
CUỘC CHIẾN AI TƯƠI LAI CÓ THỂ KHÔNG CHỈ LÀ VỀ CÁC MÔ HÌNH — MÀ LÀ AI KIỂM SOÁT, XÁC THỰC, VÀ KIẾM TIỀN TỪ DỮ LIỆU
Đôi khi tôi cảm thấy hầu hết mọi người vẫn đánh giá thấp tầm quan trọng của “quyền sở hữu dữ liệu” sẽ trở nên như thế nào trong kỷ nguyên AI.
Nếu nói thật lòng, thì hầu như mọi cuộc trò chuyện vẫn xoay quanh các mô hình. Mô hình nào nhanh hơn. Mô hình nào lập luận tốt hơn. Công ty nào vừa huy động thêm một tỷ đô la. Nhưng bên dưới tất cả những tiếng ồn đó, một điều gì đó sâu sắc hơn đang âm thầm hình thành… và đó là quyền sở hữu dữ liệu. Ai thực sự tạo ra giá trị bên trong những hệ thống này?
Và thật lòng mà nói, càng nghiên cứu về @OpenLedger Datanet, tôi càng cảm thấy họ không chỉ xây dựng một câu chuyện AI + crypto khác. Họ có vẻ đang suy nghĩ lại về mối quan hệ giữa người đóng góp và hạ tầng AI chính nó.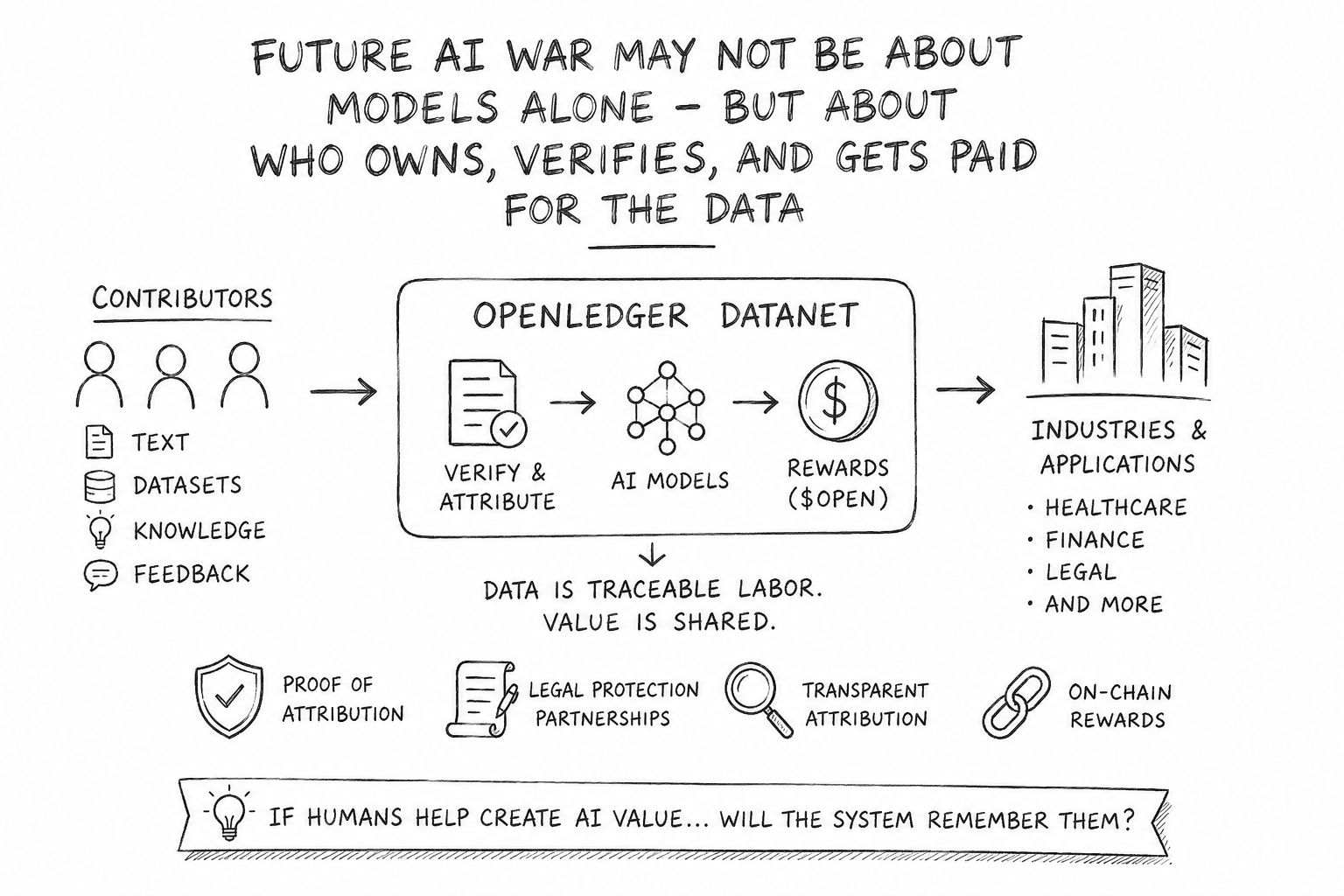
Nghe có vẻ khổng lồ. Có thể thậm chí quá khổng lồ. Và thực tế, có thể mất nhiều năm trước khi mọi người hiểu rõ liệu kiến trúc này có thể mở rộng toàn cầu không.
Vẫn... có điều gì đó khác biệt về cấu trúc đang xảy ra ở đây.
Bởi vì các hệ thống AI truyền thống hấp thụ một khối lượng lớn đóng góp của con người — văn bản, sửa chữa, chuyên môn lĩnh vực, tập dữ liệu, phản hồi củng cố — nhưng một khi các mô hình trở nên có lợi, những người đóng góp gần như biến mất khỏi phương trình giá trị.
Hệ thống nhớ dữ liệu.
Nền kinh tế quên đi con người đứng sau nó.
Sự mất cân bằng đó đã tồn tại trong nhiều năm.
Và thật lòng mà nói, đây là nơi ý tưởng "AI có thể thanh toán" của OpenLedger bắt đầu trở nên thú vị với tôi. Không phải vì thương hiệu. Crypto tạo ra các câu chuyện mới mỗi tuần. Nhưng sau khi MAINNET OPEN được ra mắt, cuộc thảo luận đã chuyển từ lý thuyết sang cơ chế kinh tế thực tế.
Giờ đây, lớp đóng góp Datanet không chỉ là một khái niệm lộ trình nữa. Người đóng góp có thể gửi tập dữ liệu, các nhà phát triển có thể đào tạo các mô hình chuyên biệt trên đó, và các hợp đồng thông minh phân phối $OPEN phần thưởng trực tiếp trên chuỗi.
Điều đó thay đổi tâm lý tham gia.
Đột nhiên, dữ liệu không còn chỉ là nhiên liệu.
Nó bắt đầu trở thành lao động có thể đo lường.
Và tôi nghĩ rằng sự khác biệt đó quan trọng hơn nhiều so với hầu hết mọi người nhận ra.
Đặc biệt sau khi nhìn sâu vào động cơ Proof of Attribution đã được nâng cấp. Cơ chế phân phối gradient của mô hình nhỏ hơn có vẻ hợp lý. Nếu việc loại bỏ một điểm dữ liệu làm suy yếu hiệu suất mô hình một cách rõ rệt, thì rõ ràng điểm dữ liệu đó mang giá trị đo lường được.
Nhưng phần thú vị hơn có thể là hệ thống phân phối quyền sở hữu dựa trên Suffix-Array cho LLMs.
Bởi vì việc theo dõi đóng góp trong các mô hình ngôn ngữ lớn luôn rất mờ mịt.
Đầu ra là tập thể.
Mờ nhòe.
Gần như không thể truy tìm một cách rõ ràng.
Vì vậy, việc cố gắng ánh xạ các token được tạo ra trở lại ảnh hưởng của tập dữ liệu đào tạo thực sự là một thách thức cơ sở hạ tầng khổng lồ.
Và có thể nó sẽ không bao giờ trở nên hoàn hảo về mặt toán học.
Thật lòng mà nói, tôi nghi ngờ quyền sở hữu có thể bao giờ hoàn toàn thuần khiết ở quy mô lớn.
Nhưng ngay cả việc cố gắng xây dựng một lớp xác thực minh bạch cũng cảm thấy như một sự thay đổi lớn về hướng đi từ nơi ngành công nghiệp đã di chuyển.
Hầu hết các hệ thống tối ưu hóa khai thác trước.
OpenLedger ít nhất có vẻ đang tối ưu hóa trách nhiệm — hoặc đang tiến gần hơn đến nó.
Và có một phần khác tôi cứ suy nghĩ mãi...
Các quan hệ đối tác về nguồn dữ liệu và bảo vệ pháp lý — đặc biệt là các tích hợp như Story Protocol — có thể cuối cùng trở thành một trong những lớp quan trọng nhất của toàn bộ hệ sinh thái.
Bởi vì khi AI bước vào các ngành công nghiệp thương mại quy mô lớn, các tập dữ liệu được xác minh hợp pháp có thể trở nên có giá trị hơn cả trí tuệ thô.
Ngay bây giờ, mọi người đều nói về khả năng của mô hình.
Nhưng cuối cùng các doanh nghiệp có thể bắt đầu đặt ra những câu hỏi khác:
Liệu tập dữ liệu này có thể được xác thực không?
Có giấy phép không?
Có được ghi nhận đúng không?
Có được bảo vệ pháp lý không?
Và điều đó có thể hoàn toàn định hình lại kinh tế của AI trong các lĩnh vực như chăm sóc sức khỏe, tài chính và hạ tầng pháp lý.
Nhìn vào lộ trình của OpenLedger, họ ít nhất có vẻ nhận thức được hướng đi này đang đi đến đâu.
Cấu trúc Datanet chuyên biệt có vẻ rất có chủ đích. Không cố gắng trở thành "hạ tầng AI cho mọi thứ" chỉ để tiếp thị.
Thật lòng mà nói, điều đó cảm thấy mới mẻ trong một thị trường mà nhiều dự án vẫn dựa vào những câu chuyện cực kỳ rộng lớn.
Cùng lúc đó...
Tôi không nghĩ rằng con đường này sẽ trở nên dễ dàng từ đây.
Bởi vì bất cứ nơi nào có động lực thực sự, sự thao túng sẽ theo sau.
Lạm dụng bảng xếp hạng.
Tập dữ liệu tổng hợp chất lượng thấp.
Nông trại spam.
Xung đột về quyền sở hữu.
Những áp lực này là không thể tránh khỏi.
Vì vậy, thách thức thực sự có thể bắt đầu từ bây giờ sau mainnet.
Liệu các hệ thống xác thực có giữ vững trong thời gian áp dụng quy mô lớn không?
Liệu quyền sở hữu có còn đáng tin cậy trong hàng triệu tương tác không?
Liệu các động lực cho người đóng góp có còn phù hợp sau nhiều năm không?
Thật lòng...
Tôi không hoàn toàn chắc chắn.
Nhưng có thể sự không chắc chắn đó chính là lý do tại sao giai đoạn này lại quan trọng.
Bởi vì sau một thời gian dài, một dự án crypto AI đang nổi lên không chỉ nói về các tiêu chuẩn mô hình hay sự thổi phồng đầu cơ.
Họ đang cố gắng trả lời một câu hỏi khó chịu hơn nhiều:
"Nếu con người giúp tạo ra giá trị AI... liệu hệ thống có nhớ họ không?"
Và thật lòng mà nói, tôi nghĩ toàn bộ ngành công nghiệp cuối cùng sẽ phải đối mặt với câu hỏi đó.
OpenLedger có thể chưa có mọi câu trả lời.
Nhưng có vẻ như đây là một trong những dự án hiếm hoi thực sự cố gắng xây dựng cơ sở hạ tầng xung quanh vấn đề thay vì phớt lờ nó.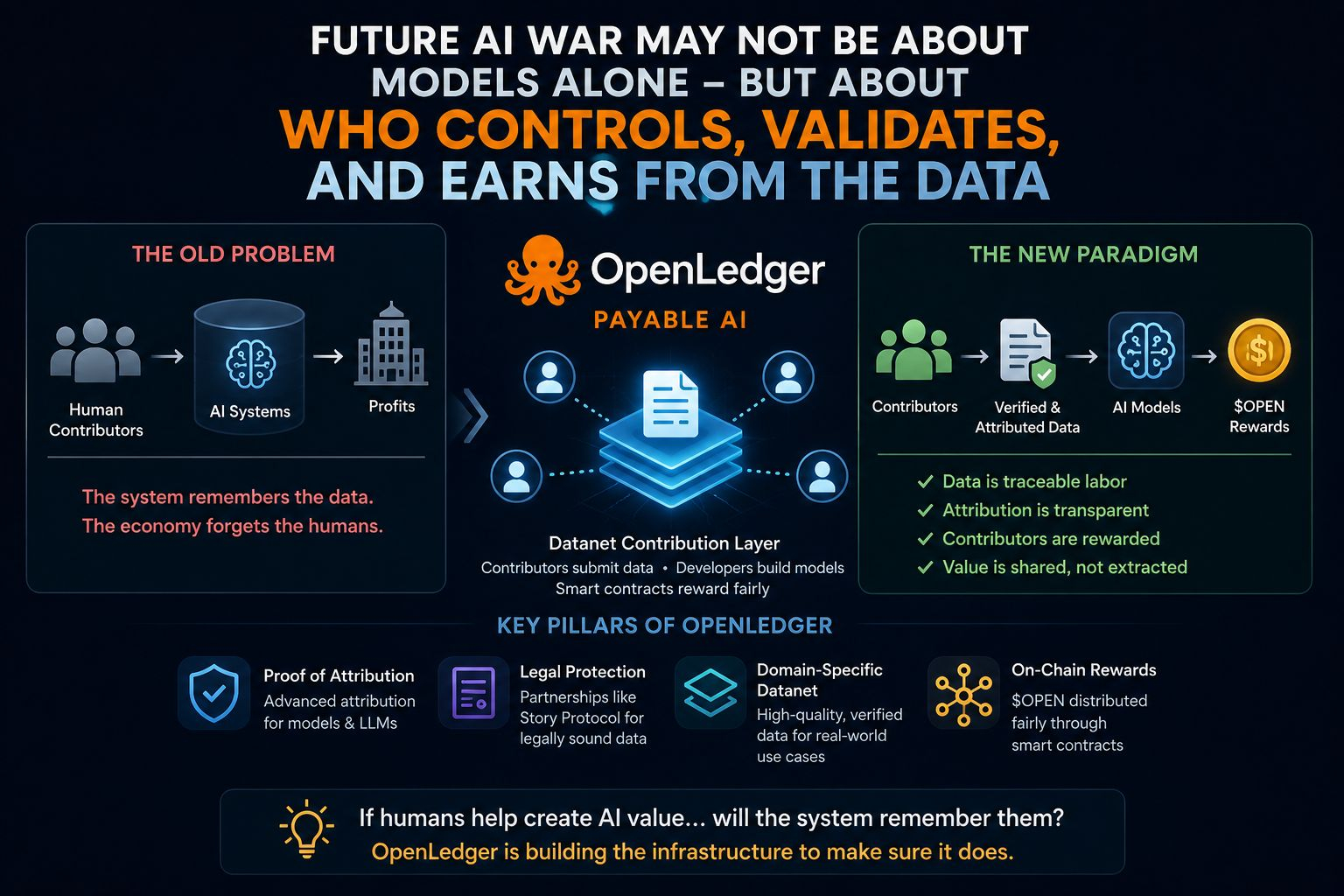
Dù sao đi nữa... hãy xem.