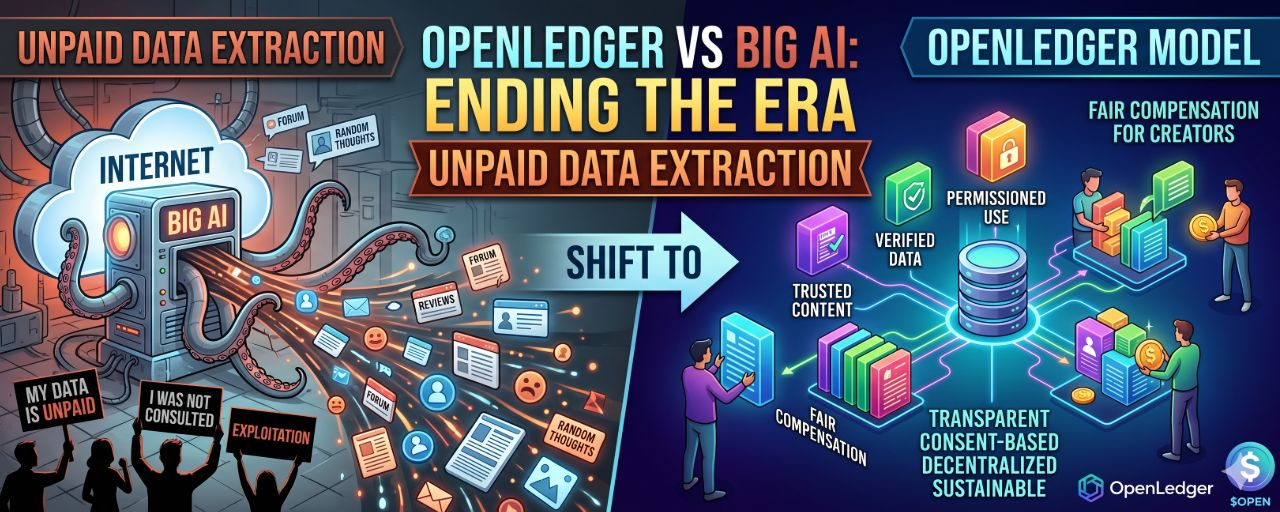
AI’s smartest outputs may be built on the internet’s largest extraction economy.
When I first looked closely at how modern AI systems are actually fed, what struck me was how ordinary the raw material is. Not exotic sensor networks. Not carefully commissioned research archives. Just us. Forum posts, product reviews, code repositories, news articles, tutorials, conversations, documentation, comments written at 1 a.m. by someone trying to fix a broken server. The texture of the internet became training fuel.
That framing matters because we often talk about AI as if intelligence appears mainly through engineering breakthroughs. The engineering is real, but underneath it sits a quieter economic model: large-scale data extraction. Publicly accessible information gets harvested, cleaned, tokenized, indexed, and converted into something machines can statistically learn from. The end product feels conversational and polished. The upstream supply chain looks much messier.
On the surface, this seems reasonable. Search engines have crawled the web for decades. Public data is, by definition, public. If someone publishes code on a forum or writes a blog post, why should machines not read it?
The deeper answer is scale.
A human researcher can read hundreds of papers. A frontier AI model absorbs patterns from datasets measured in trillions of tokens. A token is roughly a fragment of a word, which means we are talking about language volumes that dwarf any human reading capacity. OpenAI’s user growth alone hints at the hunger behind this. Reuters reported ChatGPT passed 400 million weekly active users in early 2025, and that number has since accelerated dramatically. (Reuters) A product serving that many people cannot rely on boutique datasets. It needs industrial supply.
That creates the extraction economy.
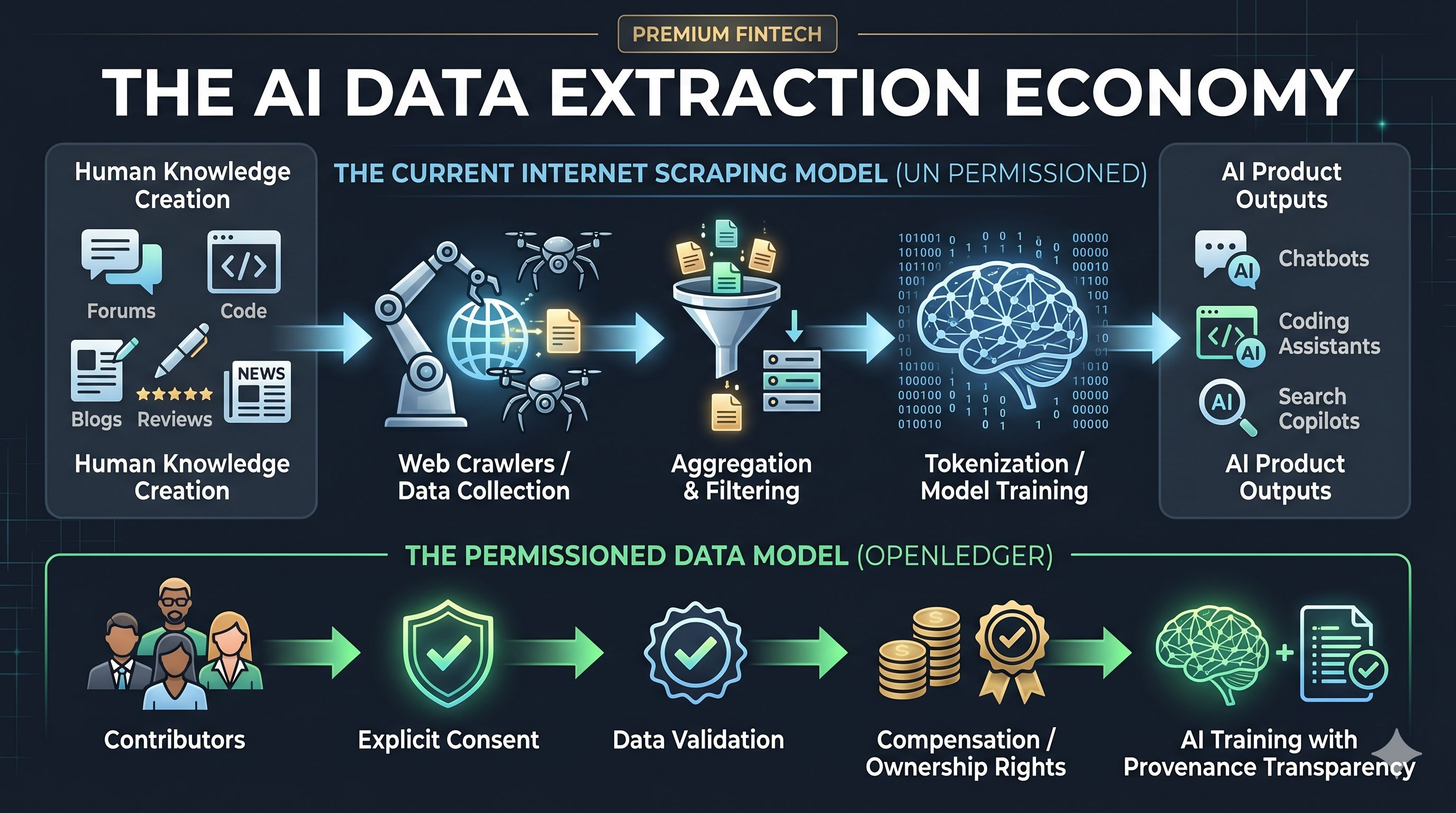
It works in layers. First comes collection. Crawlers gather publicly accessible text, images, code, and metadata. Then comes aggregation, where scattered information becomes structured corpora. Underneath that, ranking and filtering systems decide what counts as useful. Then model training converts that data into statistical relationships. No article remains intact in the way a PDF remains intact. Instead, patterns get compressed into model behavior.
That distinction is where much of the debate lives.
AI companies argue models learn from data rather than store exact copies of it, much like humans learn by reading. Critics respond that the comparison breaks down when the “reading” involves ingesting millions of creators’ work at machine scale without explicit permission.
And the economics make that criticism harder to dismiss.
Reddit’s IPO filings revealed data licensing arrangements worth $203 million in aggregate contract value tied partly to AI access. (TechCrunch) That number tells us something important. Data that was once treated as ambient internet exhaust is now monetizable infrastructure. Conversation itself became an asset class.
But notice who gets paid.
Usually the platform. Not the commenter who spent years building expertise in a niche subreddit. Not the volunteer moderator maintaining discussion quality. Not the developer whose debugging answer trained future coding assistants.
That momentum creates another effect. The open web starts changing behavior in response to extraction.
Publishers tighten access. APIs get restricted. Communities become suspicious of bots. Some creators deliberately withhold high-value content. Others shift into paywalled ecosystems. What looked like an unlimited commons begins behaving like a depleted resource.
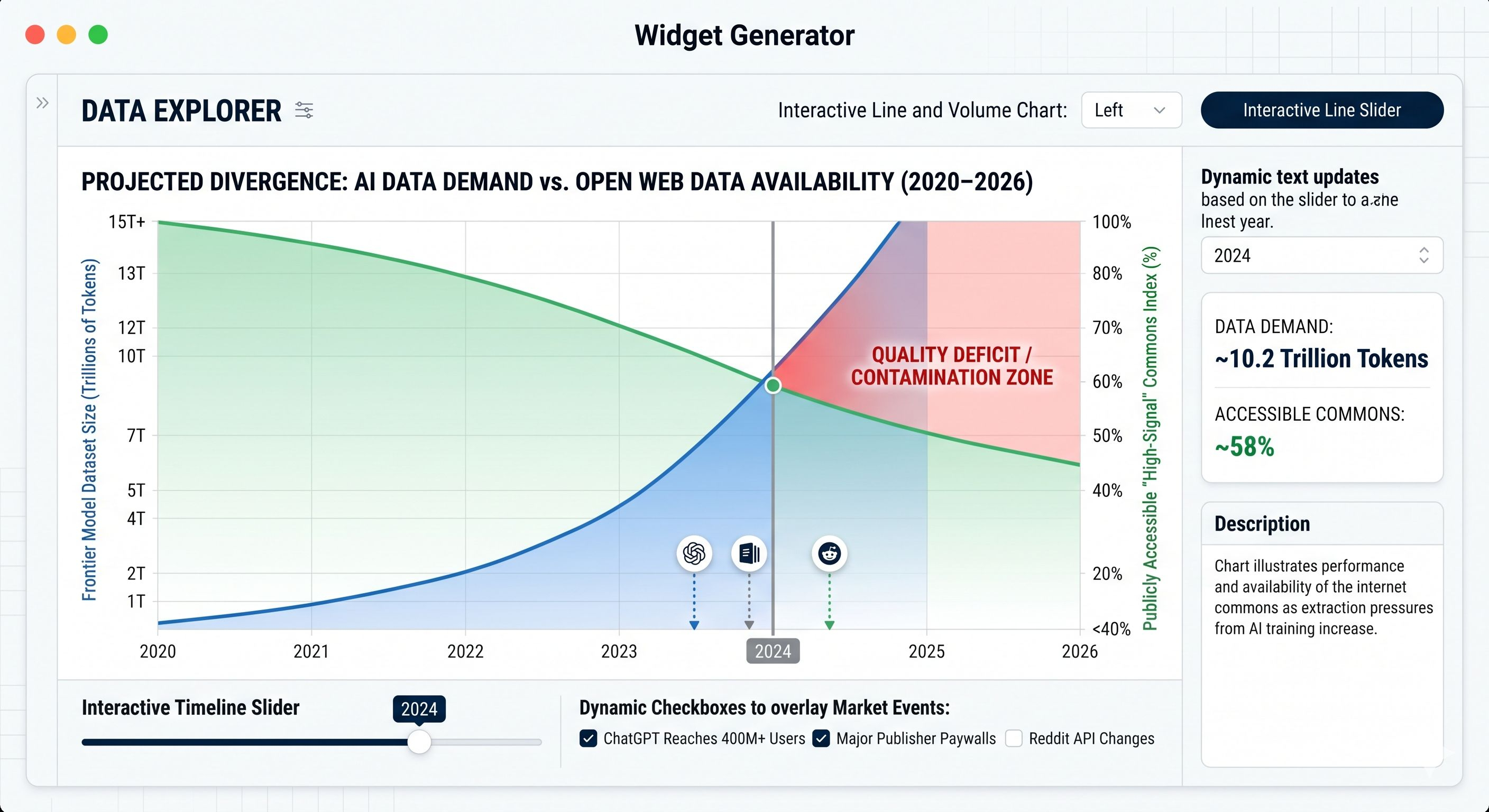
There is also a quality problem that gets less attention than the ethics.
Extraction at scale is noisy. The internet contains brilliance, spam, outdated facts, sarcasm mistaken for truth, synthetic content, copied content, and coordinated manipulation. Bigger datasets do not automatically mean cleaner intelligence. Sometimes they just mean larger contamination.
This becomes more urgent right now because the market is rewarding speed. AI valuations remain tied to capability gains, user growth, and distribution dominance. In that environment, dataset volume becomes competitive pressure. If your rival trains faster, your incentive is not patience. It is acquisition.
That is where alternative models like OpenLedger become interesting.
The core idea is simple: instead of treating data as something passively extractable, treat it as something contributed under explicit economic terms.
That sounds abstract until you compare the incentives.

In the extraction model, contributors often do not know their data is creating downstream commercial value. In a permissioned contribution model, participants knowingly provide data, usage rights are defined, and compensation can be attached to usefulness. Transparent provenance becomes part of the architecture instead of a legal afterthought.
The obvious criticism is friction. Permission slows things down. Negotiation costs money. Frontier models may need data diversity that voluntary contribution networks cannot yet match.
That is fair.
But friction is not always inefficiency. Sometimes friction is governance.
Financial markets learned this the hard way. Social platforms learned it too. Systems that scale rapidly by externalizing costs tend to look efficient until the hidden liabilities arrive. Trust erosion is one of those liabilities.
A value-aligned data model could produce smaller but cleaner datasets. That matters more than many assume. If a dataset has clearer provenance, higher signal quality, and fewer legal ambiguities, the effective training value per token may rise even if absolute volume falls.
There is also an incentive design question that feels bigger than AI.
If human knowledge is becoming machine infrastructure, how should value flow?
That question reaches far beyond model training. It touches journalism, education, software communities, research publishing, even creative labor. The internet was built around asymmetric exchange. People shared for visibility, reputation, curiosity, community, or indirect monetization. AI introduces a much more direct extraction mechanism.
And once that becomes visible, expectations change.
We are already seeing early signs. Publishers are licensing archives. Platforms are renegotiating access. Courts are becoming battlegrounds over fair use and ownership. Technical architectures are shifting toward retrieval systems, synthetic data, and specialized proprietary datasets.
What this reveals is that the real AI race may not just be about model architecture. It may be about who secures legitimate access to trusted human knowledge.
Open extraction helped bootstrap the current generation. That much seems undeniable. Without the open web, today’s AI products would be far less capable.
But bootstrapping is not the same as sustainability.
An economy built on taking first and formalizing later eventually teaches participants to lock their doors.
The sharpest question is not whether AI can keep extracting. It is whether intelligence built from human knowledge can remain trusted if the humans who created that knowledge increasingly feel like unpaid infrastructure.
@OpenLedger $OPEN #OpenLedger