Những từ đã thay đổi cách tôi đọc OpenLedger không phải là những từ to nhất. Chúng là những từ thực tiễn xung quanh quy trình phát triển: hoàn tất, khóa API, ID yêu cầu, nhật ký chi tiêu, số lượng token, truy cập mô hình, và hồ sơ sử dụng. Lớp kế toán nhỏ bé đó khiến dự án này cảm thấy khác biệt với tôi. OpenLedger không chỉ là về việc Datanets cung cấp dữ liệu cho các mô hình AI, ModelFactory giúp tạo ra các mô hình chuyên biệt, OpenLoRA làm cho việc triển khai mô hình nhẹ nhàng hơn, hoặc Proof of Attribution liên kết các đầu ra trở lại với những người đóng góp. Câu hỏi sắc bén hơn là điều gì sẽ xảy ra khi một người dùng, ứng dụng, hoặc tác nhân thực sự gọi đến trí thông minh đó.
Đó là nơi yêu cầu AI trở nên quan trọng.
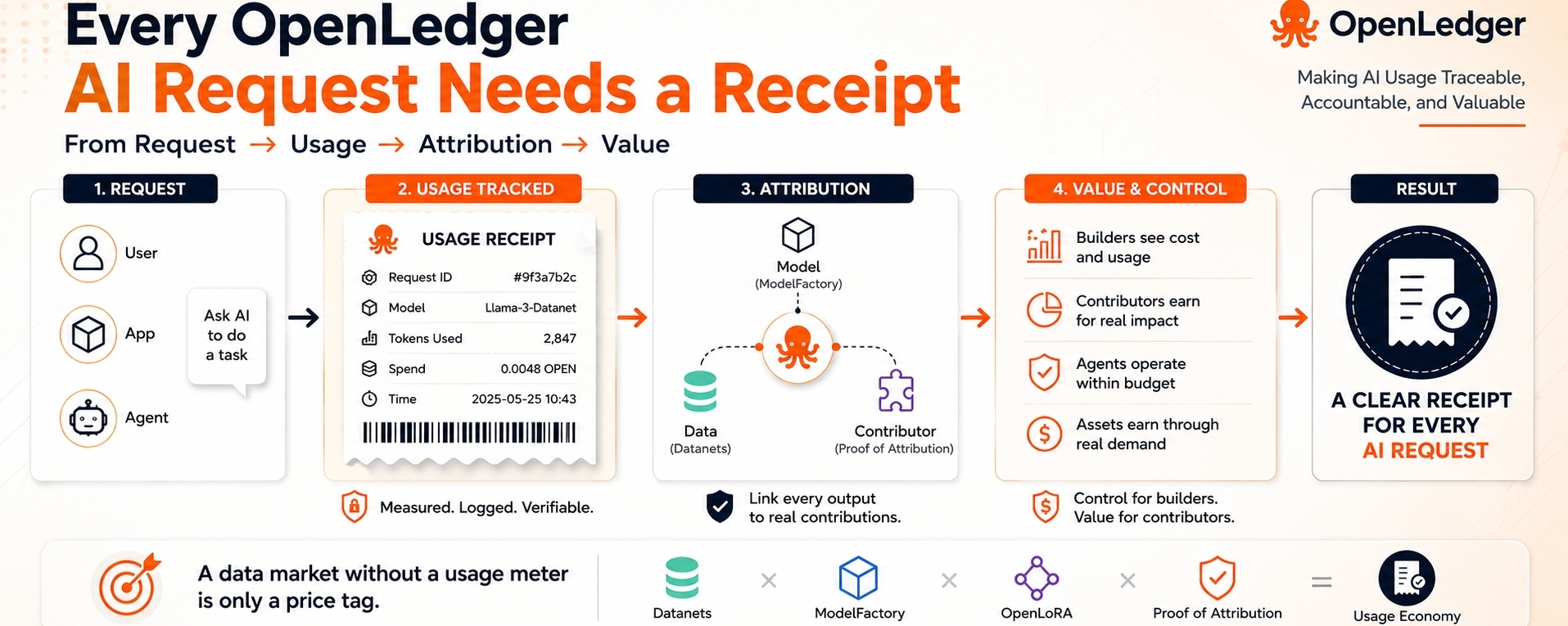
Một tập dữ liệu có thể có giá trị. Một mô hình có thể có giá trị. Một tác nhân có thể có giá trị. Nhưng nếu không ai có thể thấy nó được sử dụng thường xuyên như thế nào, giá của nó là gì, mô hình nào xử lý cuộc gọi đó, và sự đóng góp nào là quan trọng, thì tài sản vẫn còn mù mờ về mặt kinh tế. Nó có thể có một cái tên. Nó có thể có quyền sở hữu. Nó thậm chí có thể có một câu chuyện thưởng. Nhưng nó vẫn chưa có một hồ sơ hoạt động rõ ràng.
Một thị trường dữ liệu mà không có đồng hồ sử dụng chỉ là một cái mác giá.
Đó là lý do tại sao lớp sử dụng của OpenLedger xứng đáng được chú ý hơn so với những gì nó thường nhận được. Hầu hết mọi người tự nhiên tập trung vào phía thưởng. Những người đóng góp muốn biết liệu dữ liệu của họ có thể kiếm được không. Các nhà xây dựng mô hình muốn biết liệu công việc của họ có thể được ghi nhận hay không. Những người nắm giữ token tìm kiếm tiện ích. Đó là những câu hỏi hợp lệ. Nhưng một nhà xây dựng đang chạy một ứng dụng thực sự có một câu hỏi lạnh lùng hơn: tôi có thể kiểm soát việc sử dụng trước khi chi phí tăng vọt không?
Đây là nơi cơ chế của OpenLedger trở nên nghiêm túc hơn. Nếu một mô hình được gọi thông qua một hoàn thành theo kiểu API, cuộc gọi đó có thể trở thành nhiều hơn một phản hồi trên màn hình. Nó có thể trở thành một sự kiện với một mô hình, một yêu cầu, một ghi chép chi tiêu, việc sử dụng token, ngữ cảnh người dùng và một con đường quy thuộc. Điều đó biến hoạt động AI thành thứ mà một nhà xây dựng có thể đo lường. Và khi nó có thể được đo lường, nó có thể được định giá, giới hạn, so sánh, lặp lại hoặc dừng lại.
Điều đó thay đổi ai có đòn bẩy.
Các nhà xây dựng có được đòn bẩy vì họ không còn mua quyền truy cập mơ hồ vào "AI." Họ có thể xem xét việc sử dụng. Họ có thể thấy mô hình nào đang được gọi. Họ có thể hiểu chi tiêu. Họ có thể quyết định liệu một quy trình làm việc có đáng để chạy lại hay không. Những người đóng góp cũng có lợi, nhưng chỉ khi sự đóng góp của họ thực sự xuất hiện trong những đầu ra hữu ích. Dữ liệu ít tác động có ít chỗ để ẩn náu khi hệ thống đang chú ý đến việc sử dụng, không chỉ là những tuyên bố về quyền sở hữu.
Nhóm mất đi tính linh hoạt là người bán tài sản AI mơ hồ. Nếu một tài sản không thể thu hút các cuộc gọi lặp lại, không thể kết nối với những đầu ra hữu ích, hoặc không thể được đo lường trong việc sử dụng thực tế, thì câu chuyện của nó sẽ yếu đi. Nó trở thành hàng tồn kho, không phải là một thị trường.
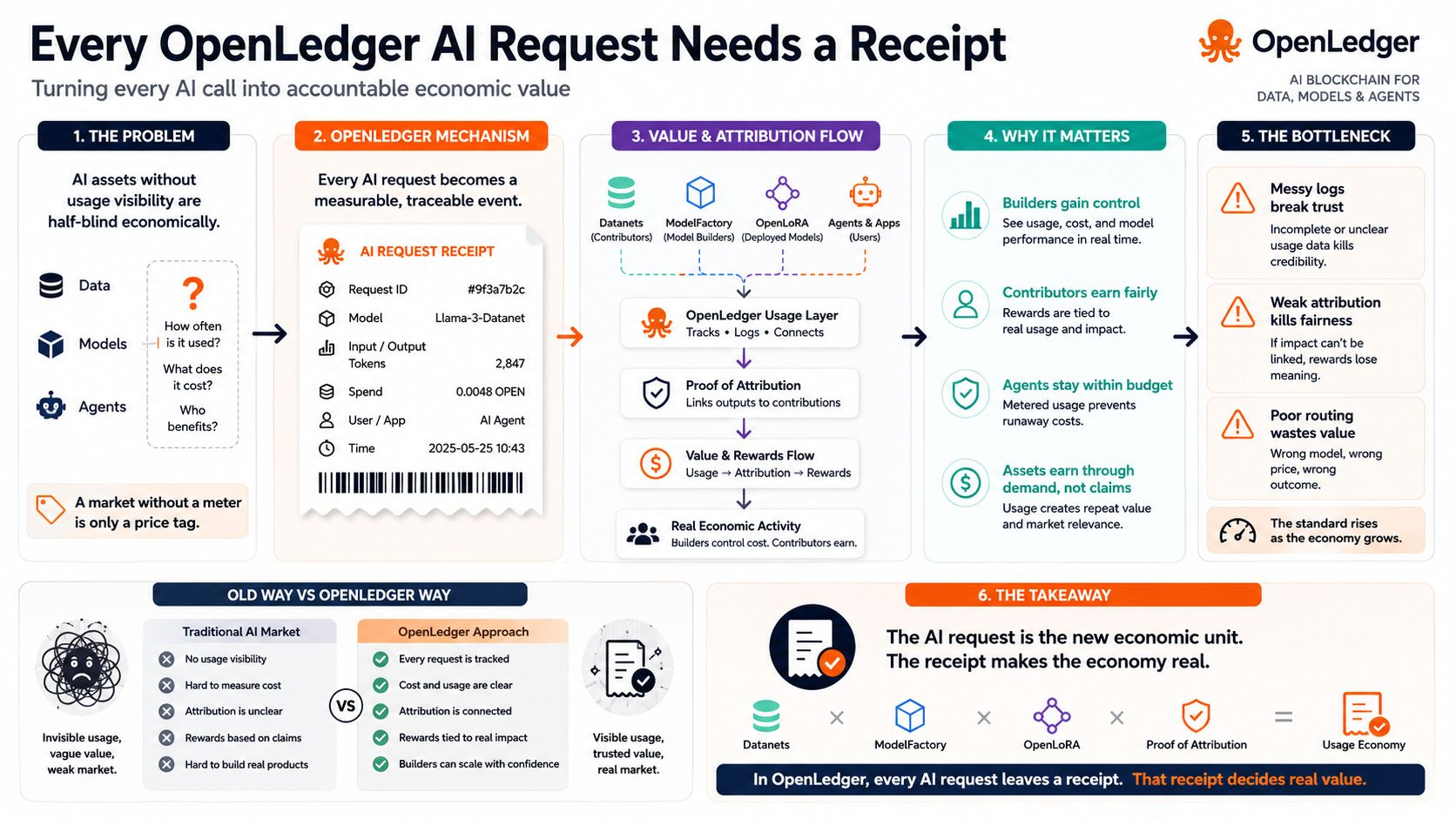
Đó là một tuyên bố khó hơn, nhưng tôi nghĩ nó quan trọng. Việc kiếm tiền từ AI dễ mô tả nhưng khó vận hành. Một dự án có thể nói rằng dữ liệu, mô hình, và tác nhân sẽ kiếm được. Phần khó khăn hơn là chứng minh rằng mọi con đường kiếm tiền đều xuất phát từ một cái gì đó có thể theo dõi: một yêu cầu, một cuộc gọi mô hình, một chi phí được ghi lại, một tín hiệu quy thuộc, và một lý do để ai đó trả tiền một lần nữa. Con đường mạnh mẽ hơn của OpenLedger là nó không dừng lại ở việc "những người đóng góp nên được thưởng." Nó chỉ ra một hệ thống mà phần thưởng có thể được gắn liền với việc sử dụng AI thực tế.
Bên tác nhân làm cho điều này càng quan trọng hơn. Một người dùng bình thường có thể hỏi một câu và rời đi. Một tác nhân có thể gọi nhiều mô hình nhiều lần trong một nhiệm vụ. Nó có thể tạo ra nhu cầu lặp lại, các yêu cầu liên kết, và chi phí tăng nhanh hơn mong đợi. Nếu không có khả năng nhìn thấy chi tiêu và theo dõi việc sử dụng ở cấp độ mô hình, các tác nhân trở thành rủi ro ngân sách. Với một đồng hồ, hoạt động của tác nhân trở thành thứ mà một nhà điều hành có thể quản lý thay vì lo sợ.
Đây là nút thắt thực tiễn. Nếu nền kinh tế của OpenLedger mở rộng, áp lực không chỉ đến từ việc có đủ dữ liệu hay có đủ mô hình được tạo ra. Nó sẽ đến từ việc liệu việc sử dụng có đủ sạch để tin tưởng hay không. Nhật ký lộn xộn, chi tiêu không rõ ràng, quy thuộc yếu, hoặc định tuyến mô hình kém sẽ gây hại cho những người cần hệ thống nhất: các nhà xây dựng đang cố gắng biến AI thành những sản phẩm có thể lặp lại.
Đó cũng là sự đánh đổi. Nhiều kế toán tạo ra nhiều uy tín hơn, nhưng cũng nâng cao tiêu chuẩn. Khi hệ thống nói rằng mọi tài sản AI đều có thể kiếm tiền, nó cũng phải chỉ ra lý do tại sao việc kiếm tiền đó là xứng đáng. Khi nó nói rằng những người đóng góp có thể nhận thưởng, nó phải chỉ ra cách sử dụng nào đã làm cho phần thưởng trở nên có ý nghĩa. Khi nó nói rằng các tác nhân có thể trở thành những người tham gia kinh tế, nó phải chỉ ra cách hoạt động của họ có thể được theo dõi trước khi trở thành chi phí không kiểm soát.
Đó là lý do tôi xem OpenLedger ít hơn như một câu chuyện tài sản AI đơn giản và nhiều hơn như một nền kinh tế sử dụng. Datanets, ModelFactory, OpenLoRA, và Proof of Attribution là những phần quan trọng, nhưng yêu cầu là nơi những phần đó gặp thị trường. Đó là nơi một nhà xây dựng thấy chi phí. Đó là nơi một người đóng góp chứng minh được ảnh hưởng. Đó là nơi một mô hình kiếm được nhu cầu lặp lại.
Nếu OpenLedger có thể làm cho mỗi yêu cầu AI để lại một biên lai rõ ràng, nền kinh tế của nó trở nên khó giả mạo hơn rất nhiều. Tài sản không có việc sử dụng mất sức mạnh. Những người đóng góp không có tác động mất chỗ ẩn náu. Các nhà xây dựng có hồ sơ sạch sẽ có được quyền kiểm soát.
Trong OpenLedger, yêu cầu có thể trở thành biên lai. Và biên lai có thể quyết định những tài sản AI nào thực sự đáng để trả tiền.
