Mình đọc mô tả của OpenLedger trên CoinCarp và dừng lại ở một câu: "its attribution technology based on Stanford research paper." Câu đó ngắn và được đặt ở cuối đoạn giới thiệu như một điểm bổ sung. Nhưng khi mình đọc lại, nó thực ra là câu quan trọng nhất trong toàn bộ value proposition của OpenLedger. Toàn bộ hệ sinh thái, từ Datanet đến Payable AI Models đến OctoClaw, đều xây trên giả định rằng Proof of Attribution có thể đo lường được đóng góp của từng dataset lên output của một AI model. Nếu giả định đó đúng, OpenLedger giải được bài toán $500 tỷ. Nếu giả định đó chỉ đúng một phần, toàn bộ incentive structure của hệ thống sẽ phân phối phần thưởng không chính xác.
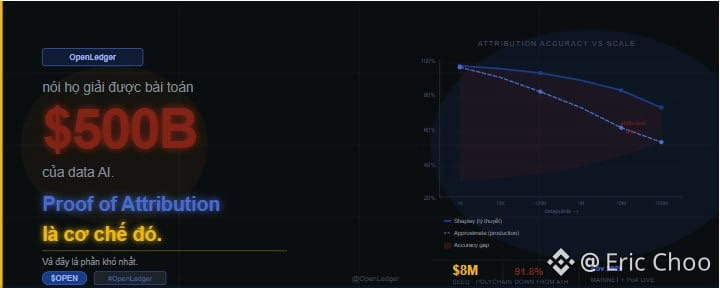
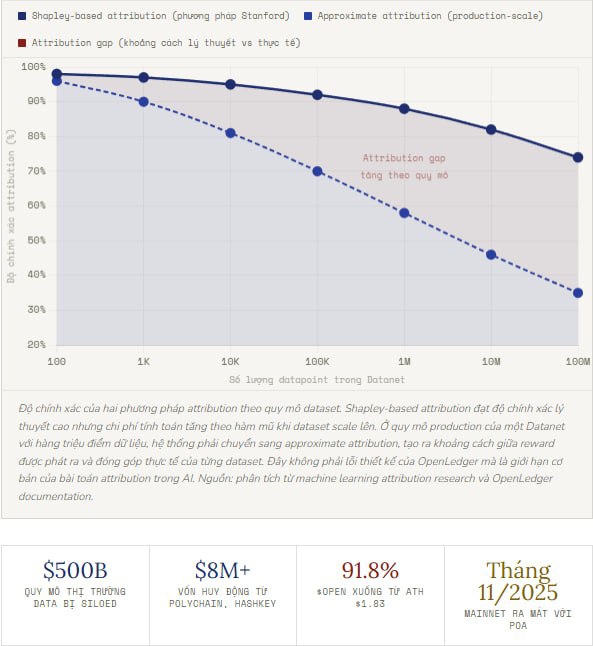
Để hiểu tại sao đây là vấn đề kỹ thuật thật sự chứ không phải lo lắng lý thuyết, cần nhìn vào bài toán attribution trong AI research. Câu hỏi "dataset nào đóng góp bao nhiêu phần trăm vào output của model?" là một trong những câu hỏi khó nhất trong machine learning hiện đại. Một model được train trên hàng triệu datapoint, và ảnh hưởng của từng điểm dữ liệu lên output không phải là tổng tuyến tính. Hai dataset có thể reinforcement lẫn nhau, counteract lẫn nhau, hoặc tương tác theo cách mà không thể decompose ngược lại. Research paper gốc của Stanford mà OpenLedger đề cập, khả năng cao là nghiên cứu về data valuation và Shapley values, cung cấp một framework toán học hợp lý cho bài toán này. Nhưng framework toán học và on-chain implementation ở production scale là hai thứ rất khác nhau.
OctoClaw, agent mới nhất của OpenLedger ra mắt tháng 4 năm 2026, tích hợp execution và data retrieval trong cùng một hệ thống. Đây là bước đi đúng hướng vì nó cho phép agent không chỉ gọi data mà còn thực thi action dựa trên data đó trong cùng một luồng. ERC-4626 integration được OpenLedger triển khai gần đây tạo ra vault standard cho AI model revenue, cho phép model tự động phân phối thu nhập cho data contributor. EVM Bridge kết nối OpenLedger với các chain khác. Những thứ này đều là infrastructure thật, không phải whitepaper. Mainnet đã ra mắt tháng 11 năm 2025. LayerZero integration cho phép data và asset di chuyển qua 130 chain. Đây là công việc engineering thật và đáng ghi nhận.
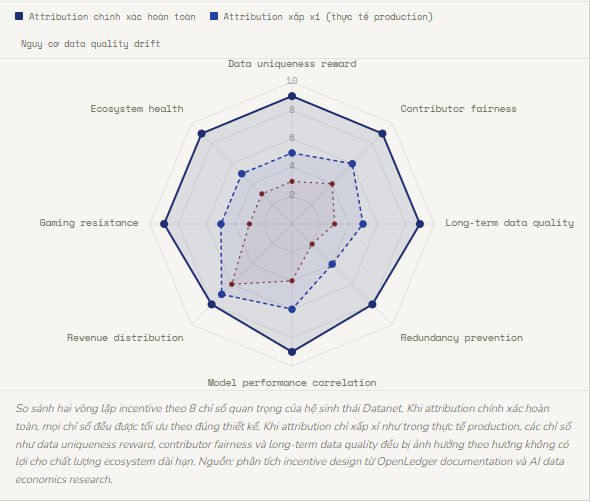
Nhưng câu hỏi mà mình muốn đặt ra không phải về engineering. Nó về incentive design khi attribution không hoàn hảo. Hãy nghĩ về một Datanet cụ thể trên OpenLedger, ví dụ một tập hợp data về financial market sentiment. Một contributor đưa vào 10.000 datapoint chất lượng cao nhưng từ một nguồn đã được nhiều contributor khác cung cấp với dạng tương tự. Một contributor khác đưa vào 100 datapoint từ một nguồn độc đáo chưa từng có trong network. Nếu attribution system không đủ granular để phân biệt hai loại đóng góp đó, contributor thứ nhất sẽ được reward theo volume trong khi contributor thứ hai bị underpay so với giá trị thực của data độc đáo họ cung cấp. Theo thời gian, incentive structure đó sẽ khuyến khích volume hơn là uniqueness, và Datanet sẽ tích lũy nhiều data redundant hơn là data có giá trị thật.
OpenLedger đang giải đúng bài toán. Nhưng cách giải quyết bài toán attribution chính xác đến đâu sẽ quyết định liệu hệ sinh thái tích lũy data thật sự có giá trị hay chỉ tích lũy data đủ tiêu chuẩn để claim reward.
Mình không nói OpenLedger đang làm sai. Enterprise buyback bằng revenue thật cho thấy đội ngũ đang nghiêm túc với long-term value. Story Protocol partnership để giải quyết legal AI training là một usecase cụ thể và có thật. Attribution Engine update tháng 1 năm 2026 đảm bảo data-output links vẫn intact khi model được fine-tune, đây là một chi tiết kỹ thuật quan trọng cho thấy đội ngũ đang suy nghĩ đúng về vấn đề. $8 triệu từ Polychain Capital và HashKey Capital là validation từ những tổ chức hiểu infrastructure layer đủ để đặt cược vào đây.
Phần mình thấy cần theo dõi kỹ hơn không phải là execution hiện tại mà là khi Datanet scale lên và số lượng contributor tăng đáng kể. Đây là lúc approximate attribution sẽ bắt đầu tạo ra sai số tích lũy đủ lớn để thay đổi hành vi của contributor. Nếu OpenLedger có thể publish on-chain metrics về attribution accuracy, về tỉ lệ data unique vs redundant trong từng Datanet, và về correlation giữa reward distribution và actual model performance improvement, thì đó sẽ là bằng chứng mạnh nhất rằng Proof of Attribution đang hoạt động đúng cách chứ không phải chỉ là một tên gọi hay cho một vấn đề chưa được giải quyết hoàn toàn. OctoClaw là agent chạy trên infrastructure đó. ERC-4626 vault là cơ chế phân phối revenue từ infrastructure đó. Cả hai đều hữu ích và cả hai đều phụ thuộc vào việc lớp nền bên dưới, tức là PoA, đang đo lường đúng thứ nó cần đo lường.
Khi Datanet của OpenLedger scale lên hàng triệu datapoint từ hàng nghìn contributor, liệu Proof of Attribution có thể duy trì đủ granularity để phân biệt data unique thật sự có giá trị với data redundant chỉ đủ tiêu chuẩn claim reward, và nếu không thể, incentive structure của toàn bộ hệ sinh thái sẽ bị kéo theo hướng nào?