
A few nights ago I went down a rabbit hole reading about AI data marketplaces again, and I kept thinking about one old case from a startup in Singapore. They claimed to have millions of user behavior records for training shopping recommendation models. On paper it sounded insanely valuable. Big dataset, AI narrative, enterprise angle, everything.
But later one of their partners tested the model in a real campaign and the performance barely improved. A big chunk of the data was repetitive, noisy, or simply irrelevant outside controlled demos.
That story stayed in my head because it made me realize something uncomfortable: data is not automatically liquid just because it exists.
And honestly, that’s the exact thought I had while reading deeper into OpenLedger around 2AM.
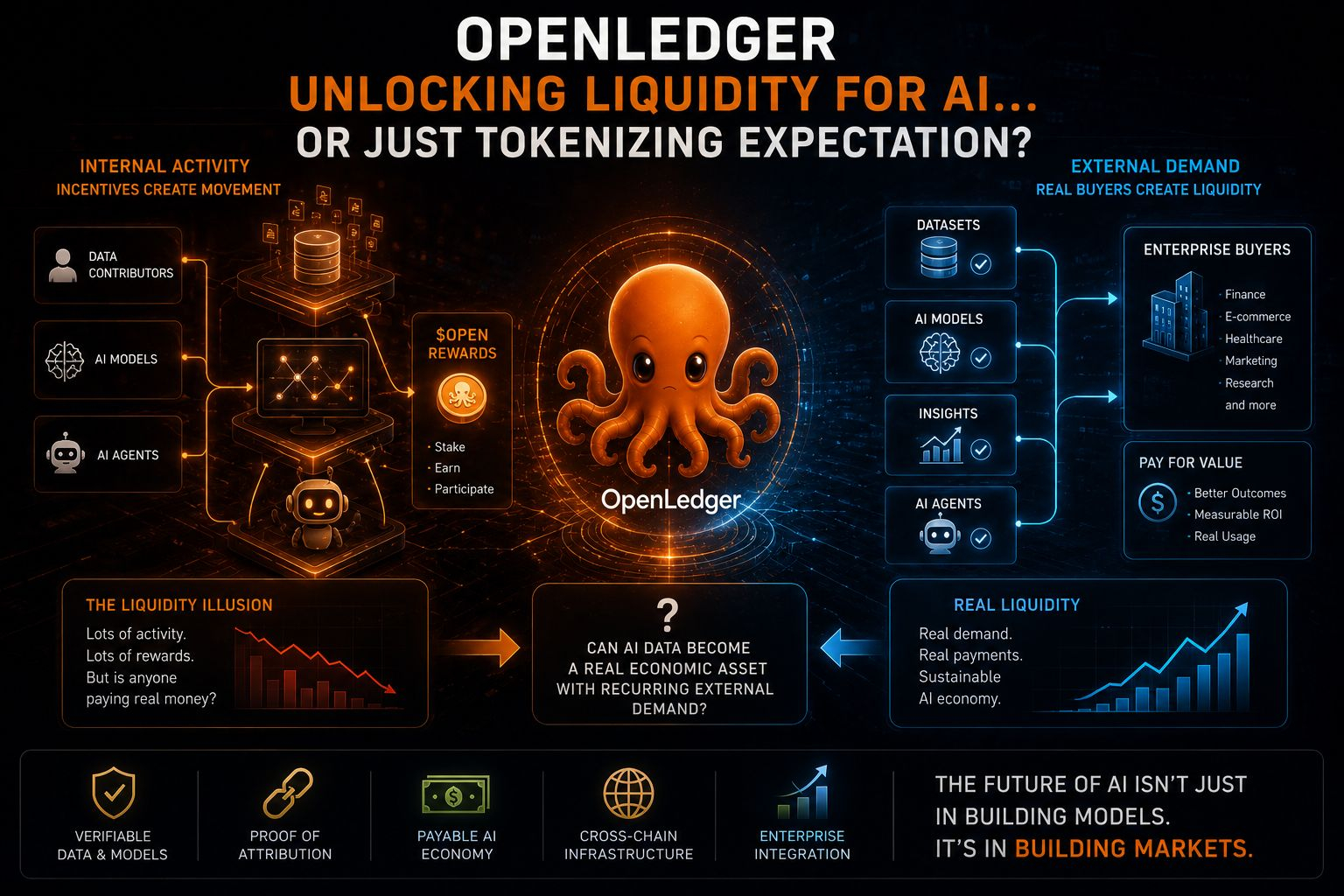
OpenLedger is trying to build an economy where datasets, AI models, and agents can all function like on-chain assets. Contributors upload data, models consume that data, agents execute tasks, and the entire system is connected through OPEN incentives. In theory, it looks like a self-reinforcing AI marketplace.
The idea is attractive because crypto people naturally love the concept of turning inactive resources into tradable assets. But I think there’s an important distinction that gets lost sometimes between activity and liquidity.
Activity is movement.
Liquidity is someone actually paying.
That difference matters a lot more than people think.
Inside OpenLedger, a dataset can generate rewards. An AI model can generate usage metrics. Agents can continuously interact with the ecosystem and create visible on-chain activity. Dashboards look alive. Transactions move. Participants earn tokens.
But none of that automatically proves external demand exists.
I kept comparing it in my head to Ethereum for a while. On Ethereum, users pay gas because they genuinely want blockspace. On oracle networks like Chainlink, companies pay for data because their applications literally depend on it functioning correctly.
OpenLedger is attempting something harder.
It’s trying to create a market where AI data itself becomes the product people repeatedly buy.
And that’s where the challenge becomes very real.
Imagine an agent on OpenLedger scraping social media trends. Another model trains on that dataset to generate marketing insights. Then another agent turns those insights into automated content generation. Every layer receives OPEN rewards. Technically, the ecosystem is functioning exactly as designed.
But if no company outside the system pays for those insights, then what exists is incentive-driven circulation, not necessarily value creation.
That’s why I keep coming back to what I’d call the “liquidity illusion” problem.
A marketplace can feel extremely active internally while still lacking genuine buyers.
The uncomfortable truth is that most datasets in the world never become commercially valuable. Businesses don’t pay for data because it’s large. They pay because it improves a measurable outcome better than their existing systems. Relevance matters more than raw volume.
And this is where I think OpenLedger’s long-term success will actually be decided.
Not by whether contributors upload data. Incentives can probably solve that part.
Not even by whether AI agents can operate efficiently across the ecosystem.
The real test is whether enterprises eventually spend real money consistently enough to create external demand flowing into the network instead of rewards mostly circulating inside it.
To be fair, I don’t think the team is ignoring this issue. The enterprise partnerships, API direction, Payable AI narrative, and revenue-sharing model all suggest they understand that long-term sustainability depends on outside buyers, not only contributor participation.
I also think token incentives make sense during the bootstrap phase. Almost every successful network used incentives early on to attract supply before demand fully arrived.
But bootstrap mechanisms become dangerous if the system starts optimizing for activity itself instead of useful outcomes.
Because eventually people learn how to farm incentives without creating equivalent value.
That’s why I think OpenLedger eventually needs stronger differentiation between data that generates measurable external usage and data that only generates internal activity. Not every dataset should be rewarded equally just because it exists on-chain.
In a way, the entire project feels like a very large experiment around one difficult question:
Can AI data become a real economic asset class with recurring external demand, or does tokenization simply create the appearance of liquidity before real buyers arrive?
I honestly don’t know yet.
But that’s exactly why I keep watching OpenLedger closely. Not because of hype, but because if they solve this correctly, they’re not just building another AI chain.
They’re building an actual market for machine intelligence.
And if they fail, the ecosystem may still look active for a long time before people realize most of the movement was internal all along.