✨今天DeepSeek V4和GPT5.5都上线了
先来看看dp更新了些什么
仔细看了他们的技术报告
发现里面藏了个狠活
V4的后训练直接把V3.2的mixed RL干掉了,换成一套叫OPD(在线策略蒸馏)的新方案。
拆开看,逻辑很清晰:先针对数学、代码、Agent、指令跟随这些方向,各训一个领域专家模型,每个专家走一遍微调+GRPO强化学习。
然后用多教师OPD把十几个专家的能力整合进一个统一模型——学生在自己生成的轨迹上,对每个教师做reverseKL散度的全词表logit蒸馏。
简单来说:以前是把所有能力搅在一起训,能力之间互相打架。
现在是先让每个方向单独练到顶,再用logits级别的对齐把它们合并到同一个参数空间。
避免了传统weight merging那种"数学变强了代码就废了"的常见问题。
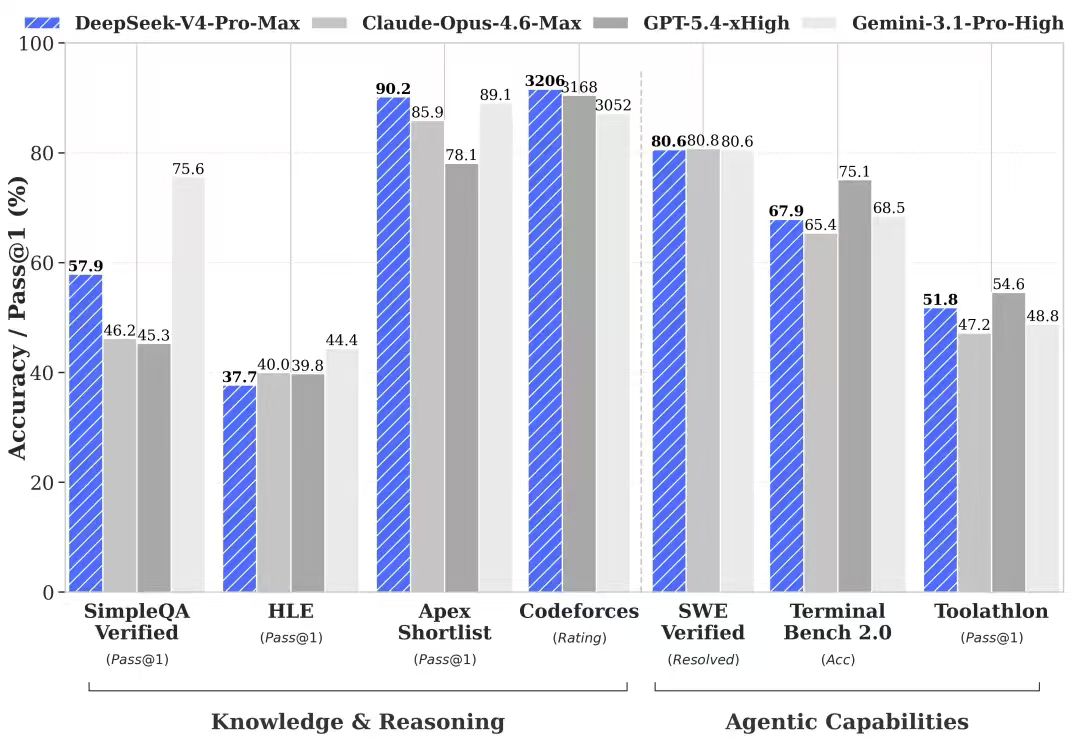
同时V4-Pro的参数量干到了1.6T,激活参数49B,上下文窗口也达到了1M token,赶上了大部队。
跑分方面,Codeforces rating 3206,比GPT-5.4的3168还高一截。LiveCodeBench 93.5,也是目前最高档。
另一个值得一提的是是GRM(生成式奖励模型)。
以前那些难以用规则验证的任务,比如开放式写作、复杂推理,传统做法是训一个标量奖励模型打分。
DeepSeek的思路是:别训单独的judge了,直接让actor网络同时干生成和评判两件事,用rubric引导的RL数据训练,少量多样化人工标注就能泛化。
这个思路确实很巧妙。
标量奖励模型最大的问题是rewardhacking——模型学会了骗奖励函数而不是真正变强。
GRM让生成和评判共享同一个网络,理论上能缓解这个问题。
对AI赛道的影响:OPD这套方法论如果被验证有效,意味着以后训大模型的范式会改变了。
从“全量混合训练”变成“先分后合”,训练效率和能力上限都能提高。
开源社区最先受益,因为你可以针对自己的场景单独训专家再蒸馏,不用从头训一个全能模型。
DeepSeek这波全开源技术路线选择,跟OpenAI和Anthropic走的闭源商业化方向明显不同。
谁对谁错,估计半年内就能见分晓了。