30/10/2025 Bài viết HEMI #25
Mạng HEMI không chỉ tập trung vào thông lượng hoặc bảo mật, mà còn quản lý độ trễ ở cấp độ mili giây, vì nhiều trường hợp sử dụng nhạy cảm với DeFi và thanh toán có thể mang lại hậu quả tài chính lớn ngay cả với độ trễ nhỏ. Bài viết này sẽ làm rõ các giai đoạn mà ngân sách độ trễ trong HEMI được chia nhỏ, lý do chúng quan trọng và các gợi ý thực tiễn cho các nhà phát triển và nhà sản xuất sản phẩm là gì.

Quan sát các giai đoạn độ trễ:
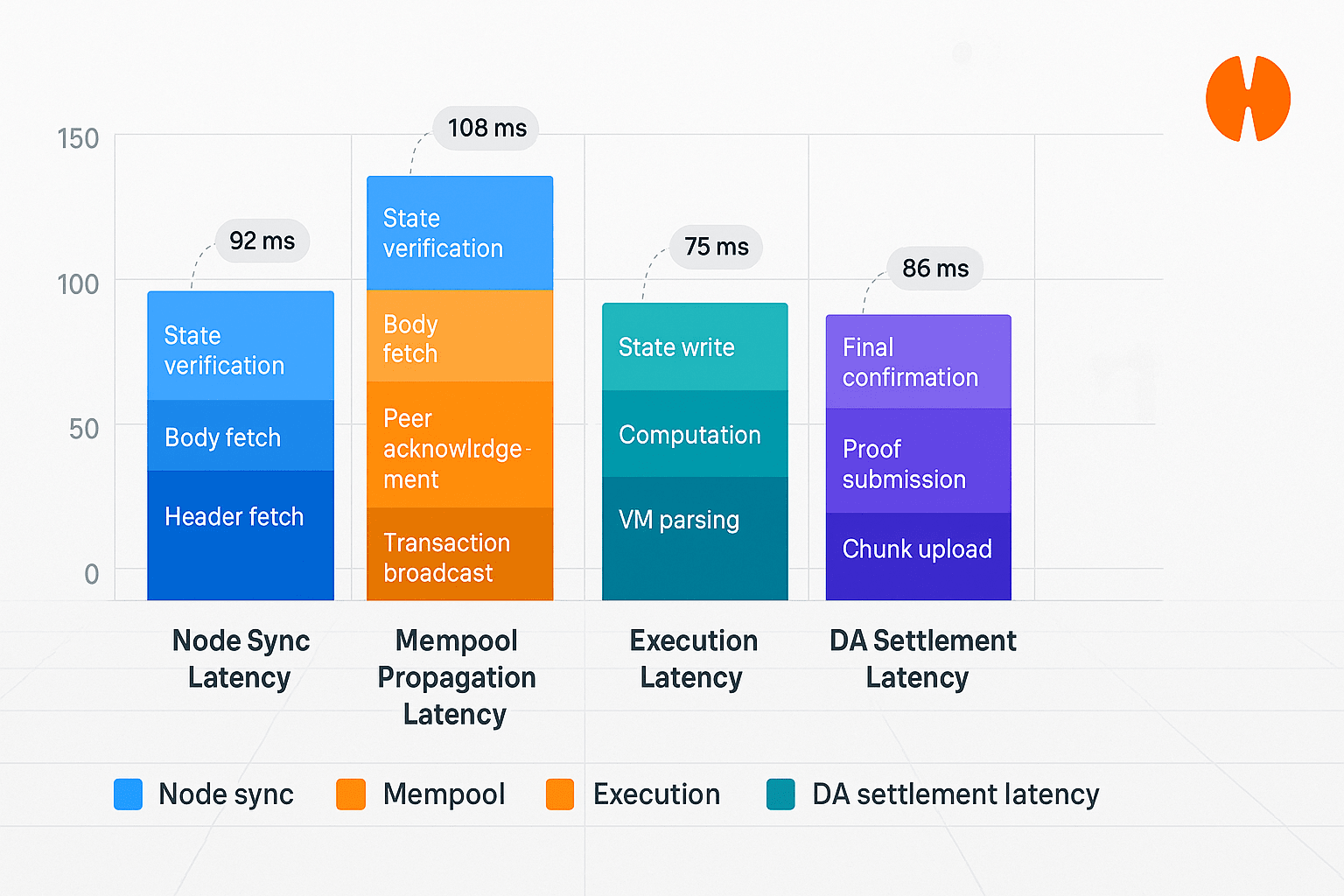
$HEMI Có bốn giai đoạn độ trễ chính trong kiến trúc đóng vai trò quan trọng: độ trễ đồng bộ node, tức là thời gian để một node mới hoặc đang đồng bộ tiếp cận toàn bộ trạng thái mạng; độ trễ truyền bá mempool, tức là khi giao dịch được gửi đi, nó lan rộng nhanh chóng trong mempool của mạng; độ trễ thực thi, tức là thời gian cần thiết để logic hợp đồng thông minh hoặc thực hiện giao dịch; và độ trễ khả dụng dữ liệu, tức là thời gian mà dữ liệu giao dịch trở nên khả dụng và có thể xác minh. Sự kết hợp của các giai đoạn này tạo thành toàn bộ đường đi độ trễ, cần được giám sát và tối ưu hóa một cách hệ thống.
Tại sao ngân sách độ trễ lại quan trọng:
Sự chậm trễ nhỏ có ảnh hưởng trực tiếp đến trải nghiệm người dùng, phản hồi nhanh hơn và thời gian chờ ngắn hơn làm tăng độ tin cậy của ứng dụng. Trong các tình huống thương mại, nếu giữ độ trễ thực thi và DA thấp, nó sẽ mang lại lợi thế cạnh tranh cho mạng trong các chiến lược nhạy cảm với độ trễ và arbitrage. Trong bối cảnh an ninh, độ trễ cũng không thể bị bỏ qua; độ trễ DA hoặc đồng bộ node dài có thể hiếm nhưng gây ra rủi ro tái tổ chức nghiêm trọng hoặc trạng thái không đồng nhất. Do đó, chỉ bằng cách xác định độ trễ ở cấp độ mili giây, các mô hình rủi ro thực tế mới có thể được xây dựng.
Những hiểu biết chính và các vấn đề kiến trúc:
@Hemi Thiết kế độ trễ làm việc dựa trên nguyên tắc của pipeline, tổng hợp stack độ trễ của các thành phần khác nhau để tính toán độ trễ dự kiến tổng. Các nhà phát triển cần hiểu loại ứng dụng nào nhạy cảm ở giai đoạn nào; ví dụ, trong thanh toán tức thì hoặc khớp đơn hàng, độ trễ Mempool và Thực thi là rất quan trọng, trong khi trong các giao dịch giá trị lớn, độ trễ DA và đồng bộ node cũng trở nên quyết định. Theo dõi độ trễ trong các hình ảnh trực quan như biểu đồ cột chồng giúp nhận diện các điểm nghẽn và thiết lập các mục tiêu SLA.
Gợi ý thực tiễn tập trung vào nhà phát triển:
Tạo một bản đồ độ trễ cho dApp của bạn, nơi ghi lại các phép đo ước lượng và thực tế cho mỗi giai đoạn; bao gồm các bài kiểm tra hồi quy độ trễ trong CI để hiển thị xu hướng cho mỗi cam kết. Thiết lập giám sát mạng và khả năng quan sát để báo cáo theo dõi end-to-end, độ trễ p95/p99 và thời gian truyền bá mempool. Khi cần thiết, áp dụng các chiến lược như xếp hàng ưu tiên, điều chỉnh truyền bá mempool và nhóm thực thi để giúp duy trì trong các lối đi quan trọng. Cuối cùng, thực hiện kiểm tra các kịch bản độ trễ khác nhau trong mô phỏng mạng cục bộ và hạn chế để phát hiện các trường hợp biên trước.
KPI và các chỉ số cần theo dõi:
Bao gồm các chỉ số chính: độ trễ end-to-end (tính bằng mili giây), độ trễ từ mempool đến thực thi, thời gian thực thi cho mỗi giao dịch, thời gian giải quyết DA và độ trễ đồng bộ node. Ghi lại thường xuyên các giá trị p50, p95 và p99 của các KPI này và tạo cảnh báo khi các ngưỡng bị phá vỡ. Bên cạnh đó, cũng nên giữ các KPI hướng tới kinh doanh như số lượng các giao dịch không thành công mỗi giờ và thời gian trung bình để phục hồi.
Kết luận:
Ngân sách độ trễ không còn là điều tạm thời công nghệ; chúng là quyết định sản phẩm, đặc biệt là đối với những mạng mà mili giây quan trọng. HEMI đã chỉ ra rằng việc lập bản đồ rõ ràng các giai đoạn Node, Mempool, Thực thi và DA cho thấy rằng thiết kế hiệu suất là một trách nhiệm tổng thể. Nếu bạn đang xây dựng trên HEMI hoặc đánh giá mạng, hãy ưu tiên quản lý độ trễ trong kiến trúc và tiêu chuẩn QA của bạn.
Hãy kết nối với IncomeCrypto để biết thêm thông tin về dự án này.


@Hemi $HEMI #Hemi #HEMINetwork #BlockchainPerformance #CryptoLatency