B параметров, обучается на 512×H200 и достигает флагманских показателей вывода (AIME 90.8%, GPQA 74.4%, MMLU-Pro 81.9% и т. д.), общая производительность уже близка или даже превосходит модели централизованных закрытых систем, значительно превышающие его масштаб.
Кроме того, Prime Intellect разработал несколько вспомогательных инфраструктур: OpenDiLoCo снижает объем коммуникации на сотни раз за счет временной разреженности связи и дифференциации весов, позволяя INTELLECT-1 поддерживать 98% использования в сетях, охватывающих три континента; TopLoc + Verifiers образуют уровень доверенного выполнения с децентрализованной верификацией, активируя отпечатки пальцев и верификацию песочницы для обеспечения подлинности вывода и данных вознаграждения; движок SYNTHETIC данных производит массовые высококачественные цепочки вывода и эффективно запускает модель 671B на потребительских кластерах GPU за счет параллельной обработки. Эти компоненты предоставляют критическую инженерную основу для генерации, верификации и пропускной способности вывода данных в децентрализованном RL. Серия INTELLECT подтверждает, что этот стек технологий может производить зрелые модели мирового класса, знаменуя переход децентрализованной системы обучения от концептуальной стадии к практической.
Gensyn: основной стек обучения с подкреплением RL Swarm и SAPO
Цель Gensyn состоит в том, чтобы объединить глобально неиспользуемые вычислительные мощности в открытую, надежную, не требующую доверия и неограниченно масштабируемую инфраструктуру для обучения AI. Его ядро включает уровень стандартизированного выполнения между устройствами, сеть координации peer-to-peer и систему верификации задач, которая автоматически распределяет задачи и вознаграждения с помощью смарт-контрактов. Около особенностей обучения с подкреплением Gensyn вводит такие ключевые механизмы, как RL Swarm, SAPO и SkipPipe, которые разъединяют три этапа генерации, оценки и обновления, использует «св swarm» из глобальных гетерогенных GPU для реализации коллективной эволюции. Его конечный результат — это не просто вычислительная мощность, а проверяемый интеллект (Verifiable Intelligence).
Применение обучения с подкреплением в стек Gensyn

RL Swarm: децентрализованный движок совместного обучения с подкреплением
RL Swarm демонстрирует новую модель сотрудничества. Это уже не простая передача задач, а децентрализованный цикл «генерация-оценка-обновление», имитирующий процесс совместного обучения, бесконечно повторяющийся:
Solvers (исполнители): отвечают за локальный вывод модели и генерацию Rollout, узлы могут быть гетерогенными. Gensyn интегрирует высокопропускной движок вывода (например, CodeZero) для вывода полных траекторий, а не только ответов.
Proposers (выдающиe задания): динамично создают задачи (математические задачи, кодовые вопросы и т. д.), поддерживая разнообразие задач и адаптивность сложности в стиле Curriculum Learning.
Evaluators (оценщики): используют замороженные «модели судей» или правила для оценки локального Rollout, генерируя локальные сигналы вознаграждения. Процесс оценки может подвергаться аудиту, уменьшая пространство для злоупотреблений.
Три из них вместе составляют организационную структуру RL P2P, которая может завершить крупномасштабное совместное обучение без необходимости в централизованном управлении.
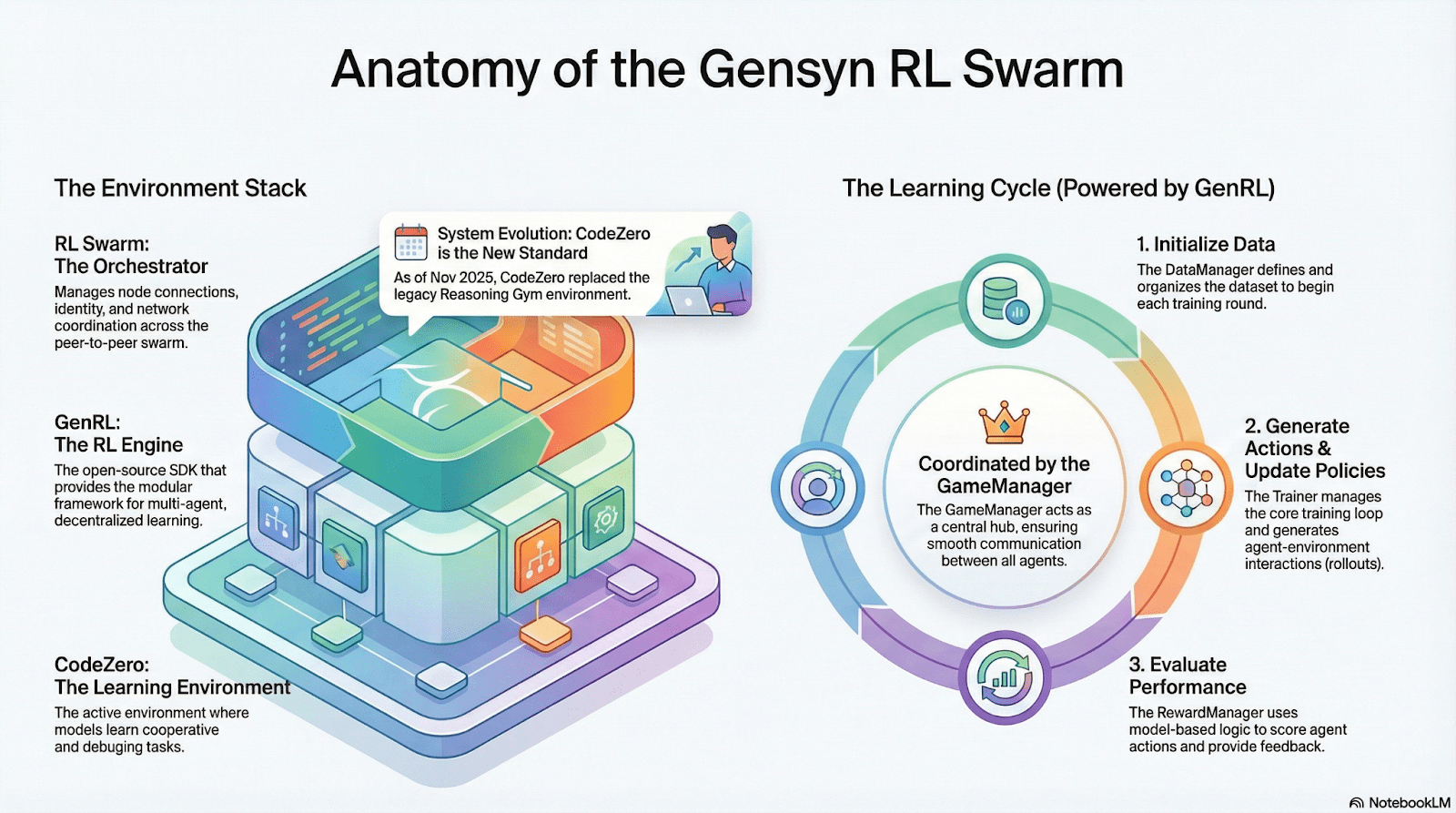
SAPO: алгоритм оптимизации стратегии, переосмысленный для децентрализованной структуры: SAPO (Swarm Sampling Policy Optimization) фокусируется на «общем Rollout и фильтрации образцов без градиентных сигналов, а не на общих градиентах» путем масштабного децентрализованного выборки Rollout и рассматривает полученные Rollout как локально сгенерированные, чтобы поддерживать стабильную сходимость в условиях значительных задержек узлов без централизованной координации. В отличие от PPO, который полагается на сеть критиков и требует высоких вычислительных затрат, или GRPO, основанного на оценке преимущества внутри группы, SAPO позволяет потребительским GPU эффективно участвовать в масштабной оптимизации обучения с подкреплением с минимальной пропускной способностью.
С помощью RL Swarm и SAPO Gensyn доказал, что обучение с подкреплением (особенно в стадии постобучения RLVR) естественным образом совместимо с децентрализованной архитектурой, поскольку оно больше зависит от крупномасштабного и разнообразного探索 (Rollout), а не от синхронизации параметров с высокой частотой. В сочетании с системами верификации PoL и Verde Gensyn предлагает альтернативный путь обучения для моделей с триллионами параметров, который больше не зависит от единого технологического гиганта: сеть суперинтеллекта, состоящая из миллионов гетерогенных GPU по всему миру.
Nous Research: проверяемая среда обучения с подкреплением Atropos
Nous Research строит децентрализованную, самовосстанавливающуюся когнитивную инфраструктуру. Его основные компоненты — Hermes, Atropos, DisTrO, Psyche и World Sim организованы в непрерывную замкнутую систему интеллектуальной эволюции. В отличие от традиционного линейного процесса «предварительное обучение — постобучение — вывод», Nous использует такие технологии, как DPO, GRPO, отбор образцов для отказа и другие методы обучения с подкреплением, объединяя генерацию данных, верификацию, обучение и вывод в непрерывный цикл обратной связи, создавая замкнутую экосистему AI, способствующую постоянному самоусовершенствованию.
Обзор компонентов Nous Research

Уровень модели: эволюция Hermes и способности вывода
Серия Hermes является основным интерфейсом модели Nous Research, ее эволюция четко демонстрирует путь перехода отрасли от традиционного согласования SFT/DPO к обучению с подкреплением вывода (Reasoning RL):
Hermes 1–3: согласование инструкций и ранние способности агентов: Hermes 1–3 завершает надежное согласование инструкций с помощью недорогого DPO и использует синтетические данные и впервые введенный механизм верификации Atropos в Hermes 3.
Hermes 4 / DeepHermes: записывая цепочку мышления в веса через System-2, повышает математические и кодовые производительности с помощью масштабирования во времени, и полагается на «отказные выборки + верификацию Atropos» для создания высокопурой данных вывода.
DeepHermes дополнительно использует GRPO вместо PPO, который трудно внедрить в распределенные системы, позволяя RL выводу работать в децентрализованной сети GPU Psyche, закладывая инженерные основы для масштабируемости открытого вывода RL.
Atropos: проверяемая система обучения с подкреплением на основе вознаграждений
Atropos является истинным узлом системы Nous RL. Он упаковывает подсказки, вызовы инструментов, выполнение кода и многократное взаимодействие в стандартизированную среду RL, что позволяет напрямую проверять, является ли вывод правильным, предоставляя определенные сигналы вознаграждения, заменяя дорогостоящую и не масштабируемую человеческую разметку. Более важно, в децентрализованной сети обучения Psyche Atropos выступает в роли «судьи», проверяя, действительно ли узлы улучшают стратегии, поддерживая проверяемое доказательство обучения, что в корне решает проблему надежности вознаграждений в распределенном RL.
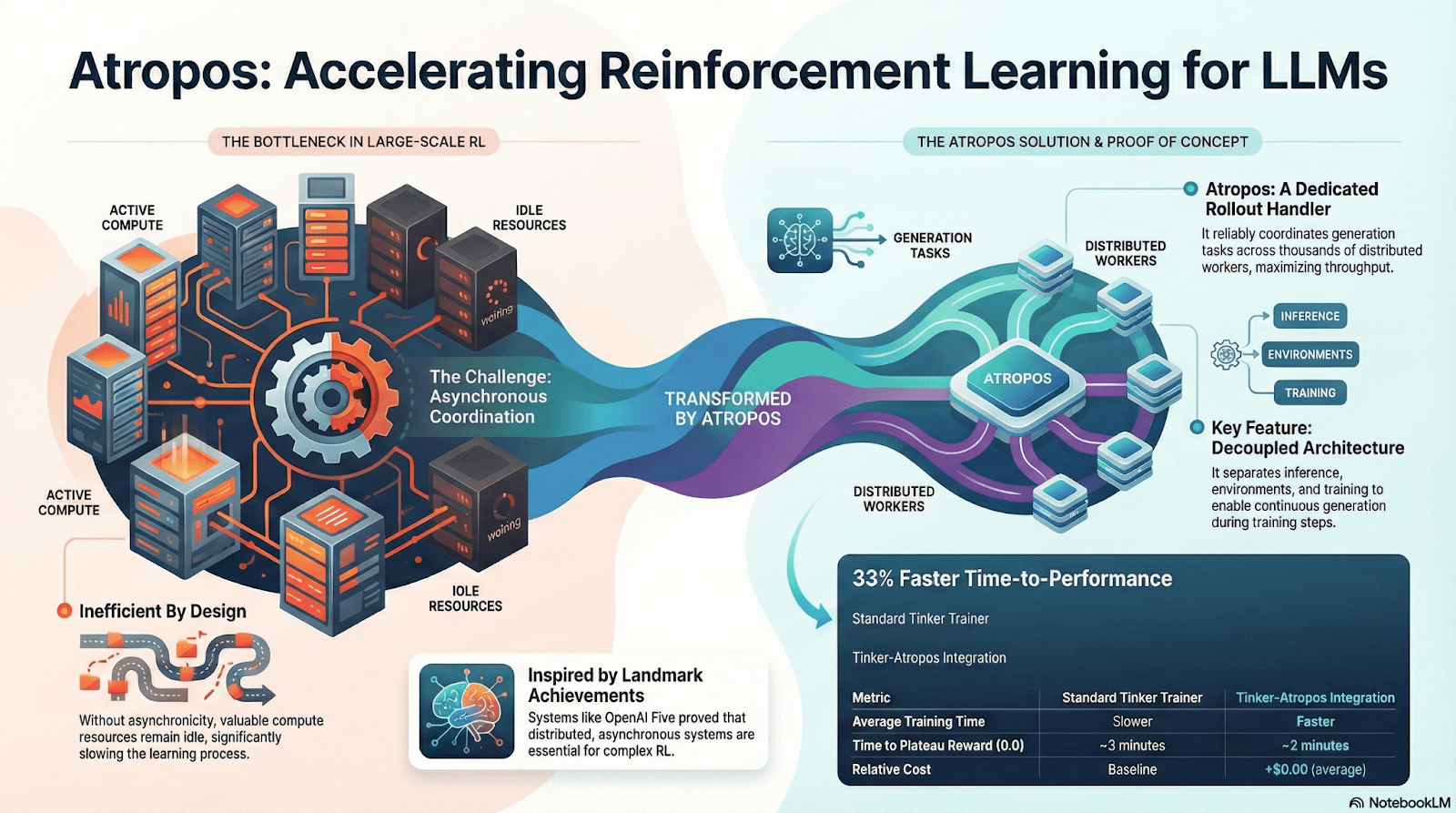
DisTrO и Psyche: уровень оптимизации для децентрализованного обучения с подкреплением
Традиционное обучение RLF (RLHF/RLAIF) зависит от централизованных кластеров с высокой пропускной способностью, что является ключевым барьером, который невозможно воспроизвести в открытых системах. DisTrO снижает затраты на связь RL на несколько порядков благодаря распараллеливанию и сжатию градиентов, позволяя обучению работать в условиях интернет-пропускной способности; Psyche разворачивает этот механизм обучения в сети блокчейна, позволяя узлам выполнять вывод, верификацию, оценку вознаграждений и обновление весов локально, образуя полный замкнутый цикл RL.
В системе Nous Atropos проверяет цепочку мышления; DisTrO сжимает коммуникацию при обучении; Psyche запускает цикл RL; World Sim предоставляет сложные среды; Forge собирает реальные выводы; Hermes записывает все обучения в веса. Обучение с подкреплением — это не просто этап обучения, а основной протокол в архитектуре Nous, связывающий данные, среды, модели и инфраструктуру, позволяя Hermes стать живой системой, способной постоянно самоусовершенствоваться в сети открытых вычислительных мощностей.
Сеть градиентов: архитектура обучения с подкреплением Echo
Основная цель сети градиентов (Gradient Network) состоит в том, чтобы реконструировать вычислительную парадигму AI с помощью «открытого интеллектуального протокольного стека» (Open Intelligence Stack). Технический стек Gradient состоит из группы ключевых протоколов, которые могут независимо развиваться и взаимодействовать. Его система включает в себя: Parallax (распределенное рассуждение), Echo (децентрализованное обучение RL), Lattica (P2P сеть), SEDM / Massgen / Symphony / CUAHarm (память, сотрудничество, безопасность), VeriLLM (достоверная верификация), Mirage (высокоточная симуляция), совместно образуя постоянно эволюционирующую децентрализованную интеллектуальную инфраструктуру.

Echo — архитектура обучения с подкреплением
Echo является фреймворком обучения с подкреплением от Gradient, его основная концепция состоит в разъединении путей обучения, вывода и данных (вознаграждений) в обучении с подкреплением, позволяя Rollout генерировать, оптимизировать стратегии и оценивать вознаграждения независимо в гетерогенных средах. Он координирует работу в сети из узлов вывода и обучения с помощью легких синхронных механизмов, поддерживая стабильность обучения в широкомасштабной гетерогенной среде, эффективно уменьшая проблемы, возникающие при смешивании вывода и обучения в традиционных DeepSpeed RLHF/VERL.
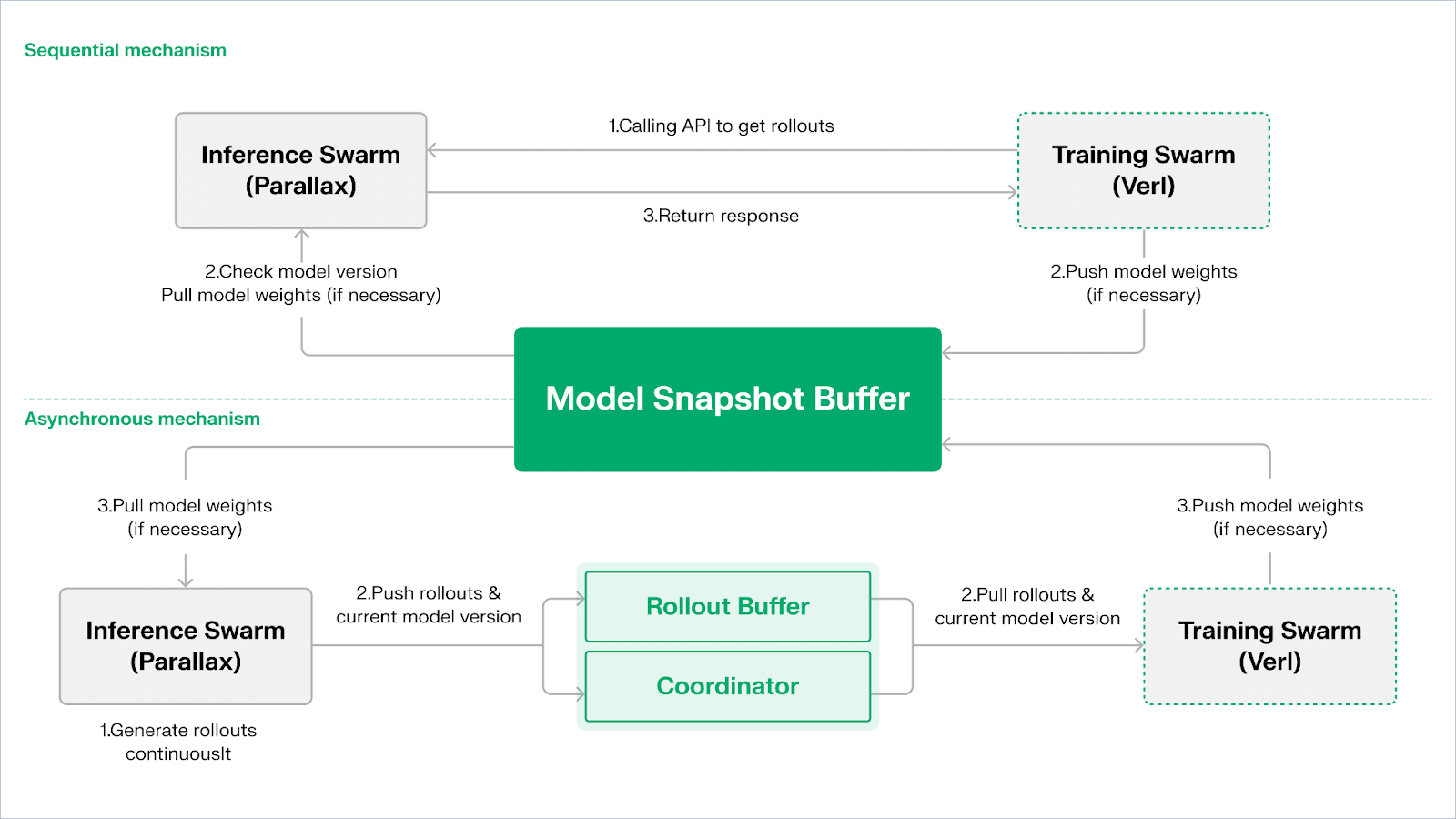
Echo использует архитектуру «двойной группы вывода — обучения», чтобы максимизировать использование вычислительных мощностей, каждая из двух групп работает независимо и не блокирует друг друга:
Максимизация пропускной способности выборок: рой вывода Inference Swarm состоит из потребительских GPU и периферийных устройств, используя Parallax для построения высокопропускного выборщика с использованием параллельной обработки, фокусируясь на генерации траекторий;
Максимизация вычислительной мощности градиента: рой обучения Training Swarm состоит из потребительских GPU, работающих на централизованных кластерах или в глобальном масштабе, отвечая за обновление градиентов, синхронизацию параметров и микронастройку LoRA, сосредоточившись на процессе обучения.
Для поддержания согласованности между стратегией и данными Echo предоставляет два типа легковесных синхронных протоколов: последовательный (Sequential) и асинхронный (Asynchronous), обеспечивая двустороннее управление согласованностью весов стратегии и траекторий:
Режим последовательного извлечения (Pull) | приоритет точности: сторона обучения принуждает узлы вывода обновлять версии моделей перед извлечением новых траекторий, чтобы гарантировать свежесть траекторий, подходящие для задач, чувствительных к устаревшим стратегиям;
Асинхронный режим推拉 (Push–Pull) | приоритет эффективности: сторона вывода продолжает генерировать траектории с метками версий, сторона обучения потребляет их в своем ритме, координатор контролирует отклонение версий и инициирует обновление весов, максимизируя использование устройств.
На нижнем уровне Echo построен на Parallax (гетерогенное вывода в условиях низкой пропускной способности) и легковесных компонентах распределенного обучения (таких как VERL), полагаясь на LoRA для снижения затрат на синхронизацию между узлами, позволяя обучению с подкреплением стабильно работать в глобальной гетерогенной сети.
Grail: обучение с подкреплением в экосистеме Bittensor
Bittensor создал огромную, разреженную, нестабильную сеть функций вознаграждений с помощью своей уникальной механики консенсуса Yuma.
Covenant AI в экосистеме Bittensor построила вертикально интегрированную цепочку от предварительного обучения до RL постобучения с помощью SN3 Templar, SN39 Basilica и SN81 Grail. В частности, SN3 Templar отвечает за предварительное обучение базовой модели, SN39 Basilica предлагает распределенный рынок вычислительных мощностей, а SN81 Grail служит «проверяемым слоем вывода» для RL постобучения, завершая замкнутую оптимизацию от базовой модели до согласованной стратегии.

Цель GRAIL состоит в том, чтобы с помощью криптографии подтвердить подлинность каждого rollout обучения с подкреплением и связать его с идентичностью модели, чтобы гарантировать безопасность выполнения RLHF в средах, не требующих доверия. Протокол устанавливает надежную цепочку с помощью трехуровневого механизма:
Генерация детерминированных вызовов: используя случайный маяк drand и хеши блоков для создания непредсказуемых, но воспроизводимых вызовов (таких как SAT, GSM8K), исключает предвычисленное мошенничество;
Путем индексного образца PRF и обязательств sketch проверяющие могут с низкими затратами проверять уровень токенов logprob и цепочку вывода, подтверждая, что rollout действительно сгенерирован заявленной моделью;
Связывание идентичности модели: связывает процесс вывода с структурной подписью отпечатка модели весов и распределением токенов, обеспечивая немедленное распознавание замены модели или воспроизведения результатов. Это создает основу подлинности для траекторий вывода (rollout) в RL.
На этой основе подсеть Grail реализовала проверяемый процесс обучения в стиле GRPO: майнеры генерируют несколько путей вывода для одной и той же задачи, проверяющие оценивают по правильности, качеству цепочки вывода и уровню удовлетворенности SAT, затем нормализованные результаты записываются в цепочку как веса TAO. Публичные эксперименты показывают, что этот фреймворк увеличил точность MATH для Qwen2.5-1.5B с 12.7% до 47.6%, доказывая, что он может предотвратить мошенничество и существенно повысить способности моделей. В стек обучения Covenant AI Grail является основой доверия и выполнения децентрализованных RLVR/RLAIF, который еще не был официально запущен в основной сети.
Fraction AI: основанный на конкуренции алгоритм обучения с подкреплением RLFC
Архитектура Fraction AI четко сосредоточена на конкурентном обучении с подкреплением (Reinforcement Learning from Competition, RLFC) и игровом разметке данных, заменяя статические вознаграждения и человеческую разметку традиционного RLHF открытой динамичной конкурентной средой. Агенты противостоят друг другу в различных пространствах, их относительное ранжирование и оценки AI-судей составляют реальное вознаграждение, превращая процесс согласования в непрерывную онлайн систему многопользовательских игр.
Основные различия между традиционным RLHF и RLFC Fraction AI:

Основная ценность RLFC заключается в том, что вознаграждение больше не исходит от одной модели, а от постоянно эволюционирующих противников и оценщиков, что предотвращает использование модели вознаграждения и с помощью разнообразия стратегий предотвращает застревание экосистемы в локальных оптимумах. Структура Spaces определяет природу игры (нулевая сумма или положительная сумма), способствуя возникновению сложного поведения в противостоянии и сотрудничестве.
В архитектуре системы Fraction AI процесс обучения разбивается на четыре ключевых компонента:
Агенты: легковесные единицы стратегии на основе открытых LLM, которые обновляются по низким затратам с помощью QLoRA, используя дифференциальные веса;
Spaces: изолированные области задач, где агенты платят за вход и получают вознаграждения в зависимости от результатов;
AI-судьи: уровень мгновенных вознаграждений, построенный на RLAIF, обеспечивающий масштабируемую, децентрализованную оценку;
Доказательство обучения: связывает обновление стратегии с конкретными результатами конкуренции, обеспечивая проверяемость и защиту от мошенничества в процессе обучения.
Суть Fraction AI заключается в создании эволюционного двигателя для совместной работы человека и машины. Пользователь выступает в роли «мета-оптимизатора» (Meta-optimizer) на уровне стратегии, направляя направление исследования через инженерные подсказки (Prompt Engineering) и конфигурации гиперпараметров; в то время как агенты автоматически генерируют огромные объемы высококачественных данных предпочтений (Preference Pairs) в ходе микроконкуренции. Эта модель позволяет разметке данных достигать коммерческого замыкания через «бездоверительное микронастройку» (Trustless Fine-tuning).
Сравнение архитектуры проектов обучения с подкреплением Web3

5. Резюме и перспективы: пути и возможности RL × Web3
Основываясь на деконструктивном анализе вышеуказанных передовых проектов, мы наблюдали: несмотря на различия в подходах команд (алгоритмы, инженерия или рынок), когда обучение с подкреплением (RL) соединяется с Web3, его базовая архитектурная логика сводится к высоко согласованной парадигме «разделение-верификация-вознаграждение». Это не только техническое совпадение, но и неизбежный результат адаптации уникальных свойств обучения с подкреплением к децентрализованным сетям.
Общие характеристики архитектуры обучения с подкреплением: решение основных физических ограничений и проблем доверия
Физическое разделение推训 (Decoupling of Rollouts & Learning) — предположительная вычислительная топология
Разреженный и параллельный вывод Rollout делегируется глобальным потребительским GPU, высокопропускные обновления параметров сосредоточены на небольшом количестве обучающих узлов, так же как от асинхронного Actor-Learner Prime Intellect до двойной архитектуры Gradient Echo.
Уровень доверия, основанный на верификации (Verification-Driven Trust) — инфраструктурный
В сетях без разрешений подлинность вычислений должна быть обеспечена через математическое и механическое проектирование, представляя такие реализации, как PoL Gensyn, TOPLOC Prime Intellect и криптографическая верификация Grail.
Токенизированный замкнутый цикл вознаграждений (Tokenized Incentive Loop) — самообслуживающийся рынок
Поставки вычислительных мощностей, генерация данных, верификация сортировки и распределение вознаграждений формируют замкнутый цикл, вовлекают участие через вознаграждения, подавляют мошенничество через Slash, позволяя сети оставаться стабильной и постоянно развиваться в открытой среде.
Дифференцированные технологические пути: различные «точки прорыва» в единой архитектуре
Несмотря на сходство архитектуры, различные проекты выбрали разные технологические защитные механизмы в зависимости от своей генетики:
Парадигма алгоритмических прорывов (Nous Research): пытается решить основное противоречие распределенного обучения на математическом уровне (узкое место пропускной способности). Его оптимизатор DisTrO направлен на сокращение объема передачи градиентов в тысячи раз, цель состоит в том, чтобы позволить домашним широкополосным подключением выполнять обучение больших моделей, что представляет собой «уменьшение размерности» физических ограничений.
Парадигма системной инженерии (Prime Intellect, Gensyn, Gradient): сосредоточена на создании следующего поколения «AI-операционных систем». ShardCast от Prime Intellect и Parallax от Gradient созданы для извлечения максимальной эффективности гетерогенных кластеров в существующих сетевых условиях с помощью предельных инженерных методов.
Парадигма рыночных игр (Bittensor, Fraction AI): сосредоточена на проектировании функций вознаграждений (Reward Function). Разработав сложные механизмы оценивания, она побуждает майнеров самостоятельно находить оптимальные стратегии, ускоряя интеллектуальное развитие.
Преимущества, вызовы и перспективы
В парадигме сочетания обучения с подкреплением и Web3 системные преимущества в первую очередь проявляются в переписывании структуры затрат и структуры управления.
Перестройка затрат: потребность в Rollout в RL постобучении (Post-training) бесконечна, Web3 может задействовать глобальные долгосрочные вычислительные мощности с минимальными затратами, что является преимуществом, недоступным централизованным облачным провайдерам.
Суверенное согласование (Sovereign Alignment): разрушение монополии крупных компаний на ценности AI (Alignment), сообщество может решать, что «является хорошим ответом», через голосование токенами, добиваясь демократизации управления AI.
Тем временем эта система также сталкивается с двумя структурными ограничениями.
Стена пропускной способности (Bandwidth Wall): несмотря на такие новшества, как DisTrO, физическая задержка по-прежнему ограничивает полное обучение супербольших моделей (70B+), в настоящее время Web3 AI больше ограничивается дообучением и выводом.
Закон Гудхарта (Reward Hacking): в высокомотивированных сетях майнеры легко могут «переобучить» правила вознаграждения (накрутка баллов), вместо того чтобы увеличивать истинный интеллект. Проектирование устойчивых к мошенничеству функций вознаграждения — это вечная игра.
Злонамеренные атаки узлов в стиле византийцев (BYZANTINE worker): воздействие на сигналы обучения через активное манипулирование и отравление разрушает сходимость модели. Суть не в постоянном проектировании функций вознаграждения, устойчивых к мошенничеству, а в создании механизмов с противодействующей устойчивостью.
Слияние обучения с подкреплением и Web3, по сути, переписывает механизмы «как интеллект производится, согласуется и распределяется его ценность». Эволюционный путь можно охарактеризовать тремя взаимодополняющими направлениями:
Децентрализованная сеть учебных процессов: от вычислительных машин до сетей стратегий, делегируя параллельные и проверяемые Rollout глобальным долгосрочным GPU, в краткосрочной перспективе сосредотачиваясь на проверяемом рынке вывода, в среднесрочной перспективе эволюционируя в подклассы RL, сгруппированные по задачам;
Капитализация предпочтений и вознаграждений: от аннотированных работников до долей данных. Реализация капитализации предпочтений и вознаграждений превращает высококачественную обратную связь и модель вознаграждений в управляемые, распределяемые активы данных, переходя от «аннотированных работников» к «долям данных»
Эволюция «малых, но прекрасных» в вертикальных областях: в вертикальных сценариях с проверяемыми результатами и количественно определяемыми доходами развиваются небольшие, но мощные специализированные агенты RL, такие как реализация стратегий DeFi, генерация кода, связывая улучшения стратегий и захват ценностей непосредственно и имея шансы превзойти общие закрытые модели.
В целом, истинная возможность RL × Web3 не в том, чтобы скопировать децентрализованную версию OpenAI, а в том, чтобы переписать «отношения производства интеллекта»: сделать выполнение обучения открытым рынком вычислительных мощностей, сделать вознаграждения и предпочтения управляемыми активами на цепочке, чтобы ценность, приносимая интеллектом, больше не сосредотачивалась на платформе, а перераспределялась между обучающими, согласующими и пользователями.
Отказ от ответственности: в процессе создания этой статьи использовались инструменты AI ChatGPT-5 и Gemini 3, автор приложил все усилия для проверки и обеспечения достоверности и точности информации, но не может избежать вероятных упущений, за что просит прощения. Следует особо отметить, что на рынке криптоактивов часто наблюдается расхождение между основами проектов и ценами на вторичном рынке. Содержимое этой статьи предназначено только для информационной интеграции и академического/исследовательского обмена, не является инвестиционной рекомендацией и не должно рассматриваться как совет по покупке или продаже каких-либо токенов.