Một mạng lưới robot có thể xử lý các nhiệm vụ nhanh chóng và vẫn thất bại về mặt chiến lược nếu các cập nhật chính sách chậm hơn so với các sự cố thực tế.
Hầu hết các hệ thống coi quản trị là tài liệu tĩnh trong khi các hoạt động thay đổi hàng tuần. Khoảng cách đó tạo ra rủi ro âm thầm. Các chế độ thất bại mới xuất hiện, các nhà điều hành ứng biến, và các quy tắc trôi dạt khỏi thực tế cho đến khi một tranh chấp lớn buộc phải can thiệp khẩn cấp. Tốc độ không phải là nút thắt trong kịch bản đó. Sự phản ứng của quản trị là.
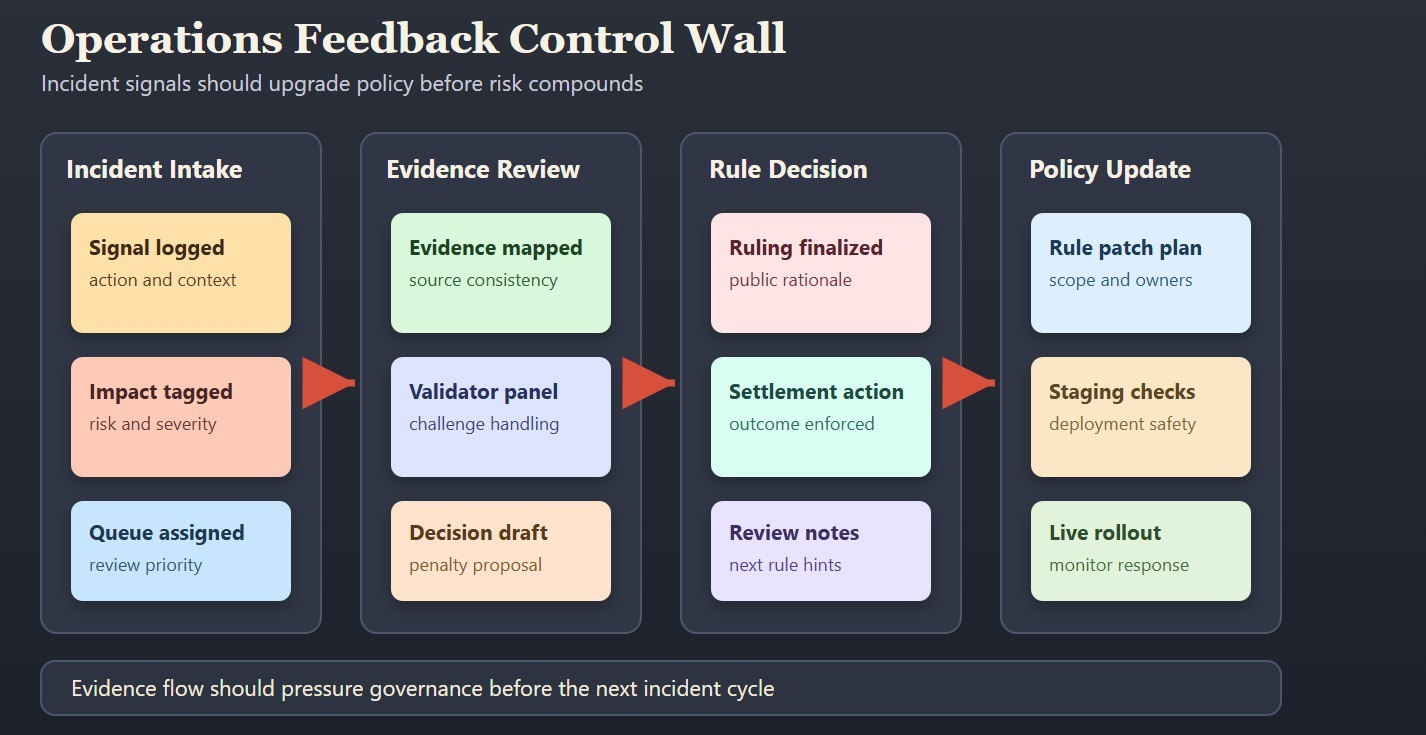
Khung của Fabric hữu ích vì nó gắn phản hồi thực thi với một mô hình phối hợp công khai thay vì một vòng kín của ủy ban. Cơ chế thử thách, kinh tế người xác thực, và các con đường quy tắc rõ ràng tạo ra một cấu trúc nơi bằng chứng từ các hoạt động có thể gây áp lực lên các thay đổi chính sách trước khi thiệt hại tích lũy. Đó là một luận điểm đáng tin cậy mạnh mẽ hơn "chúng tôi có những mô hình tốt và những ý định tốt."
Điều này cũng định hình lại cách tôi đọc `$ROBO`. Giá trị tiện ích và quản trị nên đến từ việc sử dụng bề mặt kiểm soát thực sự: tham gia giám sát, căn chỉnh các động lực, và sự liên tục của sự tiến hóa quy tắc dưới tải. Nếu những cơ chế đó hoạt động, mạng lưới có thể cải thiện thông qua áp lực. Nếu chúng không hoạt động, quản trị trở thành thương hiệu.
Đối với các đội triển khai dịch vụ robot dài hạn, câu hỏi thực tiễn không phải là liệu các sự cố có xảy ra hay không. Chúng sẽ xảy ra. Câu hỏi then chốt là liệu mỗi sự cố có khiến hệ thống dễ quản lý hơn hay dễ bị tổn thương hơn.
Khi kết quả robot cạnh tranh tiếp theo được đưa vào sản xuất, liệu lớp chính sách của bạn có thích ứng thông qua bằng chứng công khai, hay nó sẽ phụ thuộc vào các ngoại lệ riêng tư và việc khôi phục lòng tin bị trì hoãn?
@Fabric Foundation $ROBO #ROBO