
The more I think about where AI adoption is heading, the more it feels like the first major wave already happened. We solved the access problem faster than most people expected. Models became easier to use, APIs became cheap, open-source tooling exploded, and suddenly almost anyone could add an AI layer to a product without needing a dedicated machine learning team.
That phase was mostly about capability.
The next phase feels different. It feels like it’s going to be about accountability.
And honestly, I think that shift changes which infrastructure actually matters.
Right now most AI systems still operate in relatively low-stakes environments. If a chatbot hallucinates inside a customer support flow, it’s annoying but manageable. But once AI starts moving deeper into legal workflows, medical systems, enterprise operations, financial underwriting, or compliance-heavy industries, the conversation changes completely. At that point the question is no longer “can the model generate a useful answer?”
It becomes:
Where did this output come from?
What data shaped it?
Can we verify the provenance?
Who is responsible if the output is wrong?
That’s the part that made OpenLedger start feeling more important to me over time.
At first glance it looks like another AI infrastructure protocol inside the broader crypto narrative. But the more I read about the actual architecture, the more it feels like OpenLedger is building specifically for this second wave rather than the first one.
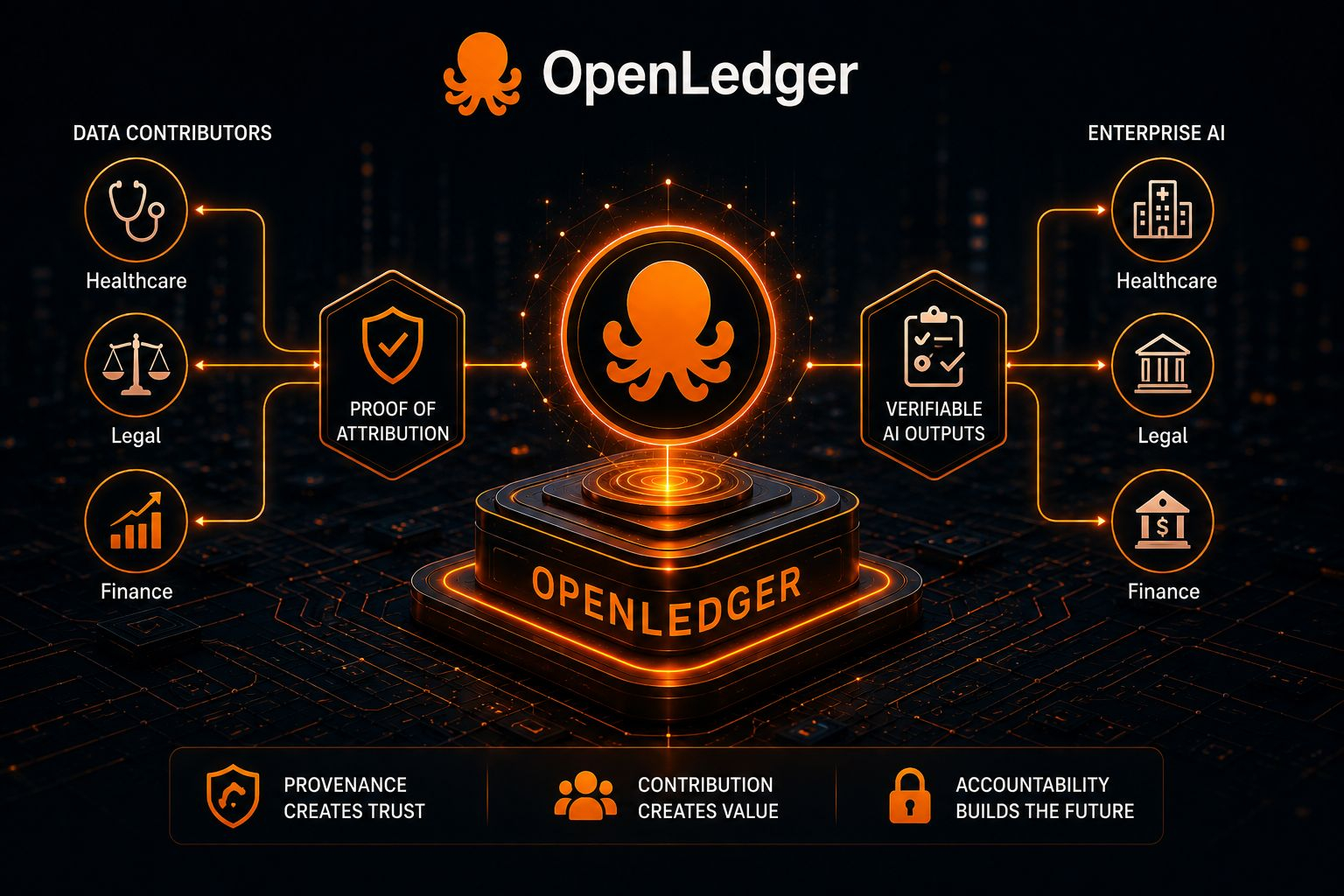
The core mechanism is Proof of Attribution. Instead of treating training data as an invisible input that disappears once the model is deployed, OpenLedger keeps the relationship between data and model outputs traceable. Datasets inside Datanets carry provenance tracked on-chain, and inference events can theoretically route rewards back toward the contributors whose data influenced the output.
For smaller models the system uses influence function approximations. Larger language models rely on suffix-array token matching to determine attribution relevance. The technical side is obviously complicated, but the underlying idea is surprisingly straightforward. OpenLedger is trying to make the data layer of AI auditable after the fact.
And I think that’s a much bigger deal than most people realize.
Because accountability infrastructure behaves differently from normal infrastructure. Its value increases as the consequences of AI decisions become more serious.
Most AI infrastructure projects today are competing around efficiency. Faster inference, cheaper compute, decentralized GPU markets, optimized routing layers. OpenLedger is operating in a different category entirely. It’s building infrastructure around trust, provenance, and verifiability.
That distinction matters a lot if enterprise adoption becomes the next major growth phase for AI.
A hospital deploying AI-assisted diagnostics cannot rely on “trust us, the model is good.” A legal platform using AI for document analysis eventually needs explainability around the data shaping those outputs. Financial systems dealing with credit or risk scoring increasingly face regulatory pressure around transparency and auditability.
In those environments, provenance stops being optional.
And this is where Datanets become especially interesting to me.
The way OpenLedger structures domain-specific datasets around verticals like healthcare, finance, and legal services creates something more defensible than generic scraped data pools. These aren’t just collections of information. They’re provenance-verified data supply chains where contribution history, validation, and ownership remain visible over time.
A mature medical Datanet built over several years by verified contributors has a completely different profile from an anonymous internet-scale dataset. Not necessarily because the model is larger or smarter, but because the underlying data infrastructure is auditable.
That creates a second-order effect most people probably overlook.
As enterprises start prioritizing attribution and compliance, the value of curated domain-specific datasets compounds. And contributors who helped build those Datanets early occupy a structural position later participants cannot replicate easily. Provenance is timestamped. Contribution history becomes part of the network itself. Network effects emerge at the data layer instead of only the application layer.
I also think OpenLedger’s infrastructure choices make more sense once you view the protocol through this lens.
Running as an Ethereum L2 using the OP Stack with EigenDA for data availability isn’t just about scalability marketing. Attribution systems operating at inference-level frequency generate massive recording requirements. Without cheap throughput and efficient data availability, the economics break down quickly. So the architecture feels tied directly to the protocol’s long-term thesis.
Even EVM compatibility matters more than people think. Enterprises and developers already understand Ethereum tooling, compliance frameworks, and security assumptions better than entirely new architectures. Familiar infrastructure lowers friction when adoption eventually matters.
Still, I don’t think any of this guarantees success.
The timing question remains huge.
Enterprise AI adoption in regulated industries is still slower than crypto people usually expect. Procurement cycles are long. Legal frameworks around AI accountability are still evolving. And there’s always the possibility that centralized AI providers solve attribution internally before decentralized attribution layers become standard infrastructure.
That’s probably the real competitive question hanging over OpenLedger.
Does the market eventually want open, protocol-level attribution systems?
Or does accountability get absorbed into closed enterprise platforms companies already trust?
I don’t think anyone fully knows yet.
But I do think OpenLedger is one of the few AI crypto projects that feels like it’s genuinely building for where the market might go next instead of optimizing purely for where attention already is today.
And if the next phase of AI adoption really becomes less about raw capability and more about accountability, provenance, and verifiable ownership, then protocols positioned at that layer might end up mattering far more than the market currently prices in.
Still early obviously. But the deeper I look into OpenLedger, the less it feels like a short-term AI narrative and the more it feels like infrastructure waiting for a specific market condition to arrive.