
Thời gian tôi dành để đọc về OpenLedger càng nhiều, nó càng ít giống như một giao dịch kể chuyện crypto bình thường đối với tôi. Nhiều dự án được thiết kế để nắm bắt giá trị từ các thị trường đã tồn tại. OpenLedger cảm thấy khác biệt vì nó dường như đang xây dựng cho một phiên bản của nền kinh tế AI chưa thực sự hình thành.
Và tôi nghĩ rằng sự phân biệt đó quan trọng hơn những gì mọi người nhận ra.
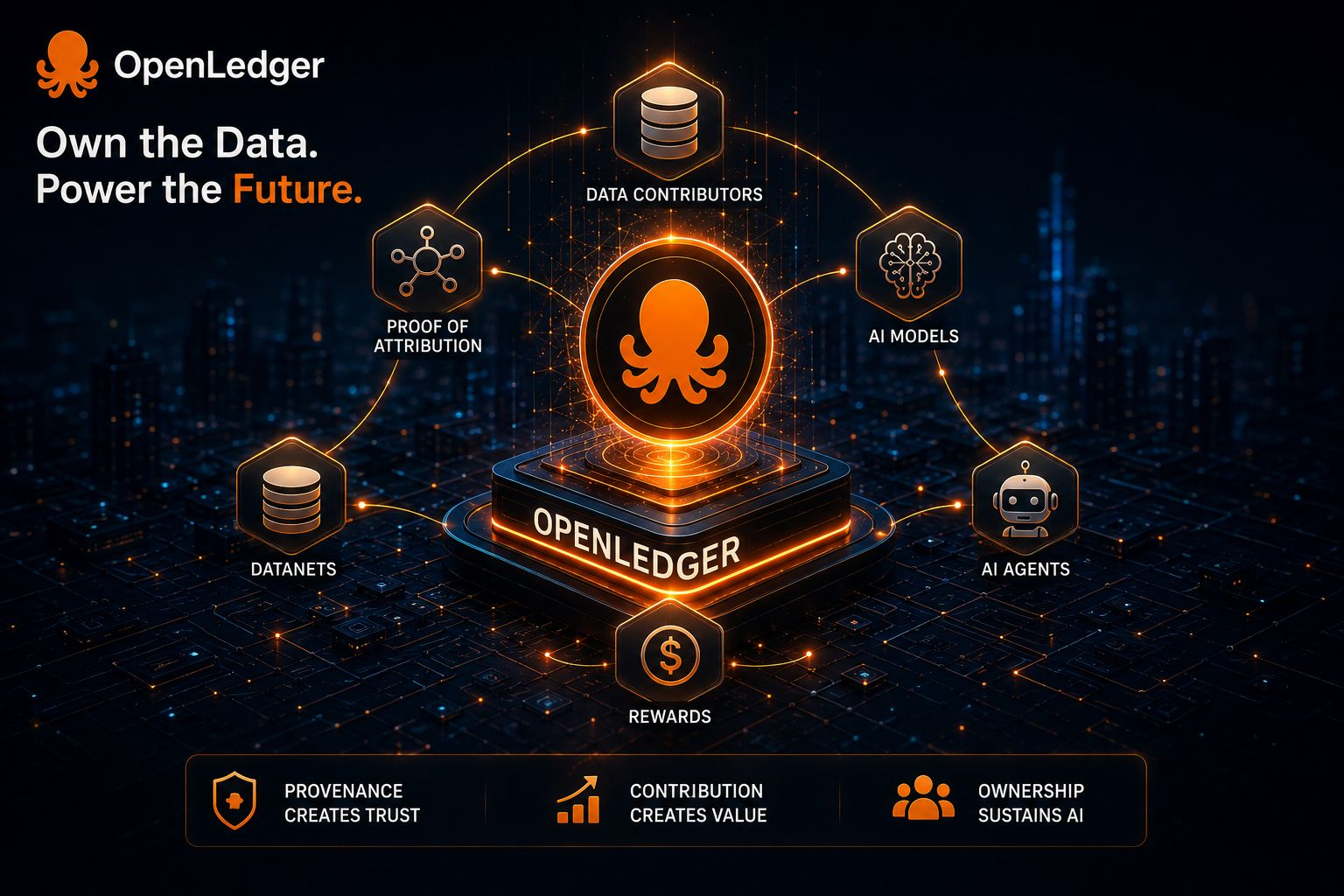
Trên bề mặt, giao thức đủ dễ hiểu. OpenLedger chạy proof of attribution trực tiếp tại lớp giao thức. Những đóng góp dữ liệu trong Datanets được theo dõi, các mô hình được đào tạo trên những bộ dữ liệu đó, và khi suy diễn diễn ra sau này, phần thưởng có thể chảy về các nhà đóng góp ban đầu, những người đã tạo ra dữ liệu định hình đầu ra. Các mô hình nhỏ hơn sử dụng các gần đúng hàm ảnh hưởng trong khi các mô hình ngôn ngữ lớn hơn dựa vào sự phù hợp token mảng suffix để truy dấu sự liên quan của đóng góp.
Cơ chế thì kỹ thuật, nhưng ý nghĩa lớn hơn thực ra khá đơn giản. OpenLedger đang cố gắng làm cho quyền sở hữu dữ liệu bên trong AI trở nên hiển thị về mặt kinh tế thay vì vô hình.
Ý tưởng đó có lẽ nghe có vẻ hiển nhiên vào lúc đầu, cho đến khi bạn ngồi lại với cách AI hiện tại hoạt động. Hầu hết các mô hình ngày nay được đào tạo trên một lượng lớn thông tin thu thập mà các nhà đóng góp không bao giờ có attribution, quyền sở hữu, hoặc sự tham gia kinh tế trong những gì những hệ thống đó cuối cùng sản xuất. Toàn bộ quy trình giả định rằng dữ liệu vào mô hình và biến mất như một tài sản có thể nhận diện sau đó.
OpenLedger thực sự đang cược rằng điều này sẽ không còn được chấp nhận theo thời gian.
Điều làm cho dự án này thú vị với tôi là nó không chỉ xây dựng công cụ. Nó xây dựng quanh một giả định tương lai. Cụ thể là ý tưởng rằng attribution cuối cùng trở nên quan trọng về mặt kinh tế đến mức cơ sở hạ tầng hỗ trợ nó trở nên quan trọng ở mức giao thức thay vì chỉ là một tính năng tùy chọn được thêm vào sau.
Tương lai đó chưa hoàn toàn tồn tại. Có lẽ đó là lý do dự án có thể cảm thấy hơi trừu tượng nếu bạn chỉ nhìn vào điều kiện thị trường hôm nay.
Ngay bây giờ, hầu hết các câu chuyện hạ tầng AI vẫn xoay quanh tính toán. Thị trường GPU, suy diễn phi tập trung, các lựa chọn đám mây, đào tạo phân phối. Những câu chuyện đó là dễ hiểu cho thị trường vì chúng khớp rõ ràng vào các mô hình hạ tầng hiện có. OpenLedger cảm thấy như nó đang hoạt động một lớp dưới cuộc trò chuyện đó.
Trọng tâm ở đây là nền kinh tế dữ liệu chính nó.
Datanets có lẽ là ví dụ rõ ràng nhất về điều này. Thay vì coi tất cả thông tin như nhiên liệu chung cho các mô hình lớn, OpenLedger tổ chức các bộ dữ liệu theo miền cụ thể thành các mạng lưới đóng góp riêng của chúng. Kiến thức y tế, pháp lý, tài chính, doanh nghiệp cụ thể. Mỗi Datanet trở thành một lớp tích lũy riêng của mình, nơi xuất xứ và chất lượng lý thuyết sẽ tích lũy theo thời gian.
Và một khi bạn suy nghĩ về điều đó đủ sâu, sự không đối xứng trở nên khó mà bỏ qua.
Một bộ dữ liệu chăm sóc sức khỏe được xác minh, xây dựng qua nhiều năm bởi các chuyên gia trong giao thức, không phải là thứ mà các đối thủ có thể nhanh chóng tái tạo. Cũng như các bộ dữ liệu pháp lý hoặc trí tuệ tài chính chuyên ngành. Hàng rào không chỉ còn là kiến trúc mô hình. Hàng rào trở thành lịch sử, xuất xứ, xác thực và mạng lưới đóng góp gắn liền với dữ liệu đó.
Điều đó thay đổi cách giá trị tích lũy qua các lớp.
Nếu lớp dữ liệu trở nên có thể phòng thủ, thì các mô hình được đào tạo trên đó sẽ thừa hưởng một phần khả năng phòng thủ đó. Các tác nhân sử dụng những mô hình đó cũng sẽ kế thừa nó. Cơ sở hạ tầng tích lũy từ bất kỳ ai kiểm soát nền kinh tế thông tin cơ bản.
Tôi nghĩ đó cũng là lý do tại sao OpenLedger chọn vị thế như một cơ sở hạ tầng thay vì chỉ một sản phẩm lớp ứng dụng. Chạy như một Ethereum L2 trên OP Stack với EigenDA xử lý khả năng dữ liệu không chỉ là thương hiệu. Các hệ thống attribution hoạt động với tần suất suy diễn sẽ trở nên không thể sử dụng về mặt kinh tế nếu không có thông lượng có thể mở rộng phía dưới chúng. Vì vậy, các lựa chọn kiến trúc cảm thấy gắn liền trực tiếp với luận điểm cốt lõi thay vì được thêm vào sau cho sự phù hợp với câu chuyện.
Điều tương tự áp dụng cho OpenCircle. Nhiều người nhìn vào các chương trình tài trợ hệ sinh thái như tiếp thị thuần túy, nhưng sáng kiến 25 triệu đô la dành cho nhà xây dựng sẽ có ý nghĩa hơn nếu bạn xem OpenLedger như một giao thức cố gắng tăng tốc sự xuất hiện của thị trường mà nó phụ thuộc vào. Nếu hạ tầng AI dựa trên attribution cuối cùng trở nên quan trọng, các nhà phát triển cần bắt đầu xây dựng trên đó trước khi nhu cầu trở nên rõ ràng.
Điều đó tạo ra một động lực kỳ lạ.
OpenLedger vừa sớm vừa phụ thuộc vào thời điểm. Nếu attribution trở nên quan trọng đủ nhanh, giao thức đã có cơ sở hạ tầng, động lực hệ sinh thái và hiệu ứng mạng phát triển trước các đối thủ cạnh tranh. Nếu thị trường di chuyển chậm hơn mong đợi, luôn có rủi ro xây dựng cơ sở hạ tầng tinh vi cho một vấn đề vẫn còn lý thuyết lâu hơn những gì các nhà đầu tư muốn chờ đợi.
Và thật lòng mà nói, tôi nghĩ rằng căng thẳng này là điều không thể tránh khỏi cho các dự án được định vị sớm xung quanh những thay đổi cấu trúc.
Hồ sơ nhà đầu tư phản ánh điều đó khá rõ ràng. Polychain Capital, Borderless Capital và Sreeram Kannan từ EigenLayer không phải là những nhà đầu tư thường chỉ theo đuổi sự hưng phấn câu chuyện ngắn hạn. Các nhà đầu tư hạ tầng thường quan tâm đến việc giao thức trở thành nền tảng nếu thị trường phát triển theo một hướng nhất định. OpenLedger cảm thấy như một kiểu cược như vậy.
Không phải là một người chiến thắng được đảm bảo. Không nhất thiết là một giao thức mà thị trường rộng lớn hơn hoàn toàn hiểu biết chưa.
Chỉ là một luận điểm rất cụ thể rằng nền kinh tế AI cuối cùng sẽ tổ chức lại xung quanh attribution, xuất xứ, và quyền sở hữu của người đóng góp thay vì coi dữ liệu như một ngoại lực miễn phí mãi mãi.
Vẫn còn nhiều câu hỏi mở rõ ràng. Liệu proof of attribution có mở rộng sạch sẽ ở tần suất suy diễn cấp sản xuất hay không vẫn là điều mà giao thức cần chứng minh theo thời gian. Liệu động lực của người đóng góp có giữ vững sau giai đoạn tăng trưởng ban đầu hay không là một vấn đề hoàn toàn khác. Và luôn có khả năng rằng các công ty AI tập trung giải quyết attribution nội bộ trước khi hạ tầng phi tập trung trở nên cần thiết.
Nhưng tôi cũng nghĩ rằng sẽ là một sai lầm nếu đọc OpenLedger chỉ như một mã thông báo câu chuyện AI khác.
Nó cảm thấy giống như một cơ sở hạ tầng được thiết kế cho một cấu trúc thị trường chưa hoàn toàn tồn tại, nhưng có thể trở nên cực kỳ quan trọng khi nền kinh tế quanh sở hữu AI trưởng thành đủ để mọi người ngừng phớt lờ nguồn gốc dữ liệu.
Và các dự án được xây dựng cho tương lai chưa đến thường trông không cần thiết cho đến lúc chúng đột nhiên trở nên quan trọng.