
Câu này nghe đơn giản đến mức hầu hết người đọc qua mà không dừng lại: "give the right reward to the right user."
Mình dừng lại khá lâu.
Không phải vì câu đó sai. Mà vì mình đã từng làm việc đủ gần với các hệ thống targeting để biết rằng câu đó che giấu một bài toán mà cả ngành data science đã vật lộn trong nhiều năm mà vẫn chưa giải xong hoàn toàn.
Vấn đề không phải là phát rewards. Phát rewards thì dễ. Vấn đề là biết trước ai sẽ thay đổi hành vi vì rewards đó trước khi bạn phát nó.
Trong machine learning, đây gọi là uplift modeling. Bạn không muốn target người chắc chắn sẽ ở lại vì họ ở lại dù bạn có làm gì. Bạn không muốn target người chắc chắn sẽ rời đi vì rewards không giữ được họ. Bạn muốn target người đang ở ngưỡng giữa, người mà một reward đúng lúc sẽ tip họ về phía ở lại.
Nhóm người đó gọi là marginal users.
Vấn đề là bạn không biết ai là marginal user trước khi chạy campaign. Bạn chỉ biết sau khi nhìn vào data của control group, những người không nhận rewards, và xem ai trong số đó đã churn. Người churn từ control group là người mà rewards có thể đã giữ lại được. Đó là marginal user.
Nhưng lúc bạn có thông tin đó thì campaign đã chạy xong rồi.
Đây là vòng lặp mà mọi hệ thống reward targeting phải sống trong đó. Bạn đưa ra quyết định dựa trên probability estimate, chạy campaign, nhìn vào kết quả, cập nhật model, chạy campaign tiếp theo với model tốt hơn một chút. Mỗi vòng lặp làm model chính xác hơn. Nhưng vòng đầu tiên luôn là vòng tệ nhất.
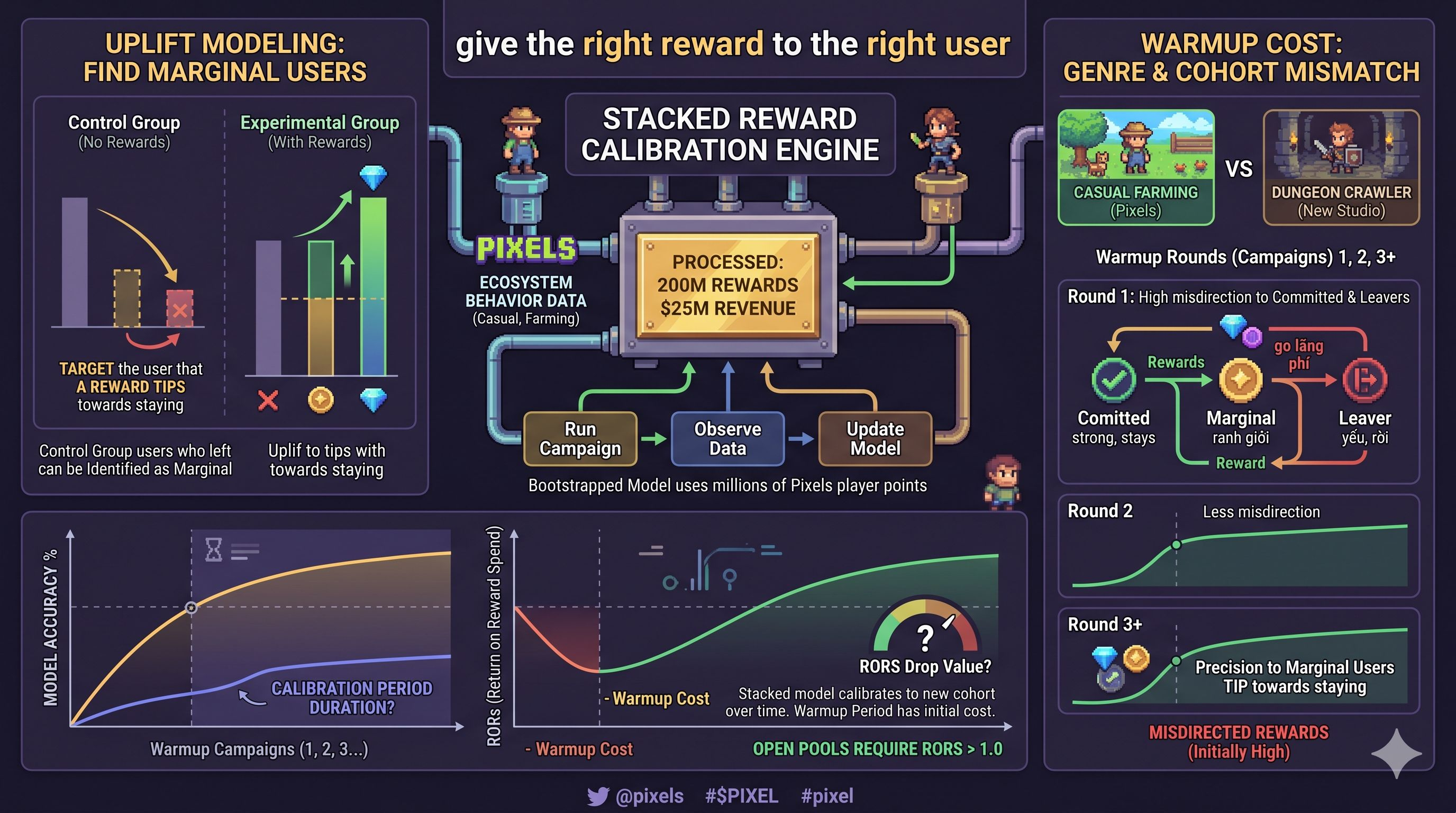
Stacked giải quyết bài toán này bằng cách dùng behavioral data từ toàn bộ Pixels ecosystem để bootstrap model cho studio mới tích hợp. Thay vì bắt đầu từ zero, studio mới nhận được một model đã được train trên hàng triệu người chơi thật với hàng trăm triệu data points về churn pattern, spending behavior, session depth.
Đó là lợi thế thật và đáng kể.
Nhưng có một chi tiết mà Stacked chưa nói thẳng trong bất kỳ tài liệu công khai nào.
Behavioral data từ Pixels ecosystem là data của người chơi Pixels. Khi một studio mới tích hợp, người chơi của họ là một cohort khác, từ một genre khác, với một demographic khác, có thể với một churn dynamic hoàn toàn khác. Model được train trên casual farming game không nhất thiết predict chính xác churn trong một dungeon crawler hay một strategy game.
Vòng đầu tiên của mọi studio mới là vòng model đang học để calibrate lại cho đúng cohort. Trong giai đoạn đó, rewards có thể đi sai chỗ nhiều hơn bình thường. Committed player nhận rewards không cần thiết. Budget bị lãng phí vào người đã quyết định rời đi từ trước.
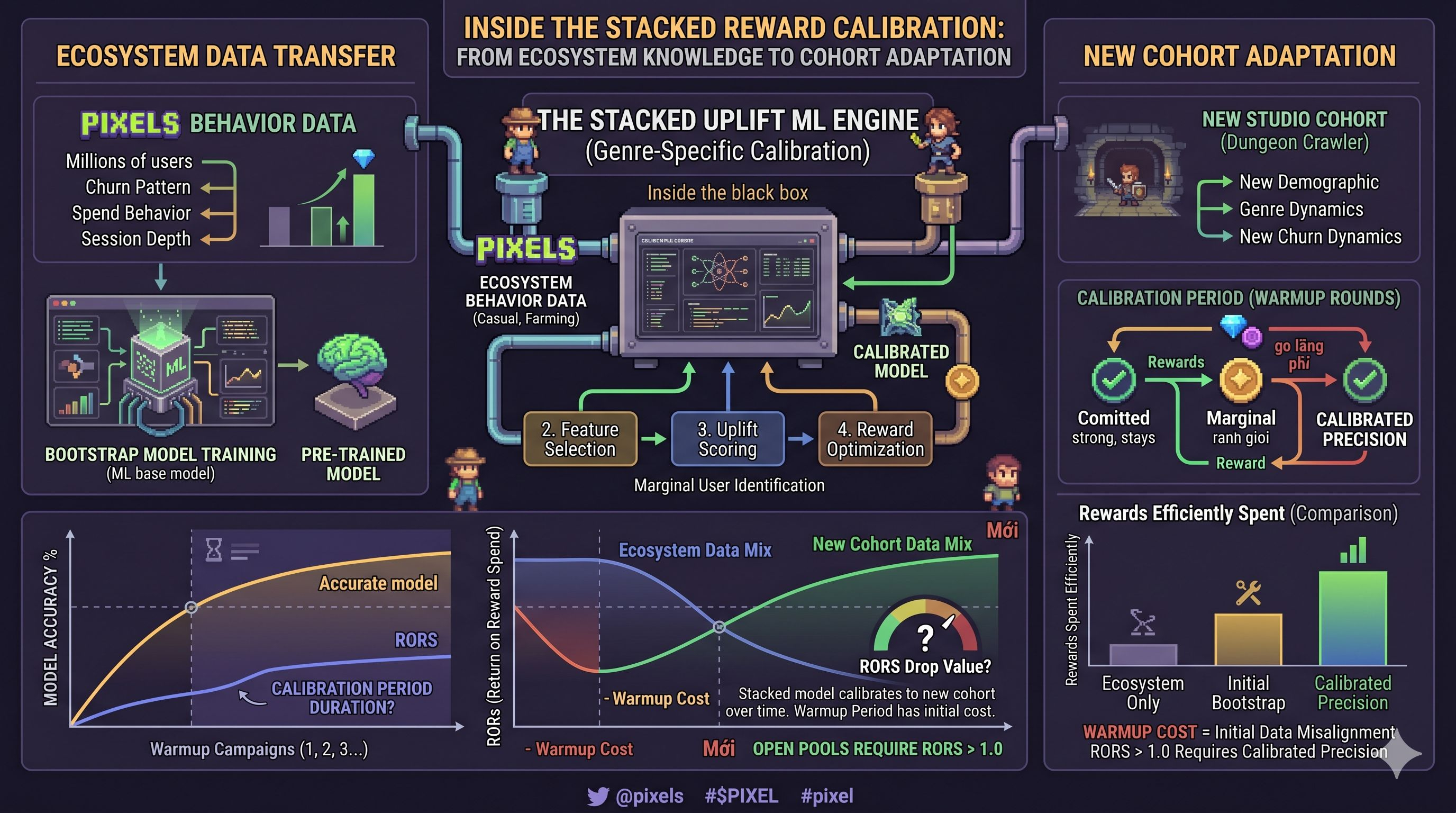
Đây là warmup cost thật của việc tích hợp Stacked. Không ai biết nó kéo dài bao lâu vì chưa có public case study nào về external studio đã đi qua giai đoạn đó.
Mình không nêu điều này để nói Stacked không hoạt động. 200 triệu rewards đã được xử lý và $25 triệu doanh thu là bằng chứng đủ để không cần tranh luận về tính khả thi của hệ thống.
Mình nêu điều này vì "give the right reward to the right user" là một điểm đến, không phải điểm xuất phát. Studio tích hợp Stacked ngày đầu tiên không nhận được sự chính xác đó ngay lập tức. Họ đang mua vào một hệ thống sẽ trở nên chính xác hơn theo thời gian khi model học được churn dynamic của người chơi họ.
Đó là một sản phẩm tốt với một kỳ vọng cần được đặt đúng chỗ.
Câu hỏi mà bất kỳ studio nào nên hỏi trước khi ký: warmup period của chúng tôi sẽ kéo dài bao nhiêu vòng campaign, và chi phí của giai đoạn đó trông như thế nào trên bảng RORS?
Câu trả lời cho câu hỏi đó quan trọng hơn bất kỳ demo nào về AI game economist.