
Các mô hình AI nhận được phần lớn sự chú ý. Những mô hình lớn hơn. Đầu ra thông minh hơn. Phản hồi nhanh hơn.
Nhưng có một vấn đề êm đềm bên dưới tất cả: chất lượng dữ liệu.
AI chỉ hữu ích bằng thông tin mà nó học từ đó. Và hôm nay, phần lớn dữ liệu đó nằm trong các hệ thống khép kín do một số nền tảng nhỏ kiểm soát. Khi nội dung do AI tạo ra tràn ngập internet, việc tìm kiếm dữ liệu đáng tin cậy, chuyên biệt và chất lượng cao trở nên khó khăn hơn, không dễ dàng hơn.
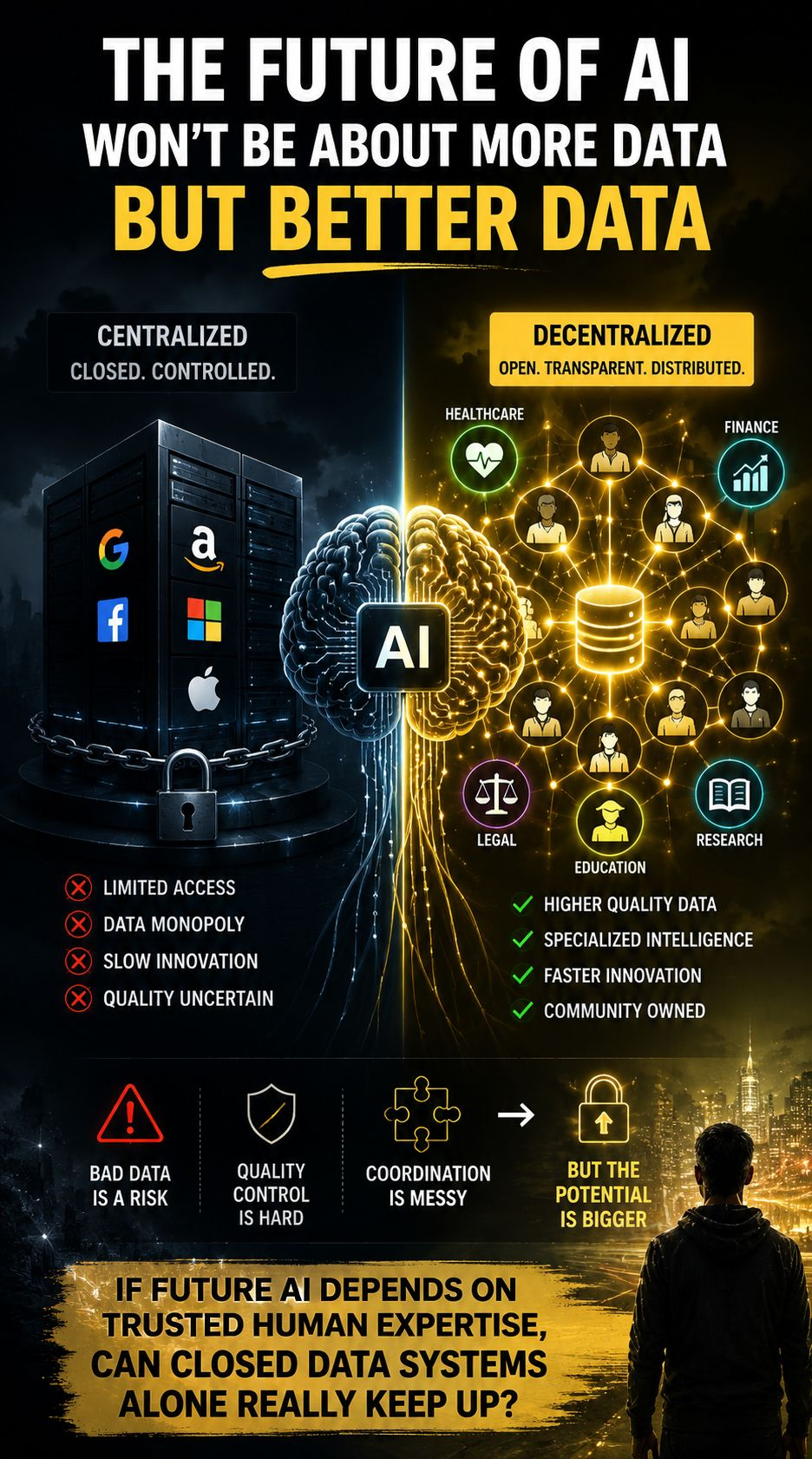
Đó là lý do tại sao dữ liệu AI phi tập trung lại quan trọng.
Lập luận rất đơn giản: AI tương lai có thể không thắng nhờ nhiều dữ liệu hơn, mà nhờ dữ liệu tốt hơn.
Một AI trong lĩnh vực chăm sóc sức khỏe không thể dựa vào nội dung ngẫu nhiên trên internet. Một mô hình tài chính cần cái nhìn thị trường chính xác. AI pháp lý phụ thuộc vào chuyên môn đáng tin cậy. Trí tuệ chuyên biệt đòi hỏi bộ dữ liệu chuyên biệt.
Các hệ thống dữ liệu phi tập trung cố gắng giải quyết điều này bằng cách làm cho việc đóng góp trở nên mở, minh bạch và phân tán thay vì phụ thuộc hoàn toàn vào các đường ống tập trung.
Ý nghĩa lớn hơn thường bị bỏ qua: nếu kiến thức con người chất lượng cao trở thành đầu vào quý giá nhất cho AI, thì các hệ thống thu thập và tổ chức trí tuệ đó có thể quan trọng không kém gì các mô hình tự nó.
Chắc chắn rồi, việc phi tập trung tạo ra những thách thức. Kiểm soát chất lượng gặp khó khăn, phối hợp thì lộn xộn, và dữ liệu xấu vẫn luôn là một rủi ro.
Tuy nhiên, một câu hỏi vẫn ngày càng to hơn:
Nếu AI trong tương lai phụ thuộc vào chuyên môn con người đáng tin cậy, liệu các hệ thống dữ liệu đóng kín có thực sự theo kịp không?
