
Cuối tháng 3 năm 2026, công cụ lập trình hàng đầu của Anthropic, Claude Code, đã xảy ra một sự kiện công nghệ có thể là nổi bật nhất năm 2026 - một cập nhật bất ngờ của gói npm đã trực tiếp phơi bày hơn 512.000 dòng mã nguồn và 4756 tệp trên mạng công khai.
Cộng đồng nhà phát triển AI toàn bộ Silicon Valley đang sôi sục.
Nhà nghiên cứu an toàn khai thác lỗ hổng, quản lý sản phẩm nghiên cứu chi tiết chức năng, doanh nhân tìm kiếm cơ hội khởi nghiệp, nhưng điều khiến ngành công nghiệp chấn động nhất là vụ rò rỉ này đã mở ra một bí mật mà trước đây chưa bao giờ được trình bày một cách hoàn chỉnh như vậy:
Anthropic đã tiêu tốn bao nhiêu công sức kỹ thuật để xây dựng một hệ thống trí nhớ cực kỳ tinh vi.
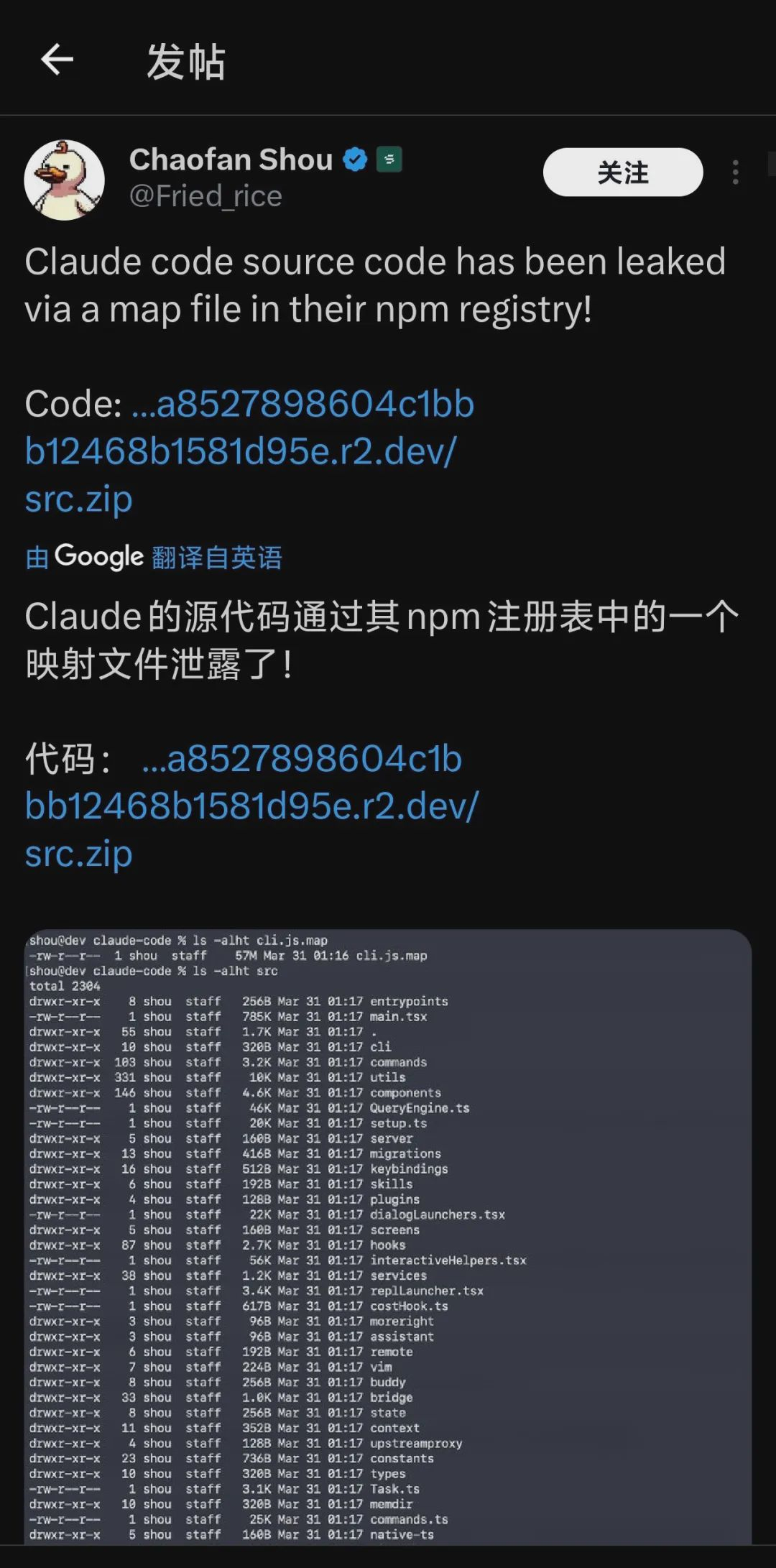
1. Sự cố rò rỉ Claude Code: một cơ hội hiếm có để "nhìn thấu"
Mã nguồn của Claude Code đã tiết lộ độ sâu kỹ thuật của các công ty AI hàng đầu trong hệ thống trí nhớ.
Đây không phải là đơn giản chỉ là "lưu trữ cuộc trò chuyện", Anthropic đã xây dựng một kiến trúc quản lý ngữ cảnh đa lớp, có khả năng tự phục hồi: cấu trúc trí nhớ ba lớp + cơ chế tự phục hồi.
Claude Code đã phân loại trí nhớ thành bốn loại (sở thích của người dùng, phản hồi, ngữ cảnh dự án, tài liệu tham khảo), mỗi loại có con đường lưu trữ và truy xuất độc lập, trí nhớ được lưu trữ dưới định dạng Markdown, quản lý siêu dữ liệu thông qua frontmatter, sau đó thông qua tệp chỉ mục MEMORY.md làm "bộ chọn tính liên quan" - mỗi lần chỉ gọi lại những đoạn trí nhớ liên quan nhất, không phải tải toàn bộ.
Điều quan trọng hơn là cơ chế tự phục hồi bộ nhớ: khi hệ thống phát hiện độ hỗn loạn ngữ cảnh quá cao, sẽ tự động kích hoạt quy trình phục hồi - dọn dẹp các con trỏ cũ, cập nhật chỉ mục, sắp xếp trí nhớ mảnh, còn có hệ thống KAIROS - Agent chạy nền liên tục, khi bạn đang ngủ, AI ở nền tảng sẽ tích hợp trí nhớ của bạn.
Claude Code có một công cụ tìm kiếm được tích hợp năm cơ chế nén: nén tự động → vi nén → nén đoạn → gập ngữ cảnh, khi token gần hết nhưng nhiệm vụ vẫn chưa hoàn thành, hệ thống tiêm một chỉ lệnh siêu dữ liệu vô hình: "tiếp tục ngay, không cần xin lỗi" - trải nghiệm người dùng là liền mạch, nền tảng là một bộ máy trạng thái phức tạp hỗ trợ.

2. Tại sao tất cả các mô hình lớn đều đang dồn sức vào hệ thống trí nhớ?
Sau khi rò rỉ Claude Code, toàn ngành đã đột nhiên có một sự đồng thuận: sự khác biệt của mô hình đang được hệ thống trí nhớ lấp đầy.
Chênh lệch giữa GPT-4 và GPT-3.5 có lớn không? Rất lớn, nhưng nếu thêm hệ thống trí nhớ hoàn hảo cho GPT-3.5, cho phép nó ghi nhớ tất cả các tình huống làm việc, sở thích, kiến thức ngành của người dùng - trong nhiều nhiệm vụ, nó không nhất thiết phải thua GPT-4.
Nói cách khác: khi bạn giải quyết vấn đề "AI không thể nhớ", sự khác biệt của mô hình thực sự không còn nghiêm trọng như vậy.
Ba cấp độ của ứng dụng AI:
Cấp độ đầu tiên: khả năng đối thoại - bạn hỏi, nó trả lời, ChatGPT đã làm khá tốt.
Cấp độ thứ hai: thực hiện nhiệm vụ - AI giúp bạn viết mã, gửi email, quản lý lịch trình, Claude Code, Cursor là những người chơi ở cấp độ này.
Cấp độ thứ ba: nhận thức liên tục - AI duy trì trí nhớ trong các nhiệm vụ dài hạn, tích lũy kinh nghiệm, gợi ý chủ động, đây là rào cản cốt lõi của thời đại Agent, hệ thống trí nhớ là cơ sở hạ tầng.
AI không có trí nhớ, mỗi cuộc đối thoại đều bắt đầu từ con số không, AI có trí nhớ, là "hình ảnh kỹ thuật số" thực sự của bạn - nó hiểu ngành của bạn, hiểu phong cách của bạn, hiểu khách hàng của bạn, nhanh hơn bất kỳ đồng nghiệp mới nào.
Sự rò rỉ của Claude Code đã xác nhận điều này: Anthropic đã đủ mạnh về khả năng của mô hình, nhưng họ vẫn đầu tư rất nhiều tài nguyên kỹ thuật vào hệ thống trí nhớ, điều này không phải ngẫu nhiên, mà là một lựa chọn chiến lược.

3. Hệ thống trí nhớ thực sự khó ở điểm nào?
Thách thức một: Lưu gì? - Không phải tất cả thông tin đều đáng nhớ, "bộ chọn tính liên quan" của Claude Code giải quyết chính vấn đề này - cần gọi lại, không phải tải toàn bộ.
Thách thức hai: Làm thế nào để nhớ? - Cần cơ sở dữ liệu vector, hiểu ngữ nghĩa, lưu trữ phân lớp, trí nhớ cần được cấu trúc để có thể truy xuất nhanh.
Thách thức ba: Ai sở hữu? - Đây là điều quan trọng nhất, trí nhớ AI của bạn thuộc về ai? Hôm nay, hầu hết trí nhớ của các sản phẩm AI đều được lưu trữ trên máy chủ nền tảng - bạn không sở hữu nó, không thể mang đi, giống như lịch sử trò chuyện WeChat của bạn, lý thuyết thuộc về Tencent.
Ai có thể giải quyết vấn đề "quyền sở hữu trí nhớ" thì người đó có thể xây dựng một hệ sinh thái AI thực sự thuộc về người dùng, đó chính là điều mà Kinic muốn làm.

4. Kinic: giải pháp "quyền sở hữu trí nhớ" hoàn chỉnh nhất hiện nay
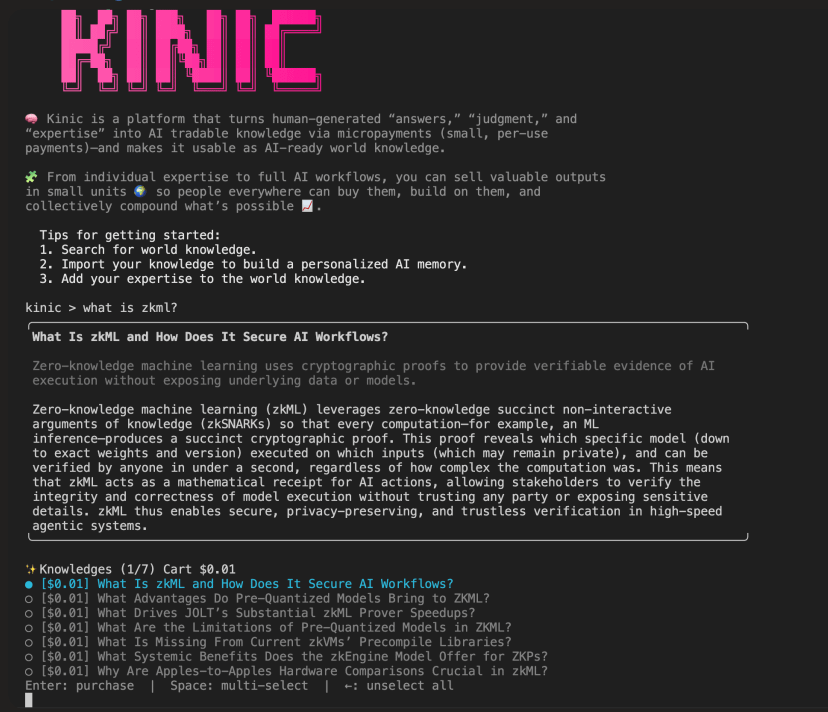
Kinic (kinic.io) được ICME Labs phát triển, dựa trên giao thức blockchain Internet Computer (ICP), cố gắng giải quyết ba vấn đề cơ bản của trí nhớ AI.
Mô tả trong một câu: biến kiến thức chuyên môn của mỗi người thành "tài sản trí nhớ" mà AI có thể thuê có trả phí.
Một tình huống cụ thể: bạn là một nhà thiết kế nội thất có 15 năm kinh nghiệm, bạn biết quy luật giá nhà ở mỗi khu vực tại Bắc Kinh, bạn biết phong cách nào là thực dụng nhất trong từng loại căn hộ, bạn đã trải qua vô số cạm bẫy và tích lũy rất nhiều trường hợp thực tế.
Hôm nay, nếu ai đó muốn có được những kinh nghiệm này, họ sẽ phải trả 500 tệ/giờ để bạn tư vấn, hoặc mua một cuốn sách có thể đã lỗi thời, nhưng nếu biến những kinh nghiệm này thành "trí nhớ chuyên nghiệp có thể được AI truy vấn" thì sao?
Người khác hỏi AI: "Tôi đã mua một căn hộ cũ 80 mét vuông ở Bắc Kinh, ngân sách hạn chế, làm thế nào để trang trí một cách thực dụng nhất?"
AI đã gọi đến trí nhớ của bạn, đưa ra câu trả lời thực sự chuyên nghiệp, bạn nhận được thu nhập thụ động - không phải bạn đi nhận đơn, mà là kiến thức của bạn kiếm tiền cho bạn 24 giờ.
Đây chính là "thị trường ngữ cảnh" mà Kinic nói đến: biến kiến thức chuyên môn thành tài sản ngữ cảnh có thể cho AI thuê.

5. Hào thành công nghệ của Kinic: tại sao nói nó rất sâu?
Hào thành thứ nhất: zkTAM - trí nhớ Agent đáng tin cậy không cần kiến thức
Đây là sự đổi mới công nghệ cốt lõi nhất của Kinic.
Hôm nay, trí nhớ AI tồn tại trong cơ sở dữ liệu vector - nhưng trí nhớ này có thể bị sửa đổi không? Trí nhớ mà AI nhận được, có thực sự là những gì nó nên nhận không?
Ví dụ: bạn ủy thác một AI giúp bạn đưa ra quyết định đầu tư, nó đã truy vấn từ kho trí nhớ "khuyến nghị của nhà phân tích về một cổ phiếu nhất định", bạn làm sao để biết rằng khuyến nghị này là chính xác, chứ không phải bị người khác cố ý tiêm vào?
zkTAM (Zero-Knowledge Trustless Agentic Memory) sử dụng bằng chứng không kiến thức (zkML) để giải quyết vấn đề này: các vector nhúng của trí nhớ có thể được chứng minh là chính xác và không bị sửa đổi - không cần tin tưởng bất kỳ máy chủ tập trung nào, không cần tin tưởng vào cơ sở dữ liệu vector, không cần tin tưởng vào mô hình nhúng.
Khung JOLT Atlas của ICME Labs thậm chí đã tối ưu hóa hiệu suất lên đến 3-7 lần - đây là rào cản cứng kết hợp giữa mật mã và khả năng kỹ thuật, đây cũng là "nhãn chống giả" của hệ thống trí nhớ, và cũng là hào thành khó bị sao chép nhất của Kinic.
Hào thành thứ hai: lưu trữ phi tập trung - bạn thực sự sở hữu trí nhớ của mình
Trí nhớ của Kinic không tồn tại trên AWS hay Alibaba Cloud, nó tồn tại trên chuỗi Internet Computer (ICP), hoạt động dưới dạng WASM Canister.
Bạn sở hữu trí nhớ của bạn, có chìa khóa, có quyền kiểm soát hoàn toàn
Trí nhớ không thể bị bất kỳ nền tảng nào xóa hoặc đóng băng
Có thể di chuyển giữa các dịch vụ AI khác nhau - chuyển nền tảng mà không mất trí nhớ
Giống như ví blockchain của bạn - thực sự thuộc về bạn, chứ không phải thuộc về một công ty nào đó, trong khi trí nhớ của ChatGPT, Claude, Kimi được lưu trữ trên máy chủ nền tảng, bạn không thể di chuyển, không thể sao lưu, không thể thực sự sở hữu.
Hào thành thứ ba: Vectune - cơ sở dữ liệu vector tối ưu hóa cho trí nhớ AI
Đội ngũ Kinic đã tự phát triển cơ sở dữ liệu vector Vectune chạy trên chuỗi, sử dụng công nghệ mã hóa VetKey để mã hóa nội dung trí nhớ, đồng thời giữ khả năng truy vấn, các dịch vụ truyền thống như Pinecone, Weaviate là dịch vụ tập trung - trí nhớ của bạn nằm trên máy chủ của người khác, Vectune đã phi tập trung hóa điều này, đồng thời giải quyết được vấn đề mã hóa và truy vấn.
Hào thành thứ tư: ERC-8004 + x402 - cho phép các AI agent giao dịch tự động với nhau
Đây là vòng khép kín kinh doanh của Kinic, cũng là cơ sở hạ tầng của toàn bộ kinh tế trí nhớ.
ERC-8004 là tiêu chuẩn "Agent đáng tin cậy" của Ethereum - định nghĩa cách mà các AI agent đăng ký danh tính, tích lũy danh tiếng, được xác thực, được phát hiện, điều này giải quyết vấn đề "ai sẽ giao dịch".
Giao thức x402 (do Coinbase phát triển) cho phép các AI agent thực hiện thanh toán vi mô tự động giữa nhau - truy vấn một lần trí nhớ chuyên nghiệp, trả 0.1 đô la, hệ thống tự động thanh toán, không cần can thiệp của con người, điều này giải quyết vấn đề "làm thế nào để giao dịch".
Kết hợp cả hai: một "nền kinh tế trí nhớ" hoàn chỉnh có thể tự vận hành - người tạo ra kiến thức tải lên trí nhớ → AI agent phát hiện và trả phí để truy vấn → cả hai bên không cần tin tưởng nhau, hệ thống đảm bảo công bằng bằng toán học, đây không phải là tưởng tượng, mà là một giao thức thanh toán đã được thực hiện.

6. Tại sao nói nó đại diện cho hướng đi tương lai?
Sự rò rỉ của Claude Code đã tiết lộ một tín hiệu đã được xác nhận: ngay cả những người chơi hàng đầu như Anthropic cũng đã đầu tư rất nhiều tài nguyên kỹ thuật vào hệ thống trí nhớ.
Cạnh tranh trong thời đại Agent sẽ là cạnh tranh về "trí nhớ chuyên nghiệp", hãy tưởng tượng:
Một AI bác sĩ, có 20 năm kinh nghiệm lâm sàng trong trí nhớ
Một AI luật sư, có 500 trường hợp thực tế trong trí nhớ
Một AI điều hành, có 1000 lần lập kế hoạch sự kiện trong trí nhớ
Những trí nhớ này mới là tài sản thực sự có giá trị - không phải bản thân mô hình, mà là kiến thức chuyên môn được chứa trong mô hình.
Claude Code đã chứng minh điều này, sức mạnh của nó không chỉ đến từ sự thông minh của mô hình Claude, mà còn vì nó có khả năng xây dựng, duy trì và sử dụng trí nhớ lâu dài.
Phán đoán của Kinic là đúng: cuộc cạnh tranh AI trong thập kỷ tới không nằm ở tầng mô hình, mà ở tầng trí nhớ.

7. Nói một cách khách quan, Kinic cũng có những hạn chế
Thành thật mà nói, Kinic hiện vẫn ở giai đoạn đầu (Open Beta v0.1), những hạn chế của nó là có thật:
Cần 1 KINIC token để triển khai trí nhớ (rào cản khá cao)
Cần dfx CLI + chuỗi công cụ Rust (không thân thiện với người dùng thông thường)
Toàn bộ hệ thống phụ thuộc vào hệ sinh thái blockchain ICP (hệ sinh thái còn nhỏ, cơ sở người dùng hạn chế)
Mô hình kinh doanh vẫn cần được xác thực trong thị trường thực
Nhưng những hạn chế này, đối với một dự án vẫn đang ở giai đoạn beta, là có thể hiểu được - họ đang ưu tiên xây dựng hào thành công nghệ, chứ không phải theo đuổi trải nghiệm người dùng.
Đối với thị trường Trung Quốc, tư duy của Kinic có giá trị tham khảo hơn so với sản phẩm cụ thể của nó, nó đã chứng minh ba điểm:
Hệ thống trí nhớ là cơ sở hạ tầng đáng để đầu tư lại
Quyền sở hữu trí nhớ là một nỗi đau thực sự của người dùng
Kinh tế trí nhớ về mặt công nghệ là khả thi

Kết luận
Sự rò rỉ của Claude Code đã cho toàn ngành thấy một sự thật: cuộc cạnh tranh AI đã chuyển từ "ai thông minh hơn" sang "ai nhớ nhiều hơn".
Hệ thống trí nhớ không phải là một chức năng, nó là một đường đua ở cấp độ cơ sở hạ tầng.
51 triệu dòng mã mà Anthropic đã đầu tư vào Claude Code là tuyên bố trung thực nhất của ngành này.
Kinic là một trong những người khám phá xa nhất hiện nay - nó đã sử dụng bằng chứng không kiến thức để giải quyết "tính đáng tin cậy của trí nhớ", sử dụng lưu trữ phi tập trung để giải quyết "quyền sở hữu trí nhớ", sử dụng thanh toán tự động để giải quyết "vấn đề giao dịch trí nhớ".
Giải pháp cho ba vấn đề này chưa chắc là câu trả lời duy nhất, nhưng ít nhất nó chứng minh rằng con đường này là khả thi.
Trong mười năm tới, ai nắm giữ trí nhớ, người đó sẽ nắm giữ cánh cửa vào thời đại Agent.
#Anthropic #claudecode #KINIC #AI
Nội dung IC mà bạn quan tâm
Tiến bộ công nghệ | Thông tin dự án | Sự kiện toàn cầu

Lưu lại để theo dõi kênh IC Binance
Nắm bắt thông tin mới nhất