
Hầu hết các dự án AI trong Web3 vẫn cảm thấy mắc kẹt trong cùng một vòng lặp.
Một câu chuyện mới xuất hiện, mọi người đổ xô vào, phần thưởng bùng nổ trong vài tuần, và sau đó sự phấn khích từ từ biến mất vì sản phẩm thực sự không bao giờ mạnh hơn sự cường điệu xung quanh nó.
Tôi đã thấy điều này xảy ra quá nhiều lần, đặc biệt trong lĩnh vực AI. Mỗi dự án đều tuyên bố đang xây dựng "tương lai", nhưng bên dưới, hầu hết vẫn dựa vào những hệ thống và cơ sở hạ tầng cũ rích.
Đó chính là lý do tại sao tôi đã nhìn OpenLedger với nhiều hoài nghi ngay từ đầu.
Tôi đã nghĩ rằng "Mô hình Chuyên biệt" chỉ là một từ buzz Web3 AI được đánh bóng khác được thiết kế để lướt trên làn sóng câu chuyện. Nhưng sau khi dành thời gian đọc về kiến trúc Datasets và Datanets của OpenLedger, tôi nhận ra dự án đang cố gắng giải quyết điều gì đó sâu sắc hơn nhiều so với khả năng hiển thị hay sự suy đoán.
Nó đang cố gắng giải quyết vấn đề sở hữu.
Và điều đó hoàn toàn thay đổi cuộc trò chuyện xung quanh AI phi tập trung.
Một điều luôn làm tôi bận tâm về nền kinh tế AI ngày nay là cách mà các nhà đóng góp trở nên vô hình. Các mô hình AI khổng lồ được đào tạo bằng cách sử dụng khối lượng lớn dữ liệu do con người tạo ra, nhưng những người cung cấp dữ liệu đó hiếm khi biết liệu đóng góp của họ có thực sự quan trọng hay không. Hầu hết thời gian, họ cũng không chia sẻ giá trị được tạo ra sau đó.
OpenLedger tiếp cận điều này theo cách khác.
Thay vì xây dựng một mô hình tổng quát khác được đào tạo trên tiếng ồn vô tận của internet, mạng lưới tập trung vào các Mô hình Chuyên biệt được hỗ trợ bởi các bộ dữ liệu được chọn lọc từ các nhà đóng góp phi tập trung. Nhưng sự khác biệt thực sự không chỉ là "dữ liệu cộng đồng" — chúng ta đã nghe cụm từ đó nhiều lần trước đây.
Phần quan trọng là sự công nhận.
Tôi nhớ ngồi khuya với tách trà trong khi đọc qua các ghi chú về cơ sở hạ tầng của họ, và tôi dừng lại một giây vì ý tưởng nghe có vẻ đơn giản trên bề mặt, nhưng về mặt kinh tế thì nó thay đổi mọi thứ.
Một mô hình AI tài chính có thể được đào tạo đặc biệt trên các bộ dữ liệu tài chính.
Một trợ lý y tế có thể cải thiện bằng cách sử dụng thông tin tập trung vào y tế.
Một mô hình phát triển có thể học từ các kho mã và thảo luận kỹ thuật thay vì những rác rưởi không liên quan trên internet.
Mức độ chuyên biệt đó quan trọng hơn hầu hết mọi người nhận ra.
Cuộc đua AI không còn chỉ là về việc ai sở hữu mô hình lớn nhất. Ngày càng nhiều, nó trở thành về việc ai sở hữu dữ liệu chất lượng cao nhất.
Và đó là nơi OpenLedger bắt đầu trở nên chiến lược thú vị.
Hệ thống Proof of Attribution của họ cố gắng theo dõi cách các bộ dữ liệu đóng góp vào đầu ra của mô hình để giá trị có thể chảy trở lại cho các nhà đóng góp thay vì biến mất vào một hộp đen. Phần đó nổi bật với tôi vì hầu hết các hệ thống AI ngày nay không thể giải thích rõ ràng nguồn gốc của trí thông minh của chúng khi quá trình đào tạo bắt đầu.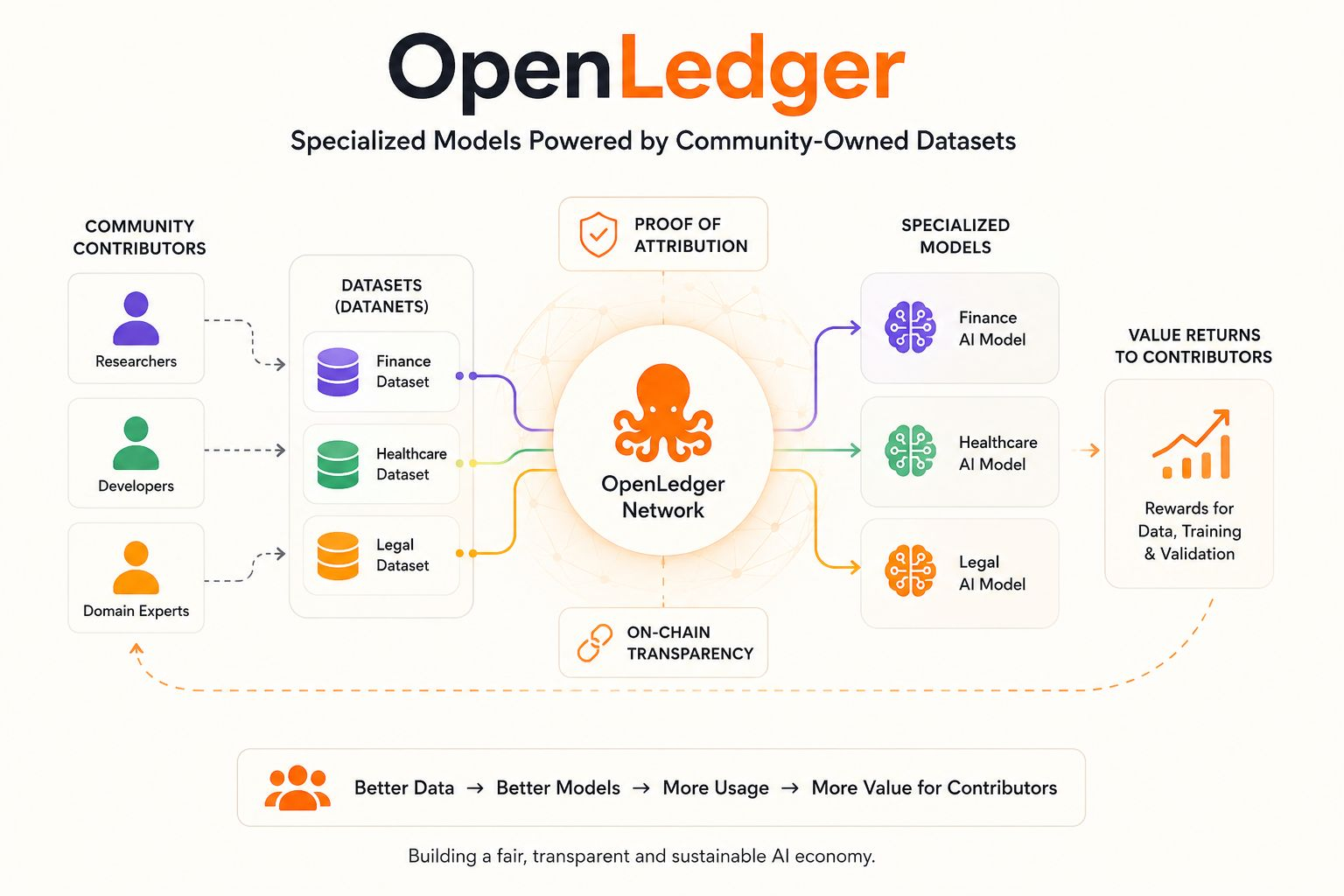
OpenLedger đang cố gắng xây dựng tính truy xuất kinh tế trực tiếp vào cơ sở hạ tầng.
Điều đó tạo ra một cấu trúc khuyến khích lành mạnh hơn nhiều.
Bởi vì khi các nhà đóng góp biết rằng các bộ dữ liệu của họ có thể liên tục tạo ra giá trị thông qua việc sử dụng mô hình, tư duy sẽ chuyển từ việc canh tác ngắn hạn sang tham gia lâu dài. Và thành thật mà nói, Web3 rất cần nhiều hệ thống được thiết kế xung quanh việc giữ chân thay vì khai thác.
Một điều khác làm tôi ngạc nhiên là cách mà suy nghĩ về cơ sở hạ tầng của họ cảm thấy thực tiễn hơn so với nhiều câu chuyện AI đang lưu hành ngày nay.
OpenLedger không chỉ nói về trí thông minh hay mô hình. Họ cũng đang nghĩ về hiệu quả triển khai, suy diễn có thể mở rộng và nền kinh tế dữ liệu tái sử dụng.
Nghe có vẻ kỹ thuật, nhưng điều đó rất quan trọng.
Nhiều dự án AI tập trung hoàn toàn vào ý tưởng trí thông minh trong khi phớt lờ thực tế kinh tế phía sau chi phí tính toán. Cuối cùng, mỗi mạng lưới đều gặp phải cùng một vấn đề: nếu chi phí vận hành trở nên quá đắt đỏ, tính bền vững sẽ biến mất bất kể câu chuyện mạnh mẽ như thế nào trên mạng xã hội.
OpenLedger dường như nhận thức được thách thức đó sớm.
Bây giờ, điều đó có đảm bảo thành công không?
Không hề.
Rủi ro thực thi vẫn còn rất lớn. Xây dựng cơ sở hạ tầng AI phi tập trung đã khó khăn. Xây dựng một cái mà trong đó sự công nhận, khuyến khích, khả năng mở rộng và sự chấp nhận thực sự của nhà phát triển đều hoạt động cùng nhau là một thách thức lớn hơn.
Và có một thực tế khác mà mọi người không thể phớt lờ.
Hầu hết người dùng vẫn chọn sự tiện lợi hơn là sự minh bạch. Các công ty AI tập trung đã thống trị cơ sở hạ tầng, thanh khoản và sự chú ý. OpenLedger đang bước vào một thị trường mà chỉ có sức mạnh kỹ thuật thôi là không đủ. Thách thức lớn hơn là thay đổi hành vi của người dùng.
Nhưng ngay cả với tất cả những rủi ro đó, tôi vẫn quay lại cùng một kết luận.
Điều này không giống như một câu chuyện về token AI ngắn hạn khác.
Nó cảm giác giống như một nỗ lực thiết kế lại cách trí thông minh được cấu trúc kinh tế bên trong Web3.
Và có lẽ đó là lý do tại sao tôi vẫn chú ý đến nó.
Không phải vì sự cường điệu.
Bởi vì dưới tất cả những tiếng ồn xung quanh AI ngay bây giờ, sở hữu có thể lặng lẽ trở thành lớp quan trọng nhất trong tất cả.