I didn’t really take private AI seriously at first.
Not because the idea is wrong but because most of the time it just means hiding data better while still moving it around. Encrypt it send it, process it somewhere else, hope nothing leaks. That pattern hasn’t changed much.
And if you think about enterprise or regulated environments, that pattern is exactly where things break.
The data that actually matters financial records, customer behavior, internal risk signals is the kind of data that legally and operationally isn’t supposed to leave its boundary in the first place.
So every time AI needs that data to move, you’re already negotiating with compliance before you even get to the model.
This is where @MidnightNetwork started to feel different to me.
Not because it says we protect data but because it quietly removes the need to move it at all.
And once you see that, the whole idea of “proving an output without revealing inputs stops sounding like a feature and starts looking like the only workable setup for regulated AI.
I used to think the hard part in enterprise AI was model accuracy.
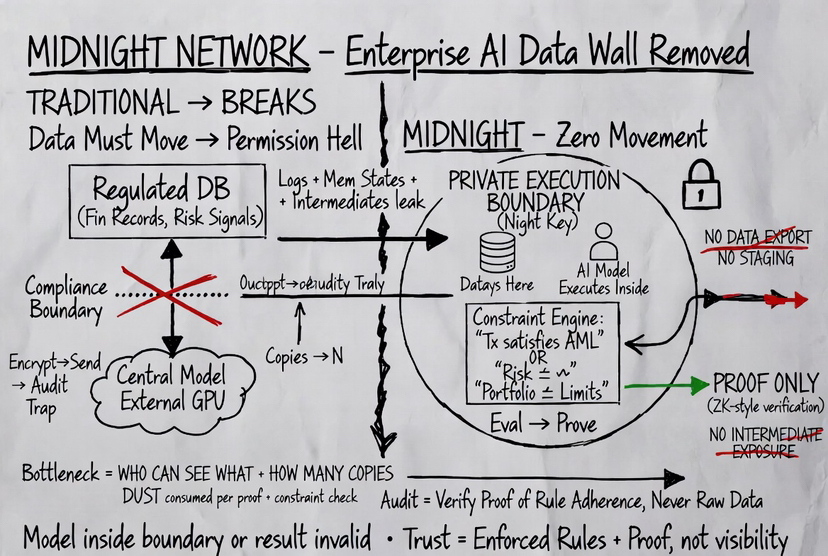
Now it feels like the real bottleneck is permission.
Who is allowed to see what where the data can exist, and how many copies of it are created during processing.
Because once data moves across systems even if encrypted it leaves traces. Logs, memory states intermediate results, access layers. Things that audits eventually care about.
Midnight cuts into that problem from a different angle.
Your data sits inside a private execution boundary defined by the Night key.
At first glance, it sounds like access control. But it’s stricter than that.
It’s not just about who can read the data.
It defines where computation over that data is allowed to happen.
If a model runs outside that boundary, the system doesn’t treat its result as valid.
That’s a strong constraint, and it changes how AI pipelines are built.
Instead of pulling data into a central model, the model runs inside the data’s boundary.
Nothing gets exported.
No dataset copies, no staging layers, no external processing environments.
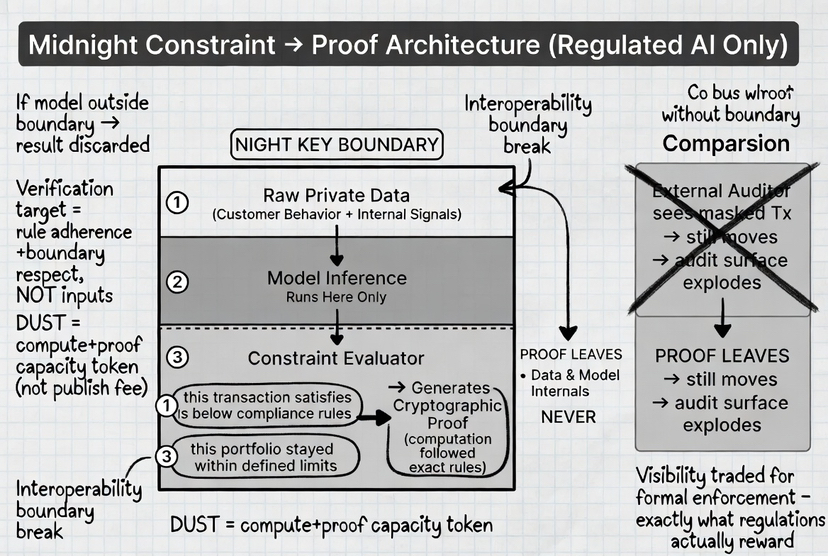
And more importantly, no intermediate exposure.
The output side is where it gets interesting.
In most systems, the output is just a result a score, a classification, a prediction.
On Midnight, the output is tied to a condition.
Not a full explanation, not raw values a specific statement that can be verified.
Something like: this transaction satisfies compliance rules this risk score is below threshold this portfolio stayed within defined limits
These aren’t loose checks.
They’re encoded as constraints strict rules that the system can evaluate.
So the flow becomes different from what we’re used to.
The model runs locally on private data.
It evaluates the defined constraint.
Then it generates a proof that this constraint holds.
That proof is what leaves the private domain.
Nothing else does.
What the network verifies is not the data and not the model internals.
It verifies that the computation followed the defined rules and produced a valid outcome.
This is where Midnight moves beyond generic ZK verification .
It’s not just proving results after computation.
It’s enforcing that valid computation can only happen inside that private boundary in the first place.
That combination matters a lot for enterprise use.
Because in regulated environments, it’s not enough for something to be correct.
It has to be provably correct without exposing restricted data.
And that’s exactly the gap most systems fail to bridge.
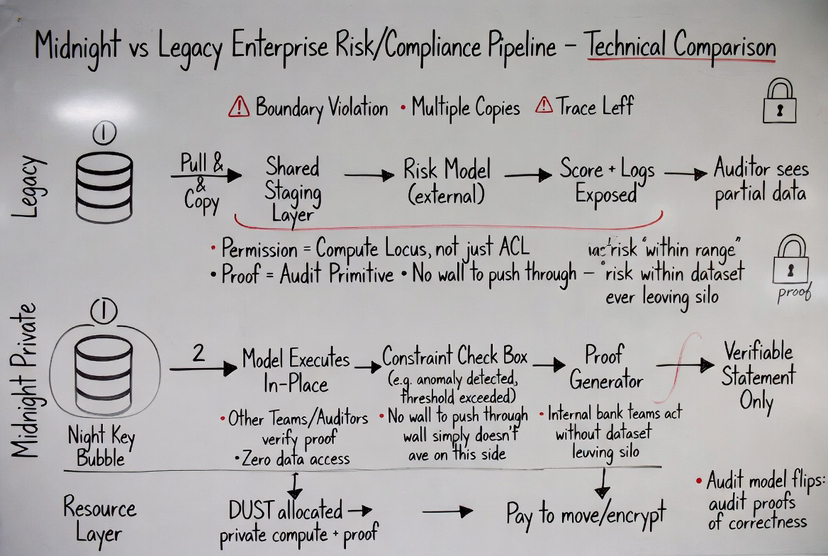
Take something like compliance checks in financial systems.
Normally, verifying compliance means exposing transaction details to auditors or external systems.
Even if partially masked, the data still moves.
With Midnight the compliance logic runs inside the private domain.
The system proves that the transaction satisfies the required rules.
An external party can verify the proof and accept the outcome.
But the transaction data itself never leaves.
This changes the audit model.
Instead of auditing raw data, you audit proofs of correctness.
That’s a very different approach, but it aligns better with how regulations actually work they care about rule adherence not unnecessary exposure.
Another case where this matters is internal enterprise AI.
Think about a bank running risk models on customer data.
Today, those models are heavily restricted because the data cannot be shared across teams or systems freely.
With Midnight, the model can run where the data already exists.
The output is turned into a verifiable statement: risk within acceptable range, anomaly detected, threshold exceeded.
Other systems can act on that result without ever accessing the underlying dataset.
So you get interoperability without breaking data boundaries.
The role of DUST becomes clearer here as well.
It’s not just a fee mechanism.
It represents the capacity required to run these private computations and generate proofs.
Every model evaluation, every constraint check, every proof it all consumes DUST.
So instead of paying to publish data, you’re allocating resources to produce verifiable outcomes.
That’s a better fit for enterprise AI, where the cost is in computation and validation, not in broadcasting information.
What stands out to me is that Midnight doesn’t try to make AI more private in a superficial way.
It restructures the pipeline so that exposure is never required.
And that’s what makes it relevant for regulated environments.
Because those environments don’t just need privacy.
They need control over where data exists how it’s processed, and what can be revealed.
I’ll be honest the trade off here is that you lose visibility.
You don’t see the raw data, you don’t inspect every step.
You rely on proofs.
At first that feels like giving something up.
But when you think about enterprise systems, that visibility was never fully available anyway it was restricted, siloed, controlled.
Midnight just formalizes that constraint and builds around it.
If anything, this changes what trust looks like.
Not trust in the data.
Not trust in the model.
Trust in the fact that the system enforces rules and proves that they were followed.
And for regulated AI that’s probably the only version that scales.
Because the more sensitive the data becomes, the less it can move.
And systems that still depend on moving it are always going to hit the same wall.
Midnight doesn’t try to push through that wall.
It just builds on the side where the wall doesn’t exist anymore.